

1
Squeeze-and-Excitation Networks
Jie Hu
[0000−0002−5150−1003]
Li Shen
[0000−0002−2283−4976]
Samuel Albanie
[0000−0001−9736−5134]
Gang Sun
[0000−0001−6913−6799]
Enhua Wu
[0000−0002−2174−1428]
Abstract—The central building block of convolutional neural networks (CNNs) is the convolution operator, which enables networks to
construct informative features by fusing both spatial and channel-wise information within local receptive fields at each layer. A broad
range of prior research has investigated the spatial component of this relationship, seeking to strengthen the representational power of
a CNN by enhancing the quality of spatial encodings throughout its feature hierarchy. In this work, we focus instead on the channel
relationship and propose a novel architectural unit, which we term the “Squeeze-and-Excitation” (SE) block, that adaptively recalibrates
channel-wise feature responses by explicitly modelling interdependencies between channels. We show that these blocks can be
stacked together to form SENet architectures that generalise extremely effectively across different datasets. We further demonstrate
that SE blocks bring significant improvements in performance for existing state-of-the-art CNNs at slight additional computational cost.
Squeeze-and-Excitation Networks formed the foundation of our ILSVRC 2017 classification submission which won first place and
reduced the top-5 error to 2.251%, surpassing the winning entry of 2016 by a relative improvement of ∼25%. Models and code are
available at https://github.com/hujie-frank/SENet.
Index Terms—Squeeze-and-Excitation, Image representations, Attention, Convolutional Neural Networks.
F
1 INTRODUCTION
C
ONVOLUTIONAL neural networks (CNNs) have proven
to be useful models for tackling a wide range of visual
tasks [1], [2], [3], [4]. At each convolutional layer in the net-
work, a collection of filters expresses neighbourhood spatial
connectivity patterns along input channels—fusing spatial
and channel-wise information together within local recep-
tive fields. By interleaving a series of convolutional layers
with non-linear activation functions and downsampling op-
erators, CNNs are able to produce image representations
that capture hierarchical patterns and attain global theo-
retical receptive fields. A central theme of computer vision
research is the search for more powerful representations that
capture only those properties of an image that are most
salient for a given task, enabling improved performance.
As a widely-used family of models for vision tasks, the
development of new neural network architecture designs
now represents a key frontier in this search. Recent research
has shown that the representations produced by CNNs can
be strengthened by integrating learning mechanisms into
the network that help capture spatial correlations between
features. One such approach, popularised by the Inception
family of architectures [5], [6], incorporates multi-scale pro-
cesses into network modules to achieve improved perfor-
• Jie Hu and Enhua Wu are with the State Key Laboratory of Computer
Science, Institute of Software, Chinese Academy of Sciences, Beijing,
100190, China.
They are also with the University of Chinese Academy of Sciences, Beijing,
100049, China.
Jie Hu is also with Momenta and Enhua Wu is also with the Faculty of
Science and Technology & AI Center at University of Macau.
E-mail: hujie@ios.ac.cn ehwu@umac.mo
• Gang Sun is with LIAMA-NLPR at the Institute of Automation, Chinese
Academy of Sciences. He is also with Momenta.
E-mail: sungang@momenta.ai
• Li Shen and Samuel Albanie are with the Visual Geometry Group at the
University of Oxford.
E-mail: {lishen,albanie}@robots.ox.ac.uk
mance. Further work has sought to better model spatial
dependencies [7], [8] and incorporate spatial attention into
the structure of the network [9].
In this paper, we investigate a different aspect of network
design - the relationship between channels. We introduce
a new architectural unit, which we term the Squeeze-and-
Excitation (SE) block, with the goal of improving the quality
of representations produced by a network by explicitly mod-
elling the interdependencies between the channels of its con-
volutional features. To this end, we propose a mechanism
that allows the network to perform feature recalibration,
through which it can learn to use global information to
selectively emphasise informative features and suppress less
useful ones.
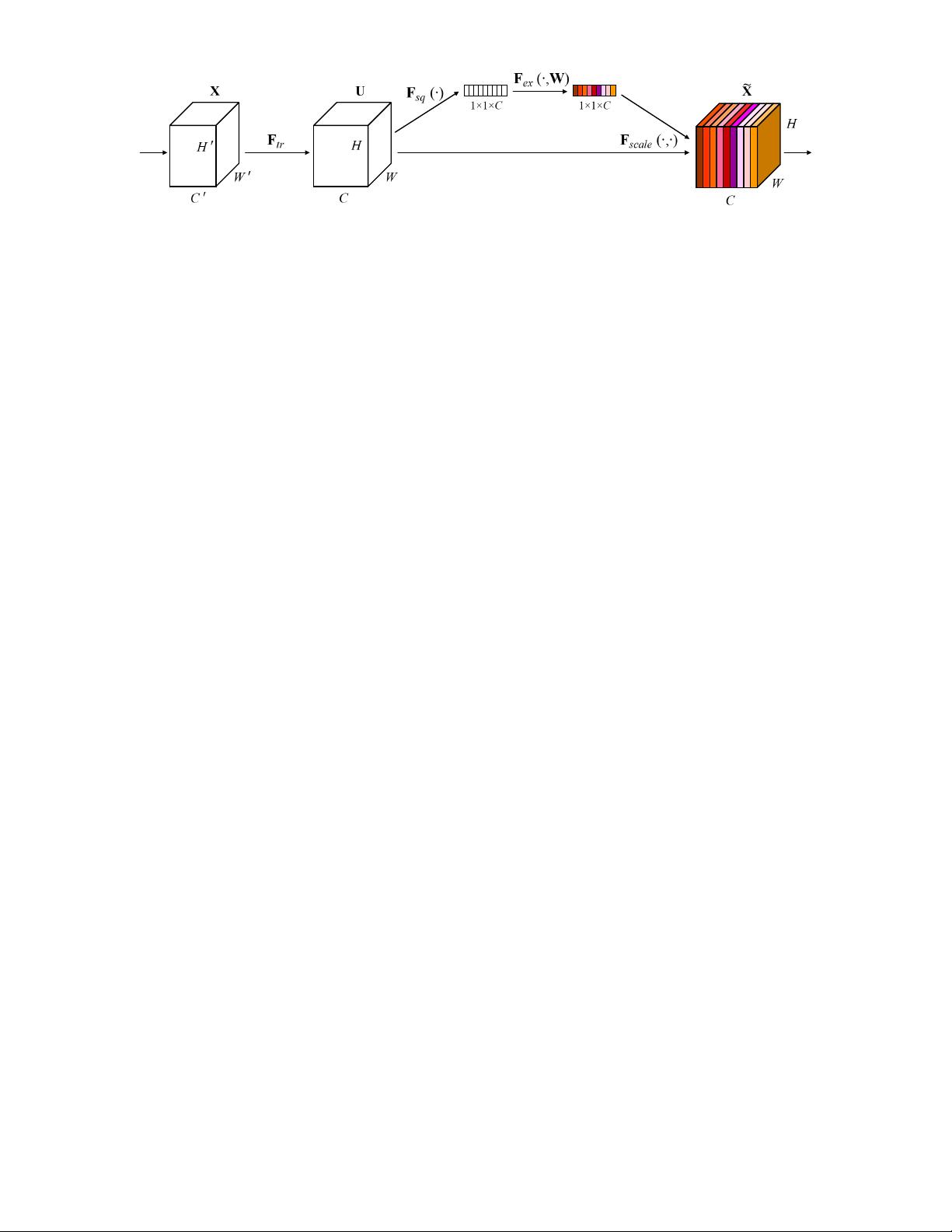
The structure of the SE building block is depicted in
Fig. 1. For any given transformation F
tr
mapping the
input X to the feature maps U where U ∈ R
H×W ×C
,
e.g. a convolution, we can construct a corresponding SE
block to perform feature recalibration. The features U are
first passed through a squeeze operation, which produces a
channel descriptor by aggregating feature maps across their
spatial dimensions (H × W ). The function of this descriptor
is to produce an embedding of the global distribution of
channel-wise feature responses, allowing information from
the global receptive field of the network to be used by
all its layers. The aggregation is followed by an excitation
operation, which takes the form of a simple self-gating
mechanism that takes the embedding as input and pro-
duces a collection of per-channel modulation weights. These
weights are applied to the feature maps U to generate
the output of the SE block which can be fed directly into
subsequent layers of the network.
It is possible to construct an SE network (SENet) by
simply stacking a collection of SE blocks. Moreover, these
SE blocks can also be used as a drop-in replacement for the
original block at a range of depths in the network architec-
arXiv:1709.01507v4 [cs.CV] 16 May 2019

剩余12页未读,继续阅读

颐水风华
- 粉丝: 9840
- 资源: 15
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- 利用迪杰斯特拉算法的全国交通咨询系统设计与实现
- 全国交通咨询系统C++实现源码解析
- DFT与FFT应用:信号频谱分析实验
- MATLAB图论算法实现:最小费用最大流
- MATLAB常用命令完全指南
- 共创智慧灯杆数据运营公司——抢占5G市场
- 中山农情统计分析系统项目实施与管理策略
- XX省中小学智慧校园建设实施方案
- 中山农情统计分析系统项目实施方案
- MATLAB函数详解:从Text到Size的实用指南
- 考虑速度与加速度限制的工业机器人轨迹规划与实时补偿算法
- Matlab进行统计回归分析:从单因素到双因素方差分析
- 智慧灯杆数据运营公司策划书:抢占5G市场,打造智慧城市新载体
- Photoshop基础与色彩知识:信息时代的PS认证考试全攻略
- Photoshop技能测试:核心概念与操作
- Photoshop试题与答案详解
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


