理解Kafka:架构、原理与核心API
23 浏览量
更新于2024-08-27
收藏 475KB PDF 举报
"本文主要介绍了Kafka的基本架构与工作原理,包括Kafka的四个核心API,服务器组件(Broker)、主题(Topic)、分区(Partition)以及日志等关键概念。"
Kafka是一个分布式流处理平台,它被设计用来处理大规模实时数据流。其核心功能包括发布订阅记录流、数据持久化和容错能力。Kafka运行在一组服务器上,形成一个高可用的集群,用于存储和传输数据。
1. **核心API**
- **生产者API**:生产者负责将数据发布到Kafka的主题中。它允许应用程序生成记录流并将其发送到一个或多个特定的主题,确保数据的可靠传输。
- **消费者API**:消费者通过订阅主题来消费数据。它们处理从主题接收的记录流,可以是顺序消费,也可以是并行消费,以提高处理效率。
- **Streams API**:Kafka Streams允许应用程序作为流处理器,从一个或多个输入主题读取数据,经过处理后将结果写入一个或多个输出主题,实现数据转换和分析。
- **Connector API**:Kafka Connector用于构建可重用的生产者和消费者,能够连接Kafka主题与其他应用程序或数据系统,如数据库,实现数据同步。
2. **架构组件**
- **Broker**:每个Kafka服务器被称为Broker,多个Broker协同工作构成Kafka集群。Brokers通过ZooKeeper进行协调,保证集群的稳定性和数据一致性。
- **主题(Topic)**:主题是数据的分类,一个主题可以有多个分区,每个分区存储一部分数据。主题可以有多个订阅者,支持多用户订阅。
- **分区(Partition)**:每个主题被划分为多个分区,分布在不同的Broker上,确保负载均衡和水平扩展。每个分区是一个有序且不可变的消息序列,保证消息的顺序性。
- **日志**:每个分区对应一个逻辑日志文件,日志中的消息按照追加的方式添加,保证了消息的顺序。Kafka使用日志来实现数据的持久化,即使在服务器故障时也能恢复数据。
3. **通信与复制**
- **通信协议**:Kafka使用简单、高效的TCP协议与客户端交互,支持多种语言的客户端库。
- **数据复制**:Kafka通过在多个Broker之间复制分区来实现容错。每个分区通常有一个主副本和若干个从副本,主副本负责接收新的消息并将其追加到日志中,从副本则同步主副本的数据,以防主副本失效。
4. **消费者组**:Kafka的消费者采用消费者组的概念,每个组内的消费者可以并行消费主题的分区,提高数据处理速度。同一分区只能被组内一个消费者消费,确保消息的唯一处理。
5. **数据保留策略**:Kafka可以根据配置的策略自动删除旧数据,例如基于时间或存储空间的限制,以保持集群的性能和可用性。
Kafka作为一个高效、可靠的流处理平台,适用于大数据实时分析、日志聚合、事件源等场景,其强大的API和灵活的架构使其在现代大数据环境中广泛应用。理解Kafka的架构和工作原理对于有效地利用这一工具至关重要。
kafka架构与原理架构与原理
1、简介
它可以让你发布和订阅记录流。在这方面,它类似于一个消息队列或企业消息系统。
它可以让你持久化收到的记录流,从而具有容错能力。
首先,明确几个概念:
Kafka运行在一个或多个服务器上。
Kafka集群分类存储的记录流被称为主题(Topics)。
每个消息记录包含一个键,一个值和时间戳。
Kafka有四个核心API:
生产者 API 允许应用程序发布记录流至一个或多个Kafka的话题(Topics)。
消费者API 允许应用程序订阅一个或多个主题,并处理这些主题接收到的记录流。
Streams API 允许应用程序充当流处理器(stream processor),从一个或多个主题获取输入流,并生产一个输出流至一个或多
个的主题,能够有效地变换输入流为输出流。
Connector API 允许构建和运行可重用的生产者或消费者,能够把 Kafka主题连接到现有的应用程序或数据系统。例如,一个
连接到关系数据库的连接器(connector)可能会获取每个表的变化。
Kafka的客户端和服务器之间的通信是靠一个简单的,高性能的,与语言无关的TCP协议完成的。这个协议有不同的版本,并
保持向前兼容旧版本。Kafka不光提供了一个Java客户端,还有许多语言版本的客户端。
2、 架构
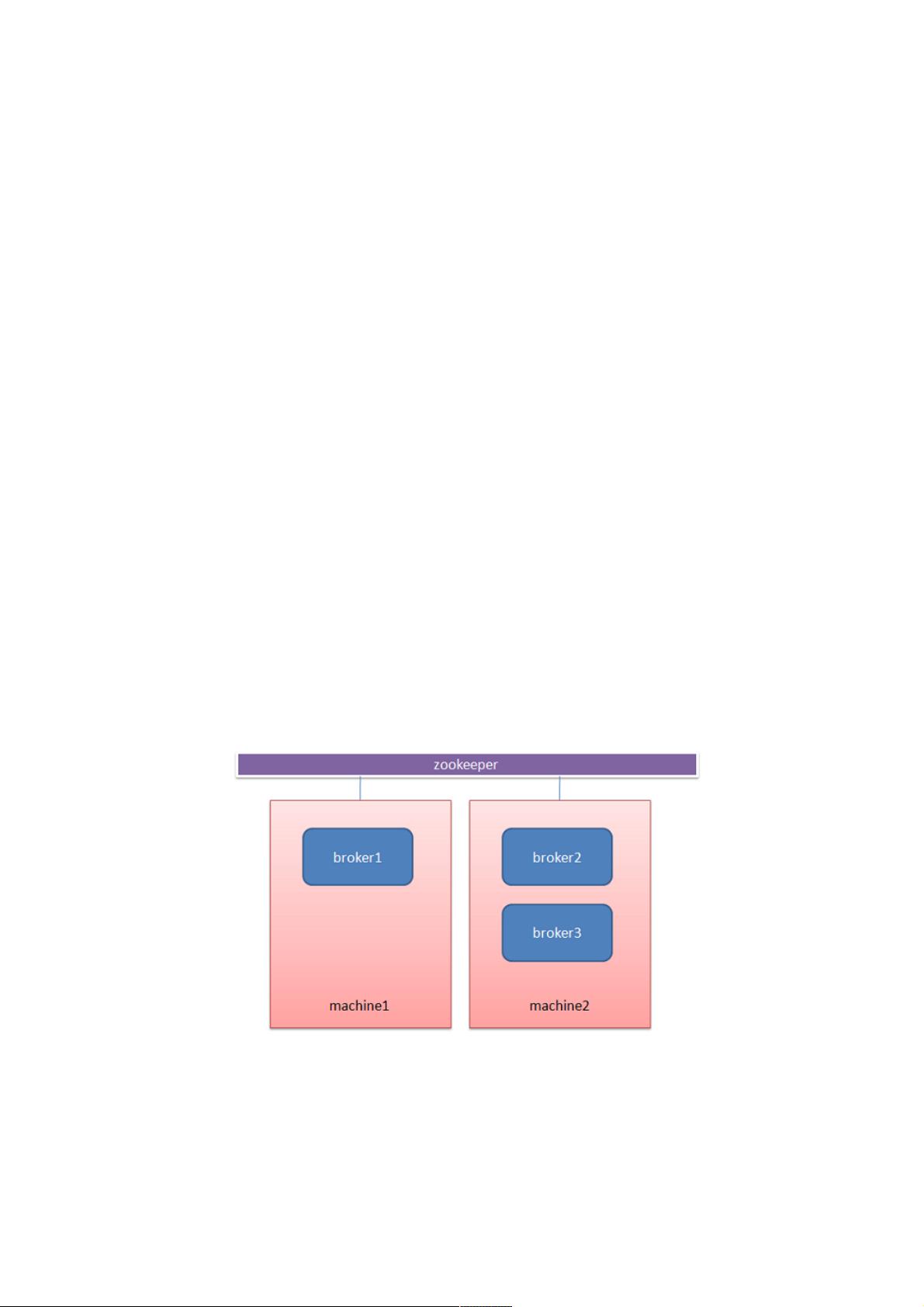
2.1 Broker
每个kafka server称为一个Broker,多个borker组成kafka cluster。一个机器上可以部署一个或者多个Broker,这多个Broker连
接到相同的ZooKeeper就组成了Kafka集群。
2.2 主题Topic
让我们先来了解Kafka的核心抽象概念记录流 – 主题。主题是一种分类或发布的一系列记录的名义上的名字。Kafka的主题始
终是支持多用户订阅的; 也就是说,一个主题可以有零个,一个或多个消费者订阅写入的数据。
Topic 与broker
一个Broker上可以创建一个或者多个Topic。同一个topic可以在同一集群下的多个Broker中分布。
下载后可阅读完整内容,剩余8页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-01-27 上传
2021-01-27 上传
2021-10-14 上传
2022-06-09 上传
2021-01-27 上传

weixin_38551431
- 粉丝: 4
- 资源: 898
 我的内容管理
展开
我的内容管理
展开







最新资源
- Python库 | indy-node-dev-1.6.572.tar.gz
- Todo-Web-Application:使用Maven和Bootstrap工具在Java EE中构建
- ASCStuff2018
- 创业计划书-商业计划书模版6
- ShowDC-Map:javascript 画布 HTML 动画
- weixin051畅阅读微信小程序+ssm(源码+部署说明+演示视频+源码介绍+lw).rar
- Windows-7:基于Windows 7外观Linux主题
- 51单片机舵机调试 免费下载
- python游戏源码-09 五子棋.zip源码python项目实例源码打包下载
- 取随机好友赞-易语言.zip
- vscode-arrr:该扩展为您的Angular代码库提供了重构工具
- gallery:jQuery 画廊组件
- 创业计划书-华南理工大学科技园入园企业商业计划书模板
- Easy MCS Gomoku:五子棋AI-开源
- weixin014健身管理系统及会员微信小程序的设计与实现+ssm(源码+部署说明+演示视频+源码介绍+lw).rar
- asgineer:一个非常瘦的ASGI Web框架
