Linux环境下Hadoop安装配置指南
需积分: 1 116 浏览量
更新于2024-07-21
收藏 9.31MB DOCX 举报
"这篇文档详述了如何在Linux环境下安装Hadoop,主要步骤包括创建虚拟机、配置系统、安装Ubuntu、设置用户和主机名、安装Vim编辑器、创建Hadoop用户组和用户,以及安装SSH。"
在安装Hadoop之前,首先需要在虚拟机环境中配置Linux系统。在虚拟机管理客户端,新建虚拟机,选择合适的硬件配置,如内存、CPU数量和虚拟磁盘大小。对于网络适配器,推荐选择VMXNET3以确保更好的网络性能。接下来,需要为虚拟机分配启动镜像,这里选择了Ubuntu 32位版本。
安装过程中,应根据实际需求调整系统设置,例如内存和CPU核心数。在Ubuntu的安装过程中,可以选择快速安装并断开网络连接以加快进程。安装完毕后,重启系统,并通过Ctrl+Alt+T打开终端,安装Vim编辑器,这对于后续的配置工作非常必要。
为了管理和运行Hadoop,需要创建一个新的用户组和用户。通过`sudo groupadd hadoop`命令创建名为“hadoop”的用户组,然后使用`sudo useradd -d /home/pinno -m -g hadoop pinno`命令创建一个名为“pinno”的用户,同时指定用户主目录和用户组。接着,使用`passwd pinno`设置该用户的密码。
在新用户环境下,安装SSH是必要的,因为Hadoop集群中的节点需要通过SSH进行通信。可以通过`sudo apt-get install ssh`来安装SSH服务。安装完成后,可以编辑`/etc/hosts`文件,添加或更新主机名和IP地址,以便于节点间的识别。
至此,虚拟机环境的基本配置完成,但Hadoop的安装和配置还没有开始。接下来,还需要下载Hadoop的二进制发行版,将其解压到适当目录,并配置Hadoop的相关配置文件,如`core-site.xml`、`hdfs-site.xml`、`yarn-site.xml`和`mapred-site.xml`等。这些配置包括HDFS的名称节点和数据节点、YARN资源管理器以及其他参数。同时,还需要配置环境变量,使得系统能够找到Hadoop的可执行文件。
安装过程中,还要初始化HDFS文件系统,并启动Hadoop的相关守护进程,如NameNode、DataNode、ResourceManager和NodeManager等。最后,进行集群测试,确保所有节点能正常通信并执行Hadoop任务。
整个Hadoop安装过程涉及多个步骤,每一步都需要仔细操作和配置,以确保集群的稳定运行。由于Hadoop是一个分布式计算框架,其安装和配置过程相对复杂,因此需要耐心和对Linux及Hadoop基础知识的理解。
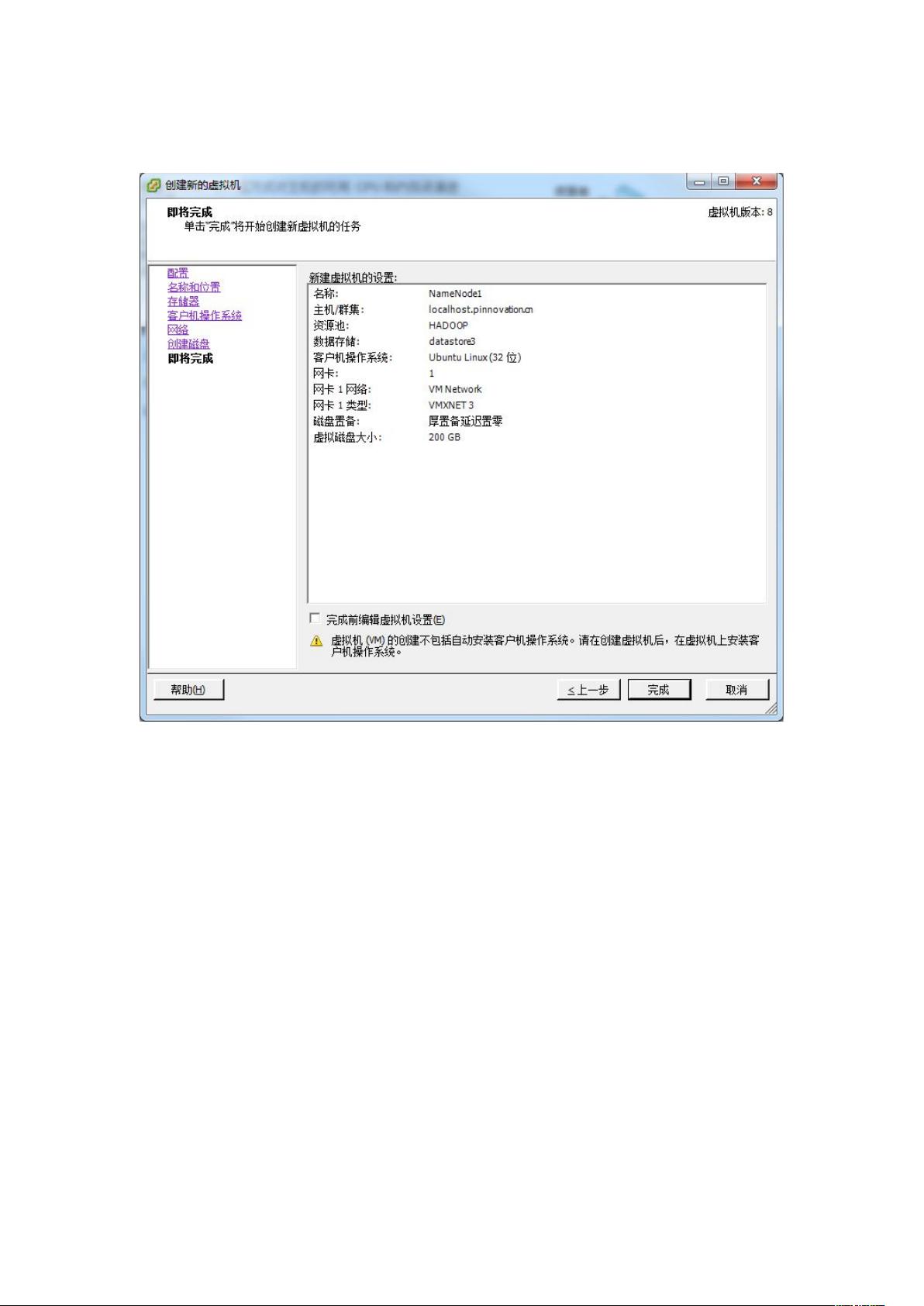
确定没有问题后,单击完成
剩余40页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-03-07 上传
2024-06-13 上传
2024-03-31 上传
2023-06-10 上传









