

Journal of Data Analysis and Information Processing, 2017, 5, 115-130
http://www.scirp.org/journal/jdaip
ISSN Online: 2327-7203
ISSN Print: 2327-7211
DOI: 10.4236/jdaip.2017.53009
August 29, 2017
Time Series Forecasting with Multiple Deep
Learners: Selection from a Bayesian Network
Shusuke Kobayashi, Susumu Shirayama
Graduate School of Engineering, the University of Tokyo, Tokyo, Japan
Abstract
Considering the recent developments in deep learning, it has become incre
a-
singly important to verify what methods are valid for the prediction of mult
i-
variate time-series data. In this study, we propose a novel method of time-se
ries
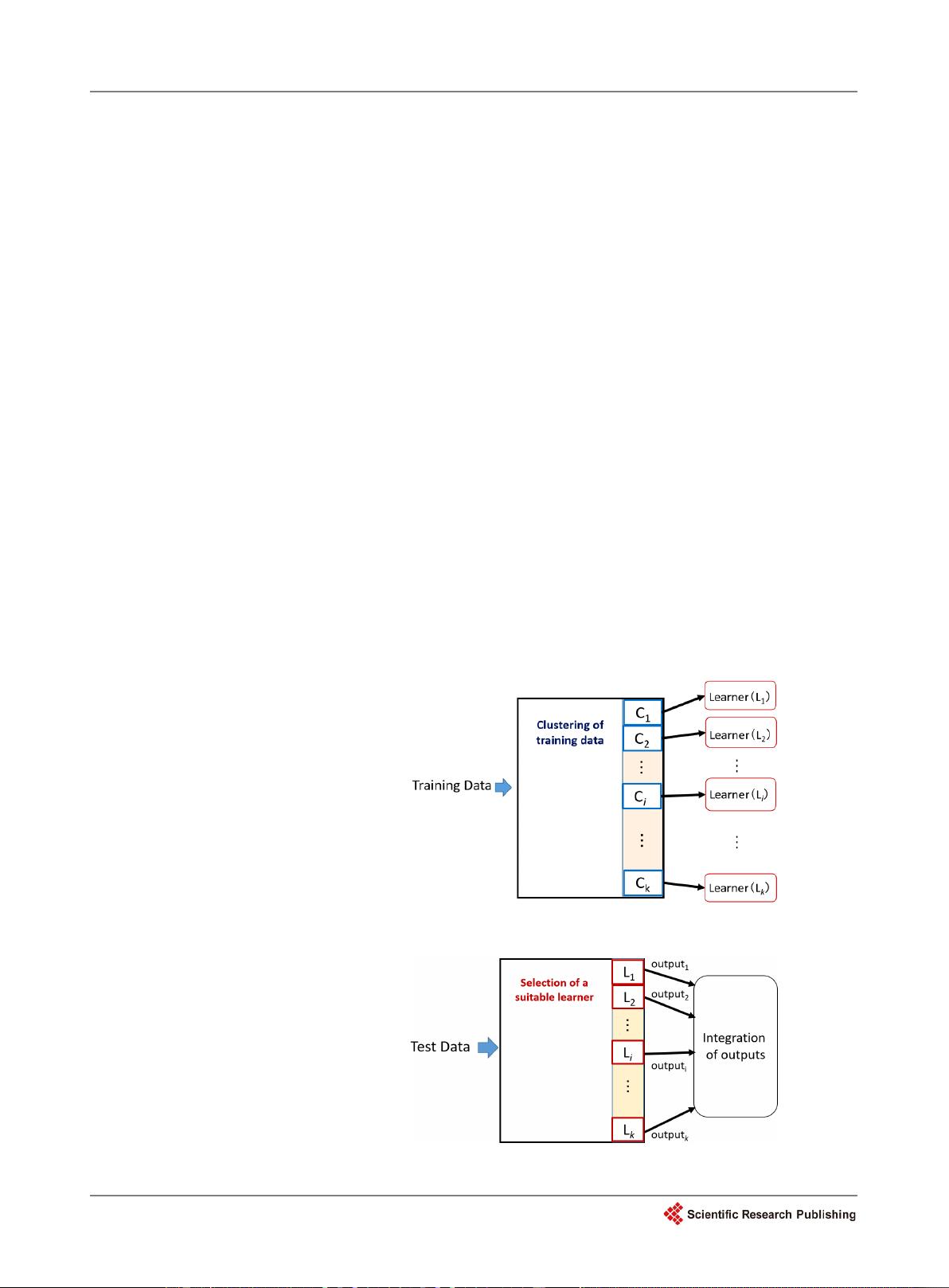
prediction employing multiple deep learners combined with a Bayesian ne
t-
work where training data is divided into clusters using K-
means clustering.
We decided how many clusters are the best for K-
means with the Bayesian
information criteria. Depending on each cluster, the multiple deep learners
are trained. We used three types of deep learners:
deep neural network
(DNN), recurrent neural network (RNN), and long short-
term memory
(LSTM). A naive Bayes classifier is used to determine which deep learner is in
charge of predicting a particular time-series. Our propos
ed method will be
applied to a set of financial time-
series data, the Nikkei Average Stock price,
to assess the accuracy of the predictions made. Compared with the conve
n-
tional method of employing a single deep learner to acquire all the data, it is
demonstrated by our proposed method that F-value and accuracy are i
m-
proved.
Keywords
Time-Series Data, Deep Learning, Bayesian Network, Recurrent Neural
Network, Long Short-Term Memory, Ensemble Learning, K-Means
1. Introduction
Deep learning has been developed to compensate for the shortcomings of pre-
vious neural networks [1] and is well known for its high performance in the
fields of character and image recognition [2]. In addition, deep learning’s influ-
ence is impacting various other fields [3] [4] [5], and its efficiency and accuracy
have been much bolstered by recent research. However, deep learning is subject
to three main drawbacks. For instance, obtaining and generating appropriate
How to cite this paper:
Kobayashi, S
. and
Shirayama
, S. (2017) Time Series
Forecasting
with Multiple Deep Learners: Selection
from a Bayesian Network
.
Journal of Data
Analysis and Information Processing
,
5,
115
-130.
https://doi.org/10.4236/jdaip.2017.53009
Received:
July 10, 2017
Accepted:
August 26, 2017
Published:
August 29, 2017
Copyright © 201
7 by authors and
Scientific
Research Publishing Inc.
This work is licensed
under the Creative
Commons Attribution International
License (CC BY
4.0).
http://creativecommons.org/licenses/by/4.0/
Open Access


剩余15页未读,继续阅读

weixin_38551070
- 粉丝: 3
- 资源: 900
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- zigbee-cluster-library-specification
- JSBSim Reference Manual
- c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
- 建筑供配电系统相关课件.pptx
- 企业管理规章制度及管理模式.doc
- vb打开摄像头.doc
- 云计算-可信计算中认证协议改进方案.pdf
- [详细完整版]单片机编程4.ppt
- c语言常用算法.pdf
- c++经典程序代码大全.pdf
- 单片机数字时钟资料.doc
- 11项目管理前沿1.0.pptx
- 基于ssm的“魅力”繁峙宣传网站的设计与实现论文.doc
- 智慧交通综合解决方案.pptx
- 建筑防潮设计-PowerPointPresentati.pptx
- SPC统计过程控制程序.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论1