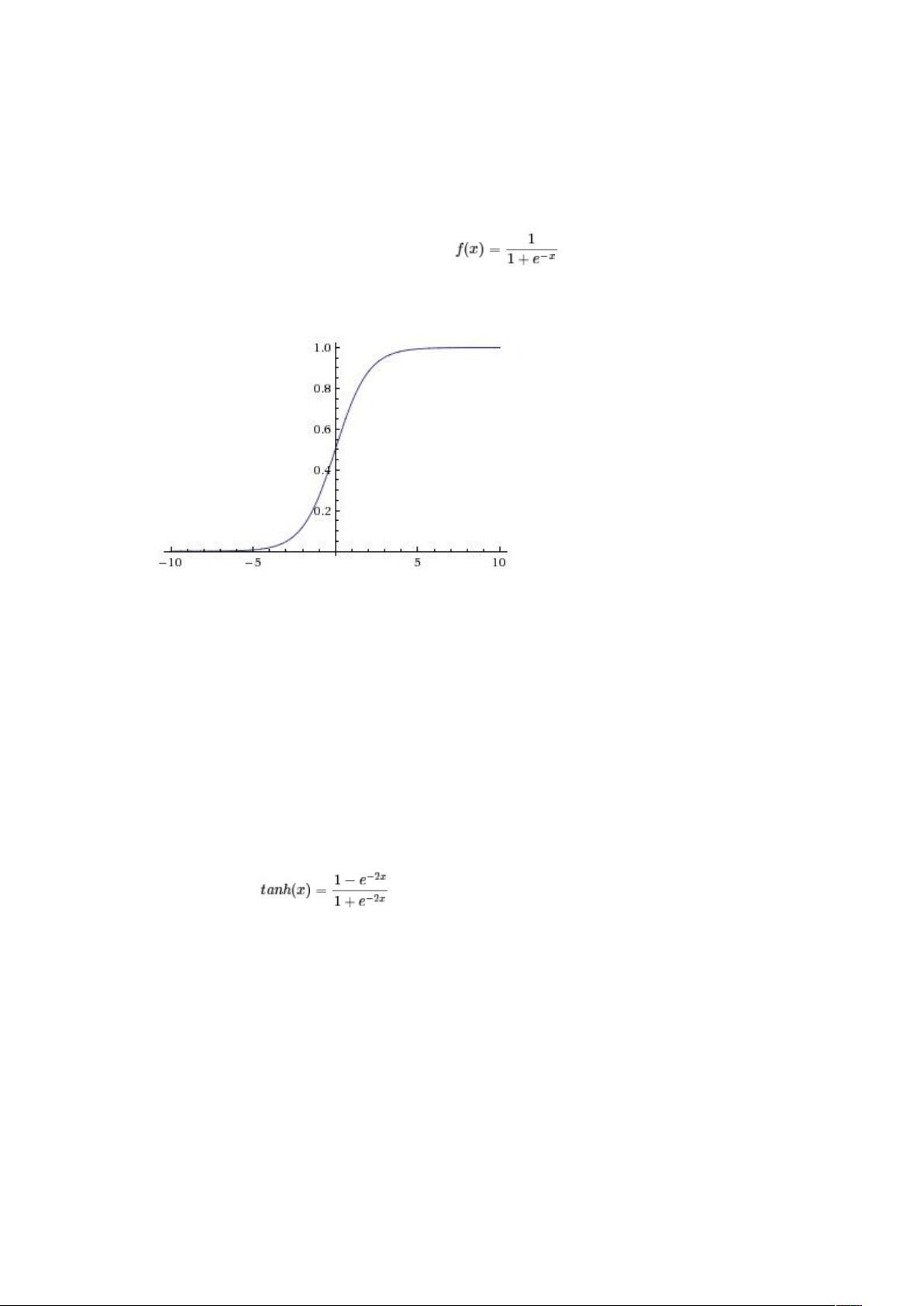
深度学习中的激活函数是神经网络模型中至关重要的组成部分,它们负责引入非线性并控制神经元的输出。本文将详细介绍几种常见的激活函数及其特点: 1. **Sigmoid函数**: - 定义:Sigmoid函数将输入映射到(0,1)的范围内,其公式为f(x) = 1 / (1 + e^(-x))。 - 优点:输出范围有限,易于理解和解释;计算简单,便于求导,常用于二分类问题的输出层。 - 缺点:由于其在输入值较大或较小时接近饱和,导致梯度变得非常小,即“梯度消失”问题,这在深层网络中可能影响学习过程。 2. **tanh函数**: - 定义:tanh函数输出范围在[-1,1],f(x) = (e^x - e^(-x)) / (e^x + e^(-x))。 - 优点:相比于Sigmoid,tanh有更快的收敛速度且输出以0为中心,但仍然存在梯度消失的问题。 3. **ReLU (Rectified Linear Unit)**: - 定义:f(x) = max(0, x),线性部分有助于梯度传播,避免了Sigmoid和tanh的饱和问题。 - 优点:加速收敛,简化计算,减少昂贵的指数运算;缓解梯度消失。 - 缺点:ReLU神经元对于负值输入无响应,可能导致“神经元死亡”问题,即权重不更新。 4. **LReLU (Leaky ReLU)**: - 为了克服ReLU的局限,LReLU引入一个小的斜率a,当输入小于0时,f(x) = ax。 - 缺点:需要谨慎调整a的值,以防止影响模型性能,且训练过程可能复杂。 5. **PReLU (Parametric ReLU)**: - 自适应地学习参数,结合了ReLU和LReLU的优点,能从数据中动态调整斜率,提高了模型性能。 - 特点:收敛快,误差率低,适合反向传播训练。 6. **ELU (Exponential Linear Unit)**: - f(x) = x (for x > 0) or α(e^x - 1) (for x < 0),α是常数。 - 优点:解决ReLU负区间的梯度消失问题,同时在负区间有更好的稳定性。 7. **Softplus & Softsign**: - Softplus是对ReLU的平滑版本,f(x) = ln(1 + e^x)。 - Softsign函数类似,f(x) = x / (1 + |x|)。 - 两者在正则化方面表现良好,但Softplus通常在实际应用中更为常见。 选择哪种激活函数取决于具体任务的需求和网络架构。实践中,ReLU及其变种是首选,但如果遇到特定问题,如梯度消失,可能会考虑使用ELU或带有参数的学习激活函数。理解每种激活函数的特点和适用场景,是构建高效深度学习模型的关键。
本内容试读结束,登录后可阅读更多
下载后可阅读完整内容,剩余4页未读,立即下载