Hadoop集群部署:从准备到配置
需积分: 10 69 浏览量
更新于2024-07-24
收藏 1.07MB PDF 举报
"实施Hadoop集群"
在大数据处理领域,Hadoop是一个广泛使用的开源框架,它允许在分布式计算环境中存储和处理大量数据。本资源主要讨论了如何实施一个Hadoop集群,包括环境准备、配置以及不同运行模式的介绍。
首先,实施Hadoop集群的关键步骤之一是设置好运行环境。推荐使用虚拟机如VMware的Workstation(针对个人PC)或ESXi(针对服务器),因为它们提供了方便的管理和克隆功能。在虚拟机中安装Linux操作系统,例如CentOS,确保在分区时包含必要的组件,如SSH服务、VI编辑器和Perl,以便后续配置和脚本执行。
接下来,需要在系统中安装Java开发工具包(JDK),这是Hadoop运行的必要条件。可以从Oracle官方网站下载并安装JDK。
Hadoop有三种运行模式:
1. **单机模式**:适合初学者,快速安装,但只适用于调试,不支持分布式计算。
2. **伪分布模式**:在一个节点上模拟分布式环境,所有Hadoop进程都在同一台机器上运行,包括NameNode、DataNode、JobTracker、TaskTracker和SecondaryNameNode。
3. **完全分布式模式**:实际的生产环境,由多个节点组成,每个节点负责不同的任务,提供高可用性和容错性。
对于**伪分布式模式**的安装和配置,具体步骤包括:
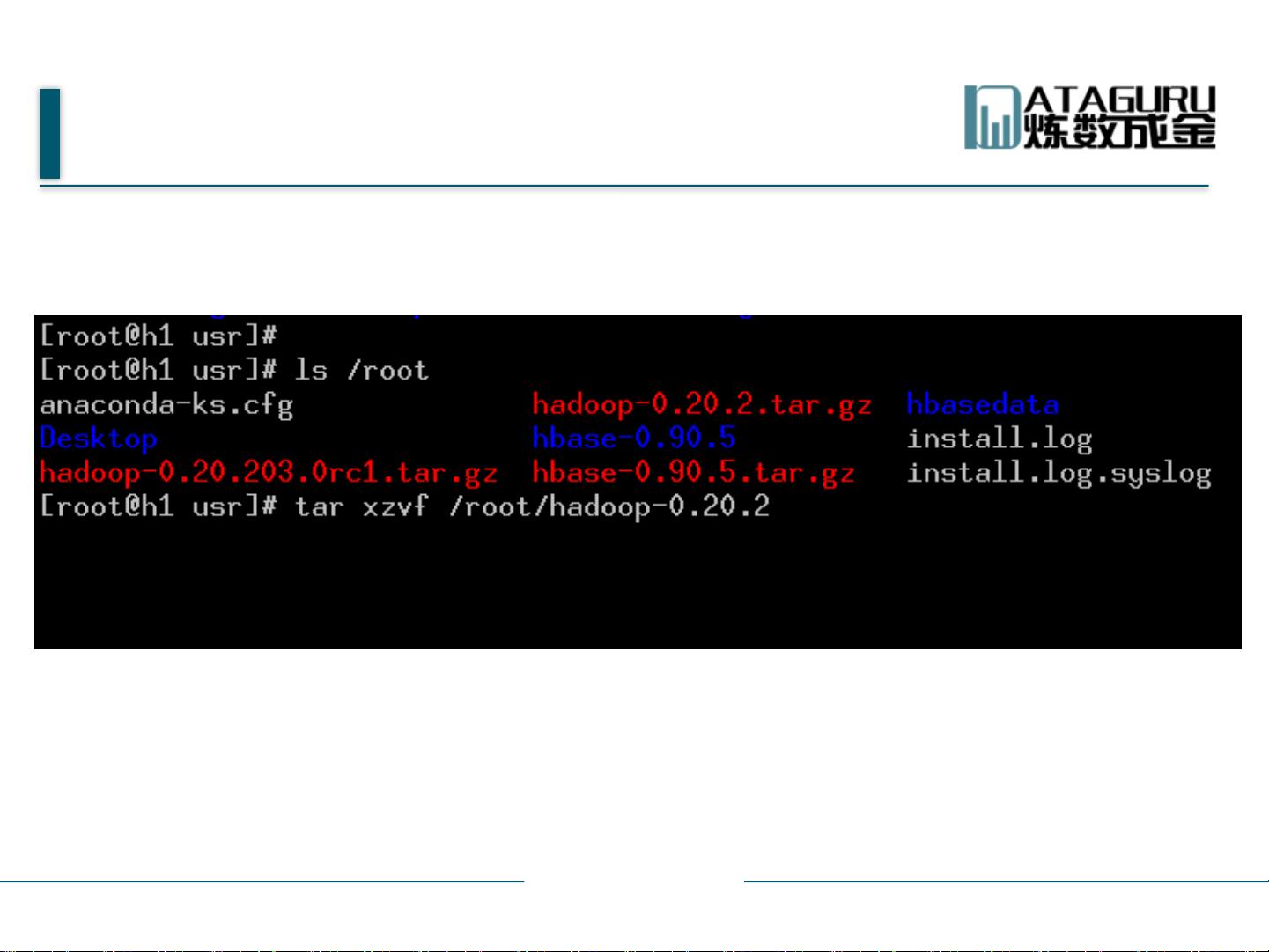
1. 下载Hadoop的指定版本(如0.20.2)并解压缩。
2. 修改配置文件,如在`hadoop-env.sh`中配置Java路径(在0.23版本后,配置文件位置可能发生变化)。
3. 编辑`core-site.xml`、`hdfs-site.xml`和`mapred-site.xml`,这些文件定义了Hadoop的核心参数和集群行为。
4. 配置SSH,生成密钥对,实现无密码登录localhost,简化远程操作。
5. 格式化HDFS文件系统,初始化NameNode。
6. 使用`start-all.sh`启动Hadoop集群的所有服务。
7. 当需要停止集群时,使用`stop-all.sh`命令。
最后,文件还提到了下载Hadoop的相关信息,但具体的下载链接在此未给出。
实施Hadoop集群是一个涉及多方面知识的过程,包括操作系统管理、网络配置、Java环境、SSH通信以及Hadoop自身的配置和管理。理解这些概念和步骤是构建和维护高效Hadoop集群的基础。
DATAGURU专业数据分析网站
2012.8.25
解压hadoop
8

剩余40页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-09-05 上传
2021-09-29 上传
2018-09-03 上传

XiaoYeKeXiaoLong
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- Elasticsearch核心改进:实现Translog与索引线程分离
- 分享个人Vim与Git配置文件管理经验
- 文本动画新体验:textillate插件功能介绍
- Python图像处理库Pillow 2.5.2版本发布
- DeepClassifier:简化文本分类任务的深度学习库
- Java领域恩舒技术深度解析
- 渲染jquery-mentions的markdown-it-jquery-mention插件
- CompbuildREDUX:探索Minecraft的现实主义纹理包
- Nest框架的入门教程与部署指南
- Slack黑暗主题脚本教程:简易安装指南
- JavaScript开发进阶:探索develop-it-master项目
- SafeStbImageSharp:提升安全性与代码重构的图像处理库
- Python图像处理库Pillow 2.5.0版本发布
- mytest仓库功能测试与HTML实践
- MATLAB与Python对比分析——cw-09-jareod源代码探究
- KeyGenerator工具:自动化部署节点密钥生成
