

Unpaired Image-to-Image Translation
using Cycle-Consistent Adversarial Networks
Jun-Yan Zhu
∗
Taesung Park
∗
Phillip Isola Alexei A. Efros
Berkeley AI Research (BAIR) laboratory, UC Berkeley
Zebras Horses
horse zebra
zebra horse
Summer Winter
summer winter
winter summer
Photograph Van Gogh CezanneMonet Ukiyo-e
Monet Photos
Monet photo
photo Monet
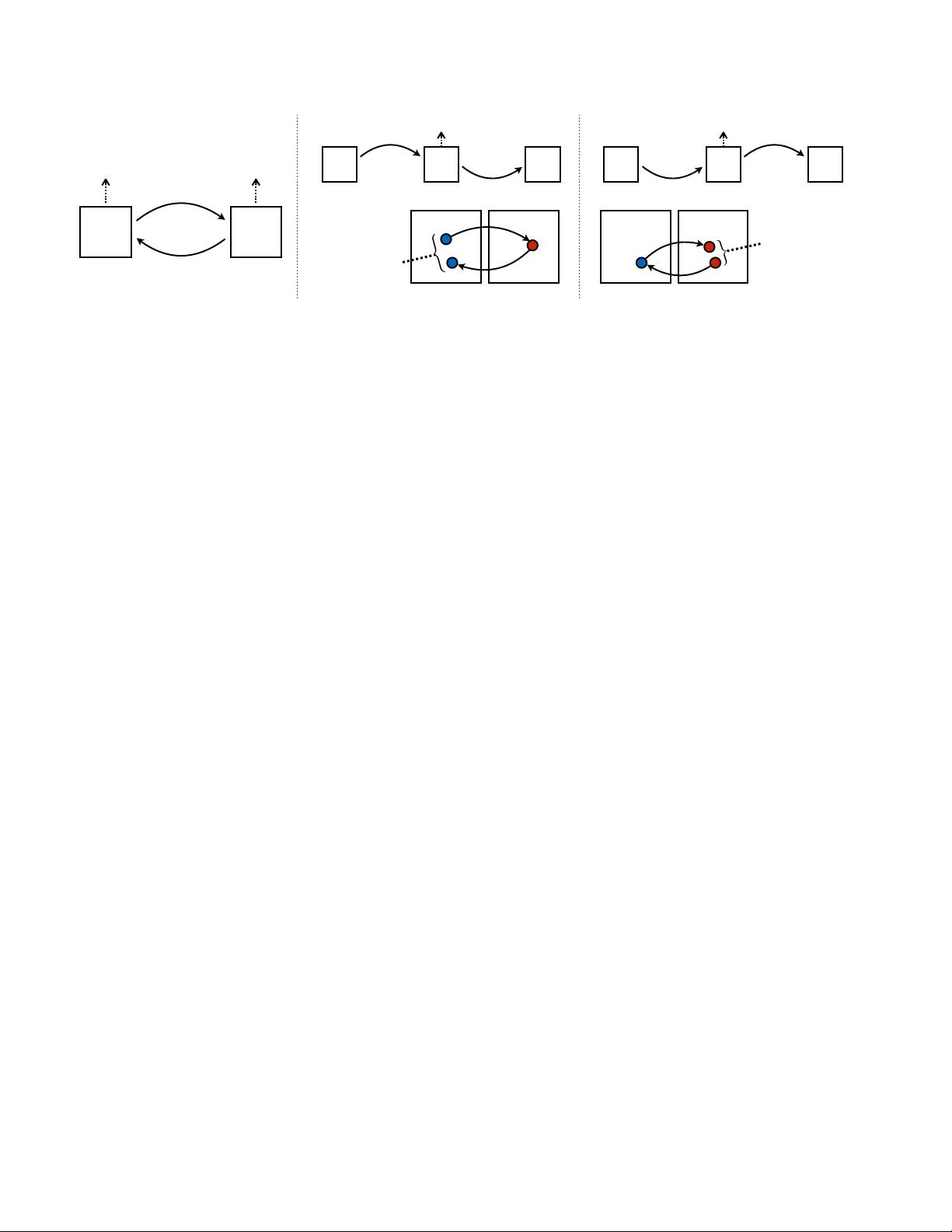
Figure 1: Given any two unordered image collections X and Y , our algorithm learns to automatically “translate” an image
from one into the other and vice versa: (left) Monet paintings and landscape photos from Flickr; (center) zebras and horses
from ImageNet; (right) summer and winter Yosemite photos from Flickr. Example application (bottom): using a collection
of paintings of famous artists, our method learns to render natural photographs into the respective styles.
Abstract
Image-to-image translation is a class of vision and
graphics problems where the goal is to learn the mapping
between an input image and an output image using a train-
ing set of aligned image pairs. However, for many tasks,
paired training data will not be available. We present an
approach for learning to translate an image from a source
domain X to a target domain Y in the absence of paired
examples. Our goal is to learn a mapping G : X → Y
such that the distribution of images from G(X) is indistin-
guishable from the distribution Y using an adversarial loss.
Because this mapping is highly under-constrained, we cou-
ple it with an inverse mapping F : Y → X and introduce a
cycle consistency loss to enforce F (G(X)) ≈ X (and vice
versa). Qualitative results are presented on several tasks
where paired training data does not exist, including collec-
tion style transfer, object transfiguration, season transfer,
photo enhancement, etc. Quantitative comparisons against
several prior methods demonstrate the superiority of our
approach.
1. Introduction
What did Claude Monet see as he placed his easel by the
bank of the Seine near Argenteuil on a lovely spring day
in 1873 (Figure 1, top-left)? A color photograph, had it
been invented, may have documented a crisp blue sky and
a glassy river reflecting it. Monet conveyed his impression
of this same scene through wispy brush strokes and a bright
palette.
What if Monet had happened upon the little harbor in
Cassis on a cool summer evening (Figure 1, bottom-left)?
A brief stroll through a gallery of Monet paintings makes it
possible to imagine how he would have rendered the scene:
perhaps in pastel shades, with abrupt dabs of paint, and a
somewhat flattened dynamic range.
We can imagine all this despite never having seen a side
by side example of a Monet painting next to a photo of the
scene he painted. Instead, we have knowledge of the set of
Monet paintings and of the set of landscape photographs.
We can reason about the stylistic differences between these
* indicates equal contribution
1
arXiv:1703.10593v6 [cs.CV] 15 Nov 2018


剩余17页未读,继续阅读

weixin_41999309
- 粉丝: 0
- 资源: 1
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- zigbee-cluster-library-specification
- JSBSim Reference Manual
- c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
- 建筑供配电系统相关课件.pptx
- 企业管理规章制度及管理模式.doc
- vb打开摄像头.doc
- 云计算-可信计算中认证协议改进方案.pdf
- [详细完整版]单片机编程4.ppt
- c语言常用算法.pdf
- c++经典程序代码大全.pdf
- 单片机数字时钟资料.doc
- 11项目管理前沿1.0.pptx
- 基于ssm的“魅力”繁峙宣传网站的设计与实现论文.doc
- 智慧交通综合解决方案.pptx
- 建筑防潮设计-PowerPointPresentati.pptx
- SPC统计过程控制程序.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0