Kettle7.1大数据插件源码完整构建与配置指南
需积分: 9 156 浏览量
更新于2024-08-04
收藏 343KB DOCX 举报
"kettle7.1大数据插件源码依赖全解决 另附插件源码配置文档"
本文将详细解析Kettle 7.1大数据插件源码的依赖问题及配置过程,帮助开发者顺利进行大数据处理工作。Kettle,又称Pentaho Data Integration (PDI),是一个强大的ETL(数据抽取、转换、加载)工具,广泛应用于大数据集成场景。在处理大数据时,正确配置插件源码和解决依赖关系至关重要。
1. **解压源码**:
开始前,你需要下载并解压缩Kettle 7.1大数据插件的源代码。确保你使用的解压工具能够完整地处理文件,避免因解压问题导致后续步骤出错。
2. **配置setting文件**:
在源代码根目录下,找到`settings.xml`文件,这个文件通常用于存储Maven的配置信息。打开文件,你可能需要在此处配置Maven的远程仓库地址,以便从这些仓库拉取所需的依赖。
3. **添加仓库路径**:
如果你的项目依赖于特定的大数据组件,如Hadoop、Spark或HBase等,你可能需要在`settings.xml`中添加对应的仓库路径。这将使得Maven能够找到并下载这些组件的库文件。
4. **项目导入IDEA并配置Maven**:
使用IntelliJ IDEA(简称IDEA)作为开发环境,将解压后的项目导入IDEA,并确保IDEA已经配置了Maven。在IDEA中,选择File -> Settings -> Build, Execution, Deployment -> Maven,然后添加或确认Maven的本地路径与`settings.xml`文件的位置。
5. **使用GitBash**:
回到项目的根目录,通过GitBash或其他终端工具执行命令。GitBash是Windows环境下常用的命令行工具,可以方便地运行Linux命令。
6. **编译项目**:
在GitBash中输入以下命令来清理、打包项目并跳过测试阶段:
```
mvn clean package -Dmaven.test.skip=true --settings settings.xml
```
这个命令会执行Maven的生命周期,从清理旧的构建产物开始,然后打包源码为可执行的JAR或WAR文件。
7. **手动安装依赖**:
如果在编译过程中遇到无法自动下载的依赖,如`hbase-client-2.1.0-cdh6.3.2.jar`,你可能需要手动安装。使用以下命令安装:
```
mvn install:install-file -Dfile=hbase-client-2.1.0-cdh6.3.2.jar -Dpackaging=jar -DgroupId=org.apache.hbase -DartifactId=hbase-client -Dversion=3.0.0-cdh6.3.2
```
这个命令告诉Maven将指定的JAR文件作为一个新的依赖添加到本地仓库,以便项目可以引用。
8. **解决依赖冲突**:
大数据插件的开发往往涉及多个版本的组件,可能会出现依赖冲突。解决这类问题,你需要检查`pom.xml`文件中的依赖管理,确保各个组件之间的版本兼容性。
9. **测试与调试**:
完成以上步骤后,重新构建项目并运行测试,以确保所有功能正常。如果出现错误,根据错误信息定位问题,修改源码或调整配置。
10. **优化构建过程**:
为了提高构建效率,可以考虑配置Maven的缓存机制,如使用 Nexus 或 Artifactory 作为私有仓库,将常用依赖集中存储,减少网络下载时间。
通过以上步骤,你应该能成功解决Kettle 7.1大数据插件的源码依赖问题,并完成项目的构建。理解并掌握这些步骤,对于处理其他大数据项目同样具有指导意义。
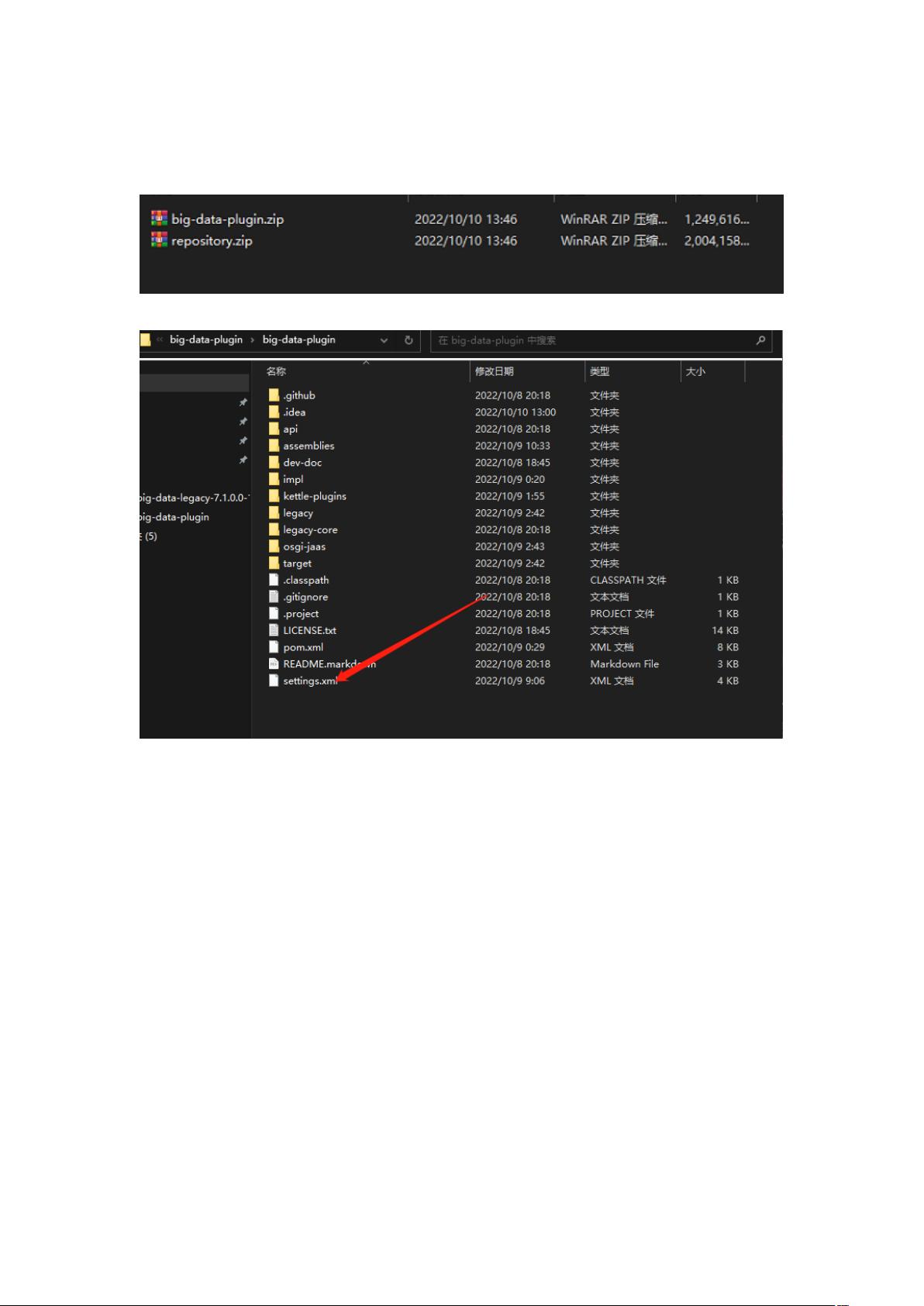
第一步解压
第二步打开 setting 文件
第三步文件添加仓库路径
下载后可阅读完整内容,剩余5页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2018-08-23 上传
216 浏览量
2018-05-21 上传
2017-12-01 上传
2019-11-08 上传
2018-07-26 上传

小明x
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 视频点播系统的设计与实现
- Liferay_Portal_4.3中文开发指南.pdf
- 基于子区域的机器人全覆盖路径规划的环境建模
- Project Darkstar属性文件配置
- LocalizingApplications_chinese.pdf
- OPCDA3.00规范
- 学习资料\实训\cvsnt2.5.03.rar
- Learning+jquery中文版.pdf
- DIV+CSS布局大全
- 变频器 基础原理知识
- 实用tcl教程,基本语法,变量,异常等处理
- Java新手入门的30个基本概念
- 视频采集与播放 windows
- ZCS半桥式DC_DC变流器状态空间法建模及Matlab仿真分析
- 开关电源PWM的五种反馈控制模式研究
- USB1.1技术规范(中文)
