使用Pig与Hadoop进行数据流脚本编程
"Programming Pig: Dataflow Scripting with Hadoop"
本书《Programming Pig》由Alan Gates撰写,详细介绍了如何使用Pig语言在Hadoop架构上进行数据处理。这本书超过200页,旨在帮助读者理解并掌握Pig语言,从而有效地处理大数据集。Pig是Hadoop生态系统中的一个强大工具,它提供了一种高级语言,让数据处理变得更加简单和直观,尤其适合处理大规模的数据流。
Pig Latin是Pig所使用的脚本语言,它允许用户定义数据处理的逻辑,并将其转换为一组可以在Hadoop MapReduce框架下运行的任务。Pig Latin具有声明性,这意味着用户只需要描述他们想要的结果,而不需要关心如何实现这个过程的细节。这种特性使得Pig成为非程序员或数据分析师处理复杂数据任务的理想选择。
书中的内容可能涵盖了以下主要知识点:
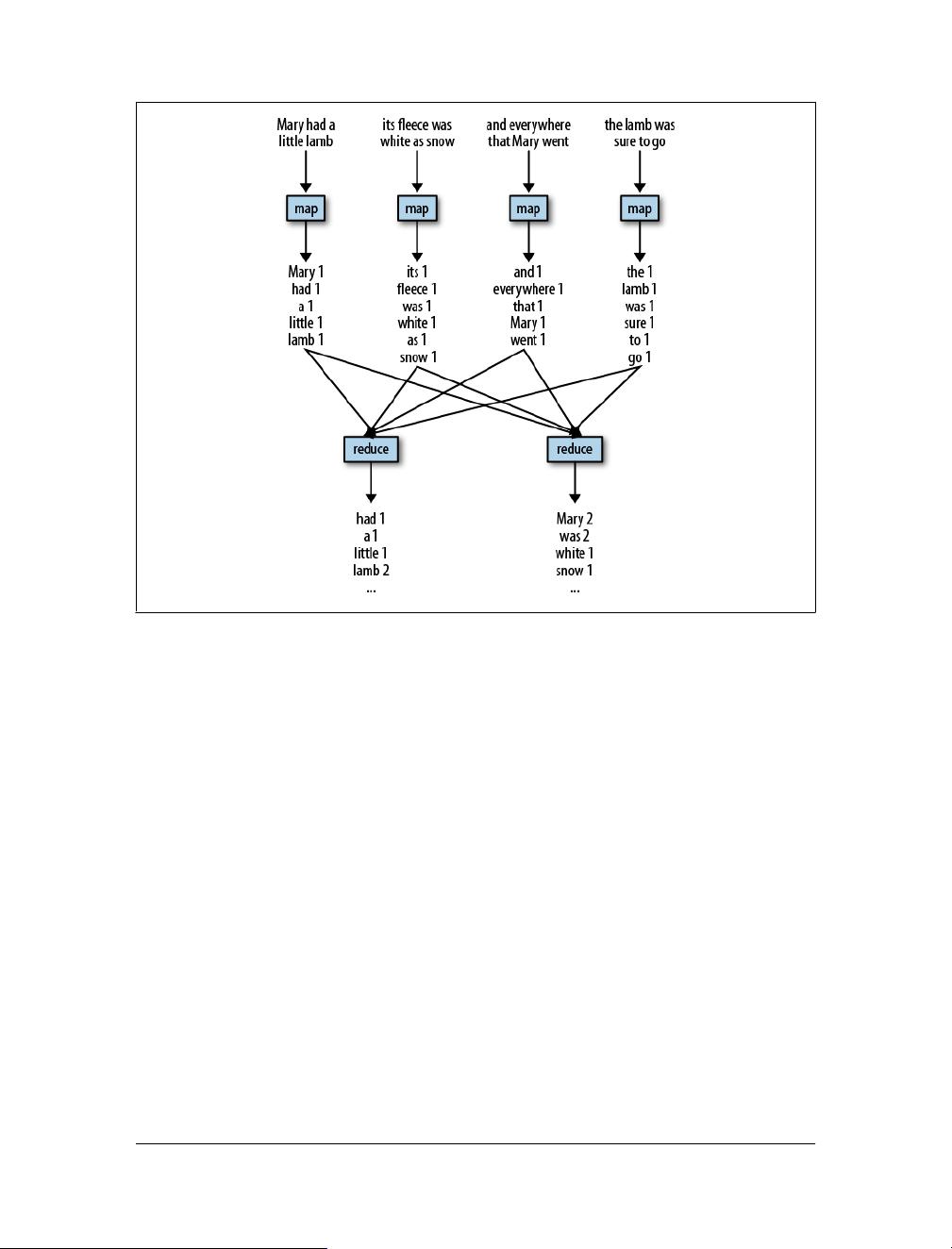
1. **Pig Latin基础**:包括基本的数据类型、操作符、加载和存储数据、以及数据转换函数的使用。例如,用户可以学习如何使用LOAD命令从HDFS加载数据,使用FOREACH和GROUP进行数据聚合,以及如何使用JOIN和FILTER进行数据过滤和连接。
2. **Pig脚本设计**:讲解如何构建有效的数据处理流程,包括管道(pipeline)的概念,以及如何通过UDF(用户定义函数)扩展Pig的功能,处理更复杂的计算需求。
3. **Pig与Hadoop集成**:介绍Pig如何与Hadoop MapReduce协同工作,解释Pig作业的执行模型,以及如何调试和优化Pig脚本,以充分利用Hadoop集群的计算能力。
4. **性能优化**:讨论如何分析Pig日志,识别性能瓶颈,并提供改进数据处理效率的策略。这可能涉及数据倾斜的处理、减少中间结果的大小,以及选择合适的分区策略。
5. **案例研究**:书中可能会包含实际的数据处理案例,展示如何在实际场景中应用Pig来解决数据问题,如数据清洗、数据分析和挖掘等。
6. **最佳实践**:分享在开发Pig脚本时应遵循的指导原则,以确保代码的可读性、可维护性和可扩展性。
7. **Pig生态系统**:介绍Pig与其他Hadoop组件(如Hive、HBase等)的交互,以及Pig在大数据处理生态中的位置和价值。
通过这本书,读者不仅可以学习到Pig语言的基本用法,还能深入理解大数据处理的原理和方法,提升在Hadoop环境下处理大规模数据的能力。无论你是数据科学家、数据工程师还是对大数据感兴趣的IT专业人士,这本书都将为你提供宝贵的实践经验和理论知识。

Douglas of the Hadoop project provided me with very helpful feedback on the sections
covering Hadoop and MapReduce.
I would also like to thank Mike Loukides and the entire team at O’Reilly. They have
made writing my first book an enjoyable and exhilarating experience. Finally, thanks
to Yahoo! for nurturing Pig and dedicating more than 25 engineering years (and still
counting) of effort to it, and for graciously giving me the time to write this book.
xiv | Preface



剩余221页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2016-11-14 上传
2018-09-01 上传
2018-02-24 上传
2018-02-24 上传
2018-02-24 上传
点击了解资源详情

Antares6260
- 粉丝: 1
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- Hibernate In Action
- 第2章 递归与分治策略.pdf
- java基础入门教程
- pku ACM在线评判 ACM题目分类.doc
- jsp connect mysql
- ARTeam站上的10篇OD入门教程
- JXTA java p2p Programming(英文版)
- S3C2410开发流程
- 学习Excel.VBA与XML、ASP协同应用.pdf
- VC++环境下WinSock编程及实例分析
- 服务器选购指南白皮书
- 高质量C++/C编程指南
- 灰狐驱动学习笔记系列文章.pdf
- 3D Game Engine Architecture
- 23种java设计模式
- PowerDesigner UML 建模简介(第二部分).doc
