霍格沃茨分院帽:数据聚类在实际与想象中的应用
版权申诉
178 浏览量
更新于2024-06-25
收藏 6.69MB PDF 举报
在计算机科学领域,"clustering.pdf" 文件探讨了一种关键的数据分析方法——聚类(Clustering)。聚类是将个体或数据对象组织成有意义的群组的过程,类似于霍格沃茨魔法学校中的分院帽决定学生所属的格兰芬多、赫奇帕奇、拉文克劳或斯莱特林四个学院。当数据集的划分规则清晰,例如已知学生应该按照特定的标准被分配到各个学院时,聚类变得相对简单。然而,更常见的情况是面对大量未分类的数据,我们需要设计一种合理的算法来自动识别并组织这些个体。
聚类的目标是根据数据内在的结构或特征进行分组,而不是依赖外部指示或先验知识。例如,在日常生活中,我们可能根据生物类型(动物、植物或矿物)或生活环境(陆地、海洋或空中)对物品进行分类。在数据分析中,这种划分方式取决于研究者的兴趣和问题背景,可能涉及颜色(如红黑)、类别(如牌面花色或数字)等不同维度。
聚类算法可以根据不同的准则进行,如层次聚类(Hierarchical Clustering),它通过逐步合并或分割数据点形成树状结构;K-means聚类,通过迭代计算每个数据点与预设中心点的距离,将它们分配到最近的簇;或者基于密度的聚类(Density-Based Clustering),关注的是数据点之间的邻域关系。
在实际应用中,选择合适的聚类方法至关重要,因为不同的算法对数据的敏感性和结果的稳定性有所差异。例如,K-means对于簇的形状有较强的假设,而DBSCAN则更适用于发现任意形状的簇。在选择算法时,需要考虑数据的特性、目标群体的定义以及所需的结果质量。
"clustering.pdf" 文件涵盖了聚类的基本概念、应用场景和实际操作中的考量因素,展示了如何将计算机科学的思维方式应用于数据的整理和分析,帮助我们在无明显标签的情况下洞察数据的内在规律。

Suppose we are given a set of objects and told that they are all related,
and we are asked to come up with a sort of family tree that illustrates
which objects are closely or only distantly related.
If we have a distance function, then a simple approach is called The
Single Linkage Rule:
1. Make every object a separate cluster.
2. Find the two closest clusters and merge them into one.
3. Keep doing this until you only have one cluster.
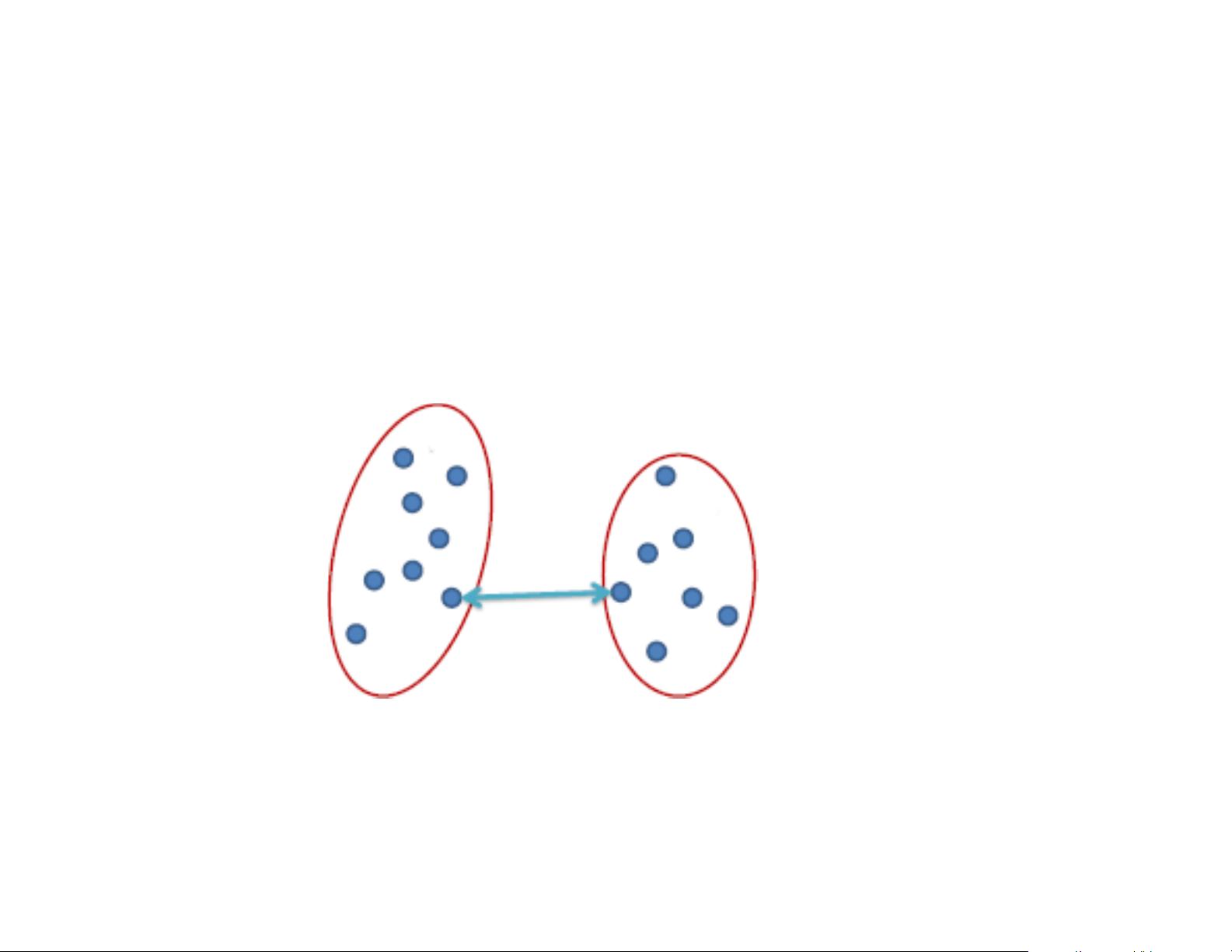
To find the distance between two clusters, we consider every possible
selection of one item from either cluster, and take the closest pair.



剩余172页未读,继续阅读
2023-08-15 上传
2023-10-31 上传
2023-06-08 上传
2023-10-16 上传
2023-07-05 上传
2023-12-01 上传

卷积神经网络
- 粉丝: 359
- 资源: 8440
 我的内容管理
展开
我的内容管理
展开







最新资源
- 天池大数据比赛:伪造人脸图像检测技术
- ADS1118数据手册中英文版合集
- Laravel 4/5包增强Eloquent模型本地化功能
- UCOSII 2.91版成功移植至STM8L平台
- 蓝色细线风格的PPT鱼骨图设计
- 基于Python的抖音舆情数据可视化分析系统
- C语言双人版游戏设计:别踩白块儿
- 创新色彩搭配的PPT鱼骨图设计展示
- SPICE公共代码库:综合资源管理
- 大气蓝灰配色PPT鱼骨图设计技巧
- 绿色风格四原因分析PPT鱼骨图设计
- 恺撒密码:古老而经典的替换加密技术解析
- C语言超市管理系统课程设计详细解析
- 深入分析:黑色因素的PPT鱼骨图应用
- 创新彩色圆点PPT鱼骨图制作与分析
- C语言课程设计:吃逗游戏源码分享
