
避免线性回归的过拟合(二):线性回归的改进避免线性回归的过拟合(二):线性回归的改进——岭回归(附波士顿房价预测案例源代岭回归(附波士顿房价预测案例源代
码)码)
线性回归的改进线性回归的改进-岭回归岭回归
文章源代码下载地址:波士顿房价岭回归正则化预测代码实现
文章目录文章目录线性回归的改进-岭回归1.API2.观察正则化程度的变化,对结果的影响?3.波士顿房价正则化预测代码4.结果
1.API
sklearn.linear_model.Ridge(alpha=1.0, fit_intercept=True,solver=“auto”, normalize=False)
具有l2正则化的线性回归
alpha:正则化力度,也叫 λ
λ取值:取值:0~1 1~10
solver:会根据数据自动选择优化方法
sag:如果数据集、特征都比较大,选择该随机梯度下降优化如果数据集、特征都比较大,选择该随机梯度下降优化
normalize:数据是否进行标准化
normalize=False:可以在fit之前调用preprocessing.StandardScaler标准化数据
Ridge.coef_:回归权重
Ridge.intercept_:回归偏置
Ridge方法相当于方法相当于SGDRegressor(penalty=‘l2’, loss=“squared_loss”),只不过只不过SGDRegressor实现了一个普通的随机梯度下降学习,推荐使用实现了一个普通的随机梯度下降学习,推荐使用Ridge(实现了实现了SAG)
sklearn.linear_model.RidgeCV(_BaseRidgeCV, RegressorMixin)
具有l2正则化的线性回归,可以进行交叉验证
coef_:回归系数
class _BaseRidgeCV(LinearModel):
def __init__(self, alphas=(0.1, 1.0, 10.0),
fit_intercept=True, normalize=False,scoring=None,
cv=None, gcv_mode=None,
store_cv_values=False):
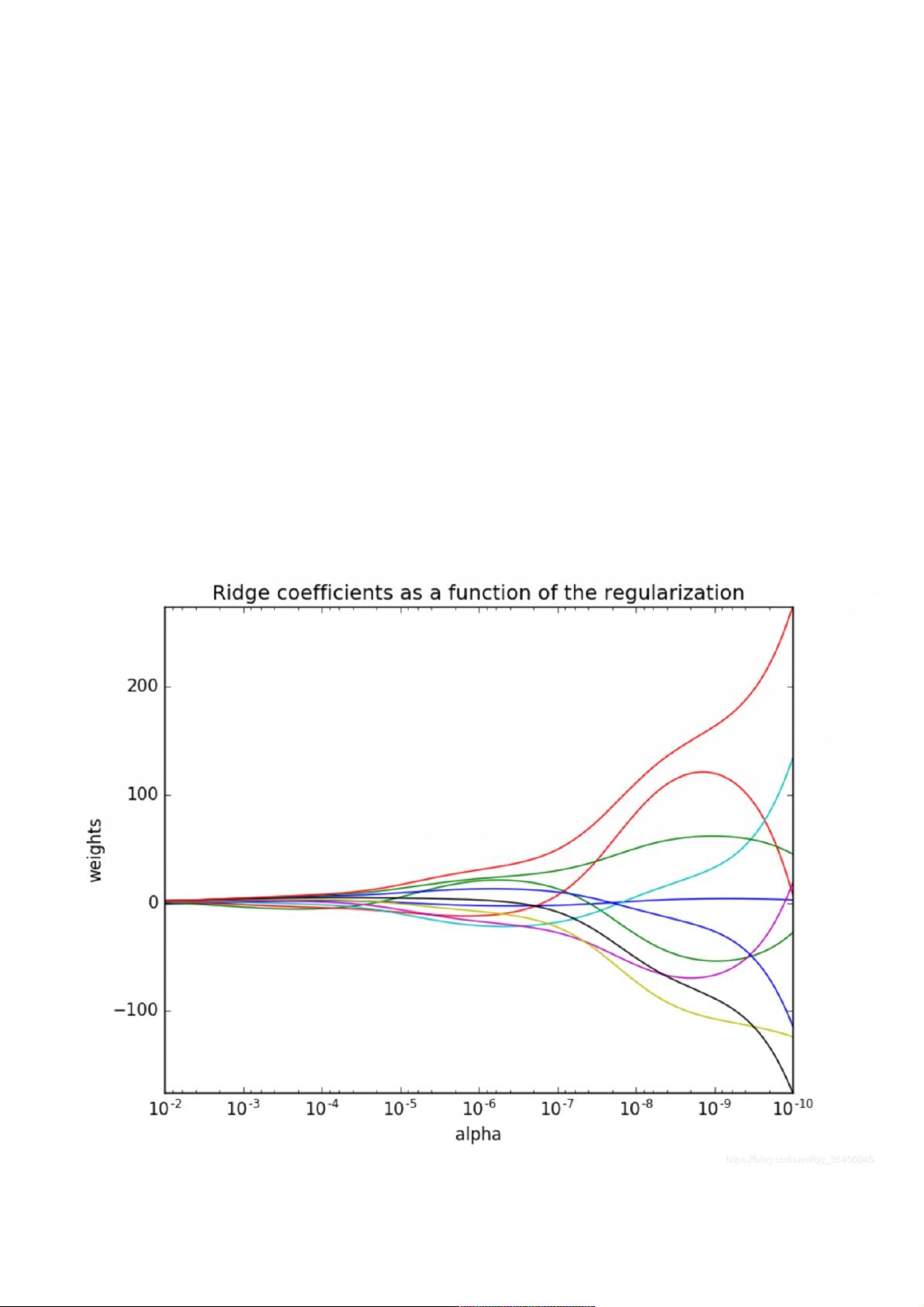
2.观察正则化程度的变化,对结果的影响?观察正则化程度的变化,对结果的影响?
正则化力度越大力度越大,权重系数会越小(聚集在0附近了)
正则化力度越小,权重系数会越大
3.波士顿房价正则化预测代码波士顿房价正则化预测代码
#要用到的包
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split

weixin_38652058
- 粉丝: 9
- 资源: 901
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- zigbee-cluster-library-specification
- JSBSim Reference Manual
- c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
- 建筑供配电系统相关课件.pptx
- 企业管理规章制度及管理模式.doc
- vb打开摄像头.doc
- 云计算-可信计算中认证协议改进方案.pdf
- [详细完整版]单片机编程4.ppt
- c语言常用算法.pdf
- c++经典程序代码大全.pdf
- 单片机数字时钟资料.doc
- 11项目管理前沿1.0.pptx
- 基于ssm的“魅力”繁峙宣传网站的设计与实现论文.doc
- 智慧交通综合解决方案.pptx
- 建筑防潮设计-PowerPointPresentati.pptx
- SPC统计过程控制程序.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0