
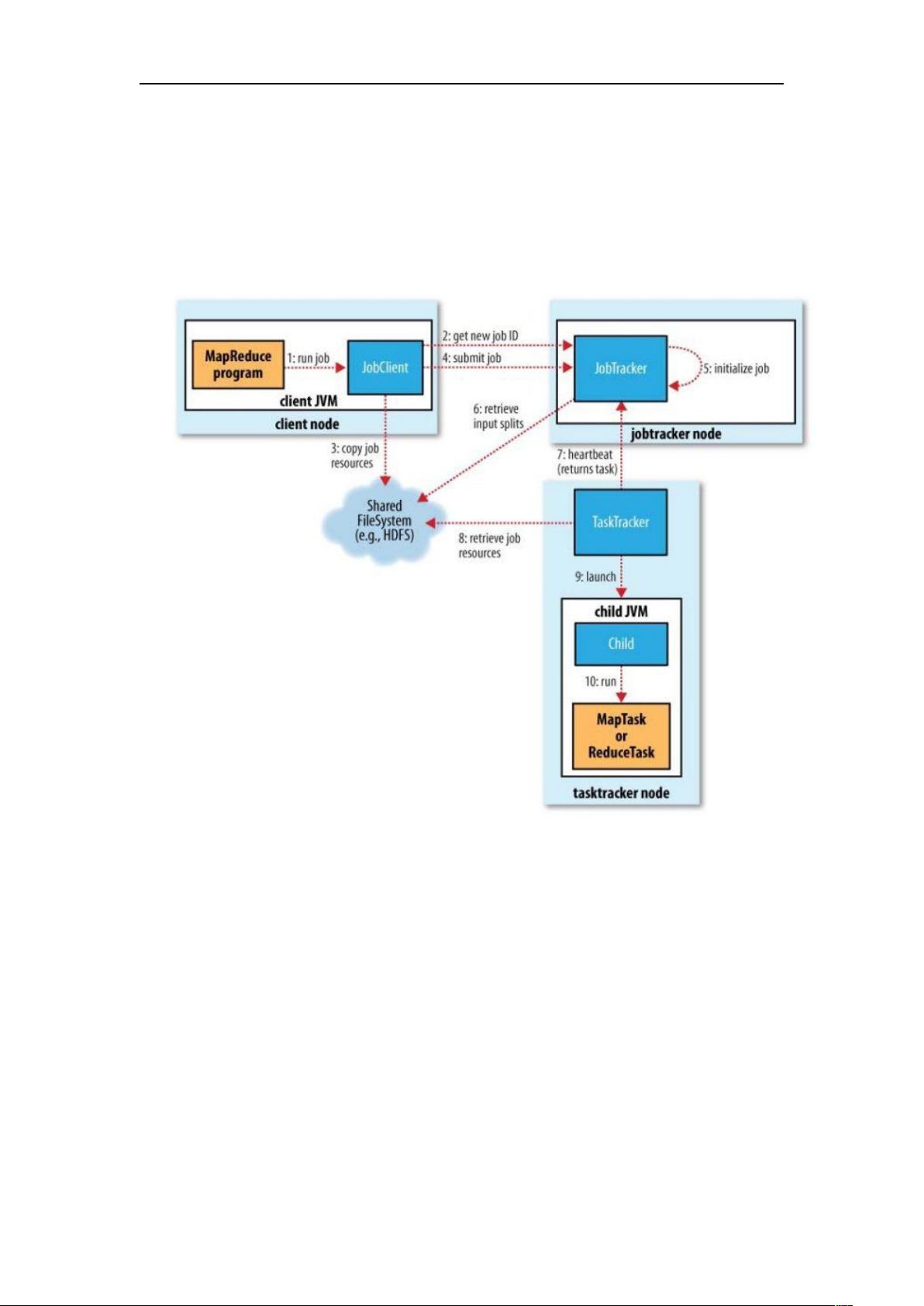
TaskTracker 上,并监控它们,如果发现有失败的 task 就重新运行它。一般情况应该把
JobTracker 部署在单独的机器上。
1.3 TaskTracker
TaskTracker 是运行于多个节点上的 slaver 服务。TaskTracker 则负责直接执行每一个
task。TaskTracker 都需要运行在 HDFS 的 DataNode 上,
2 数据结构
2.1 Mapper 和 Reducer
运行于 Hadoop 的 MapReduce 应用程序最基本的组成部分包括一个 Mapper 和一个
Reducer 类,以及一个创建 JobConf 的执行程序,在一些应用中还可以包括一个 Combiner
类,它实际也是 Reducer 的实现。
剩余18页未读,继续阅读

sunny870422
- 粉丝: 0
- 资源: 3
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- 共轴极紫外投影光刻物镜设计研究
- 基于GIS的通信管线管理系统构建与音视频编解码技术应用
- 单站被动目标跟踪算法:空频域信息下的深度研究与进展
- 构建通信企业工程项目的项目管理成熟度模型:理论与应用
- 基于控制理论的主动队列管理算法与稳定性分析
- 谷歌文件系统下的实用网络编码技术在分布式存储中的应用
- CMOS图像传感器快门特性与运动物体测量研究
- 深孔采矿研究:3D数据库在采场损失与稳定性控制中的应用
- 《洛神赋图》图像研究:明清以来的艺术价值与历史意义
- 故宫藏《洛神赋图》图像研究:明清艺术价值与审美的飞跃
- 分布式视频编码:无反馈通道算法与复杂运动场景优化
- 混沌信号的研究:产生、处理与通信系统应用
- 基于累加器的DSP数据通路内建自测试技术研究
- 跨国媒体对南亚农村社会的影响:以斯里兰卡案例的社会学分析
- 散单元法与CFD结合模拟气力输送研究
- 基于粒化机理的粗糙特征选择算法:海量数据高效处理研究
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


