
★(干货)一个框架解决几乎所有机器学习问题-一起大数据
上周一个叫 Abhishek Thakur 的数据科学家,在他的 Linkedin 发表了一篇文章 Approaching (Almost) Any Machine
Learning Problem,介绍他建立的一个自动的机器学习框架,几乎可以解决任何机器学习问题,项目很快也会发布出来。这篇
文章迅速火遍 Kaggle,他参加过100多个数据科学相关的竞赛,积累了很多宝贵的经验,看他很幽默地说“写这样的框架需要
很多丰富的经验,不是每个人都有这样的经历,而很多人有宝贵的经验,但是他们不愿意分享,我呢恰好是又有一些经验,又愿
意分享的人”。当然这篇文章也是受到争议的,很多人觉得并不全面。
我最近也在准备参加 Kaggle,之前看过几个例子,自己也总结了一个分析的流程,今天看了这篇文章,里面提到了一些高效的
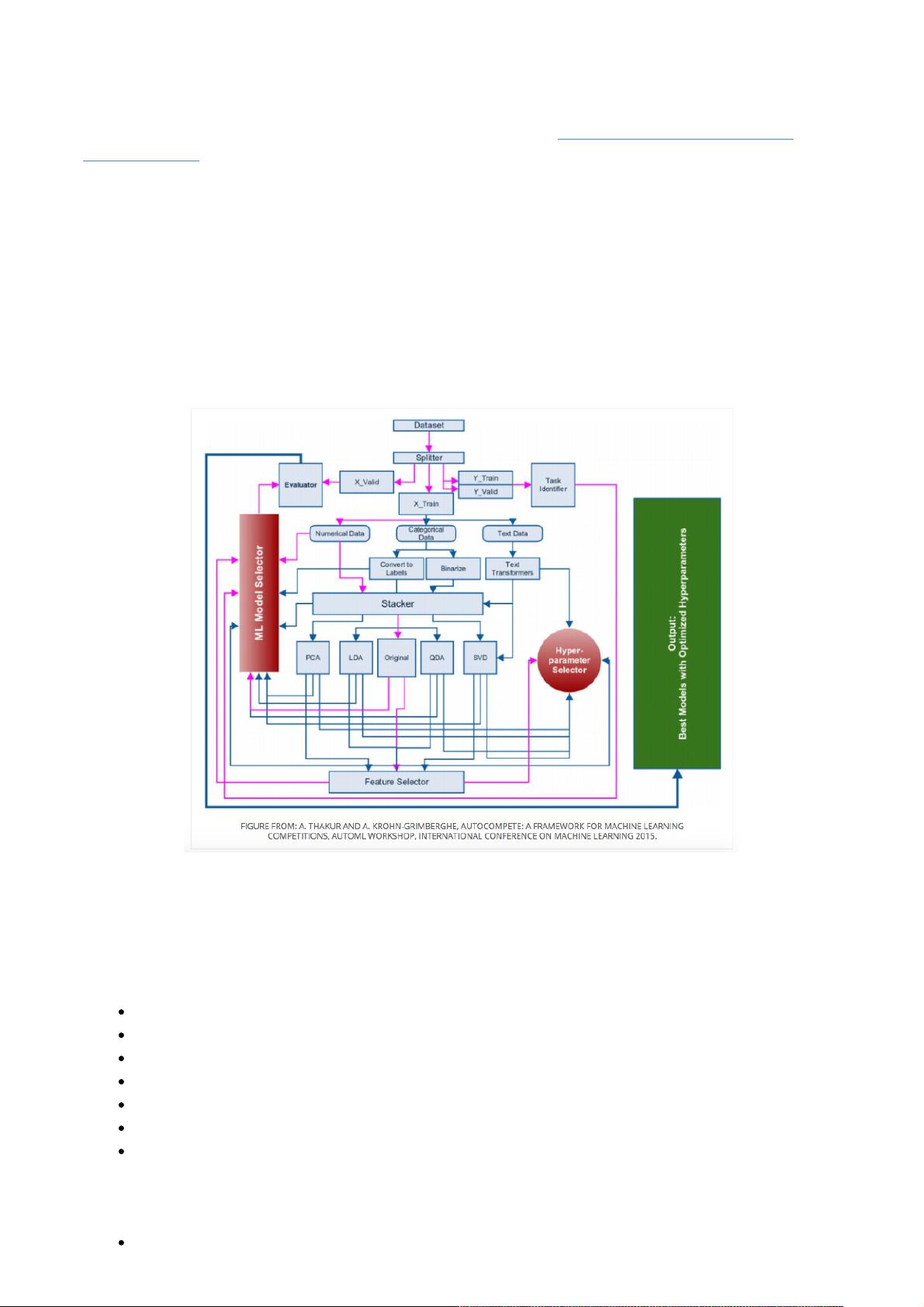
方法,最干货的是,他做了一个表格,列出了各个算法通常需要训练的参数。
这个问题很重要,因为大部分时间都是通过调节参数,训练模型来提高精度。作为一个初学者,第一阶段,最想知道的问题,就
是如何调节参数。因为分析的套路很简单,就那么几步,常用的算法也就那么几个,以为把算法调用一下就可以了么,那是肯定
不行的。实际过程中,调用完算法后,结果一般都不怎么好,这个时候还需要进一步分析,哪些参数可以调优,哪些数据需要进
一步处理,还有什么更合适的算法等等问题。
接下来一起来看一下他的框架。
据说数据科学家 60-70% 的时间都花在数据清洗和应用模型算法上面,这个框架主要针对算法的应用部分。
1481379430-5502-1667471-4102082116d66a08
Pipeline
什么是 Kaggle?
Kaggle是一个数据科学竞赛的平台,很多公司会发布一些接近真实业务的问题,吸引爱好数据科学的人来一起解决,可以通过
这些数据积累经验,提高机器学习的水平。
应用算法解决 Kaggle 问题,一般有以下几个步骤:
第一步:识别问题
第二步:分离数据
第三步:构造提取特征
第四步:组合数据
第五步:分解
第六步:选择特征
第七步:选择算法进行训练
当然,工欲善其事,必先利其器,要先把工具和包都安好。
最方便的就是安装 Anaconda,这里面包含大部分数据科学所需要的包,直接引入就可以了,常用的包有:
pandas:常用来将数据转化成 dataframe 形式进行操作

2h4n9y1m1n9
- 粉丝: 10
- 资源: 3
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- 利用迪杰斯特拉算法的全国交通咨询系统设计与实现
- 全国交通咨询系统C++实现源码解析
- DFT与FFT应用:信号频谱分析实验
- MATLAB图论算法实现:最小费用最大流
- MATLAB常用命令完全指南
- 共创智慧灯杆数据运营公司——抢占5G市场
- 中山农情统计分析系统项目实施与管理策略
- XX省中小学智慧校园建设实施方案
- 中山农情统计分析系统项目实施方案
- MATLAB函数详解:从Text到Size的实用指南
- 考虑速度与加速度限制的工业机器人轨迹规划与实时补偿算法
- Matlab进行统计回归分析:从单因素到双因素方差分析
- 智慧灯杆数据运营公司策划书:抢占5G市场,打造智慧城市新载体
- Photoshop基础与色彩知识:信息时代的PS认证考试全攻略
- Photoshop技能测试:核心概念与操作
- Photoshop试题与答案详解
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


