

Visual Question Answering: A Survey of Methods and Datasets
Qi Wu, Damien Teney, Peng Wang, Chunhua Shen
∗
, Anthony Dick, Anton van den Hengel
e-mail: firstname.lastname@adelaide.edu.au
School of Computer Science, The University of Adelaide, SA 5005, Australia
Abstract
Visual Question Answering (VQA) is a challenging task that has received increasing attention from both the computer
vision and the natural language processing communities. Given an image and a question in natural language, it requires
reasoning over visual elements of the image and general knowledge to infer the correct answer. In the first part of
this survey, we examine the state of the art by comparing modern approaches to the problem. We classify methods
by their mechanism to connect the visual and textual modalities. In particular, we examine the common approach
of combining convolutional and recurrent neural networks to map images and questions to a common feature space.
We also discuss memory-augmented and modular architectures that interface with structured knowledge bases. In the
second part of this survey, we review the datasets available for training and evaluating VQA systems. The various
datatsets contain questions at different levels of complexity, which require different capabilities and types of reasoning.
We examine in depth the question/answer pairs from the Visual Genome project, and evaluate the relevance of the
structured annotations of images with scene graphs for VQA. Finally, we discuss promising future directions for the
field, in particular the connection to structured knowledge bases and the use of natural language processing models.
Keywords: Visual Question Answering, Natural Language Processing, Knowledge Bases, Recurrent Neural
Networks
Contents
1 Introduction 2
2 Methods for VQA 3
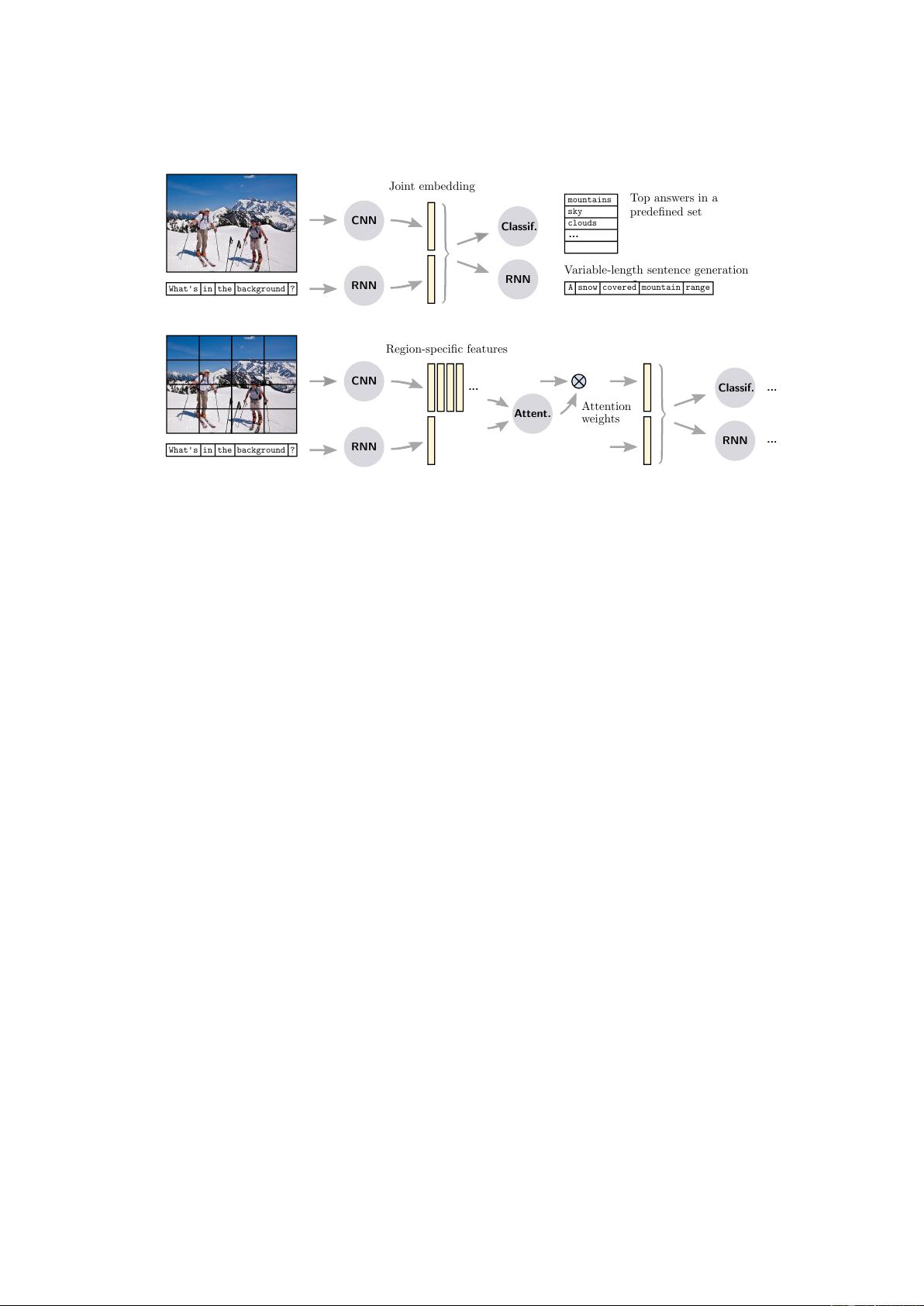
2.1 Joint embedding approaches . . . . . . 3
2.2 Attention mechanisms . . . . . . . . . 6
2.3 Compositional Models . . . . . . . . . 7
2.3.1 Neural Module Networks . . . . 8
2.3.2 Dynamic Memory Networks . . 9
2.4 Models using external knowledge bases 9
3 Datasets and evaluation 10
3.1 Datasets of natural images . . . . . . . 11
3.2 Datasets of clipart images . . . . . . . . 16
3.3 Knowledge base-enhanced datasets . . . 17
3.4 Other datasets . . . . . . . . . . . . . . 18
4 Structured scene annotations for VQA 18
5 Discussion and future directions 21
∗
Corresponding author
6 Conclusion 22
Preprint submitted to Elsevier July 21, 2016
arXiv:1607.05910v1 [cs.CV] 20 Jul 2016



剩余24页未读,继续阅读

zhuf14
- 粉丝: 16
- 资源: 57
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- VMP技术解析:Handle块优化与壳模板初始化
- C++ Primer 第四版更新:现代编程风格与标准库
- 计算机系统基础实验:缓冲区溢出攻击(Lab3)
- 中国结算网上业务平台:证券登记操作详解与常见问题
- FPGA驱动的五子棋博弈系统:加速与创新娱乐体验
- 多旋翼飞行器定点位置控制器设计实验
- 基于流量预测与潮汐效应的动态载频优化策略
- SQL练习:查询分析与高级操作
- 海底数据中心散热优化:从MATLAB到动态模拟
- 移动应用作业:MyDiaryBook - Google Material Design 日记APP
- Linux提权技术详解:从内核漏洞到Sudo配置错误
- 93分钟快速入门 LaTeX:从入门到实践
- 5G测试新挑战与罗德与施瓦茨解决方案
- EAS系统性能优化与故障诊断指南
- Java并发编程:JUC核心概念解析与应用
- 数据结构实验报告:基于不同存储结构的线性表和树实现
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


