C语言内排序算法详解:冒泡、选择、插入、快速等实现
需积分: 3 96 浏览量
更新于2024-08-01
收藏 131KB DOC 举报
在C语言中,内部排序算法是程序设计中常见的基础操作,用于对一组数据进行有序排列。本文档主要介绍了八种常用的排序方法,包括冒泡排序、选择排序、插入排序、快速排序、希尔排序、归并排序、堆排序以及基数排序。以下是每种排序算法的C语言实现及其详细解释。
1. **冒泡排序**:
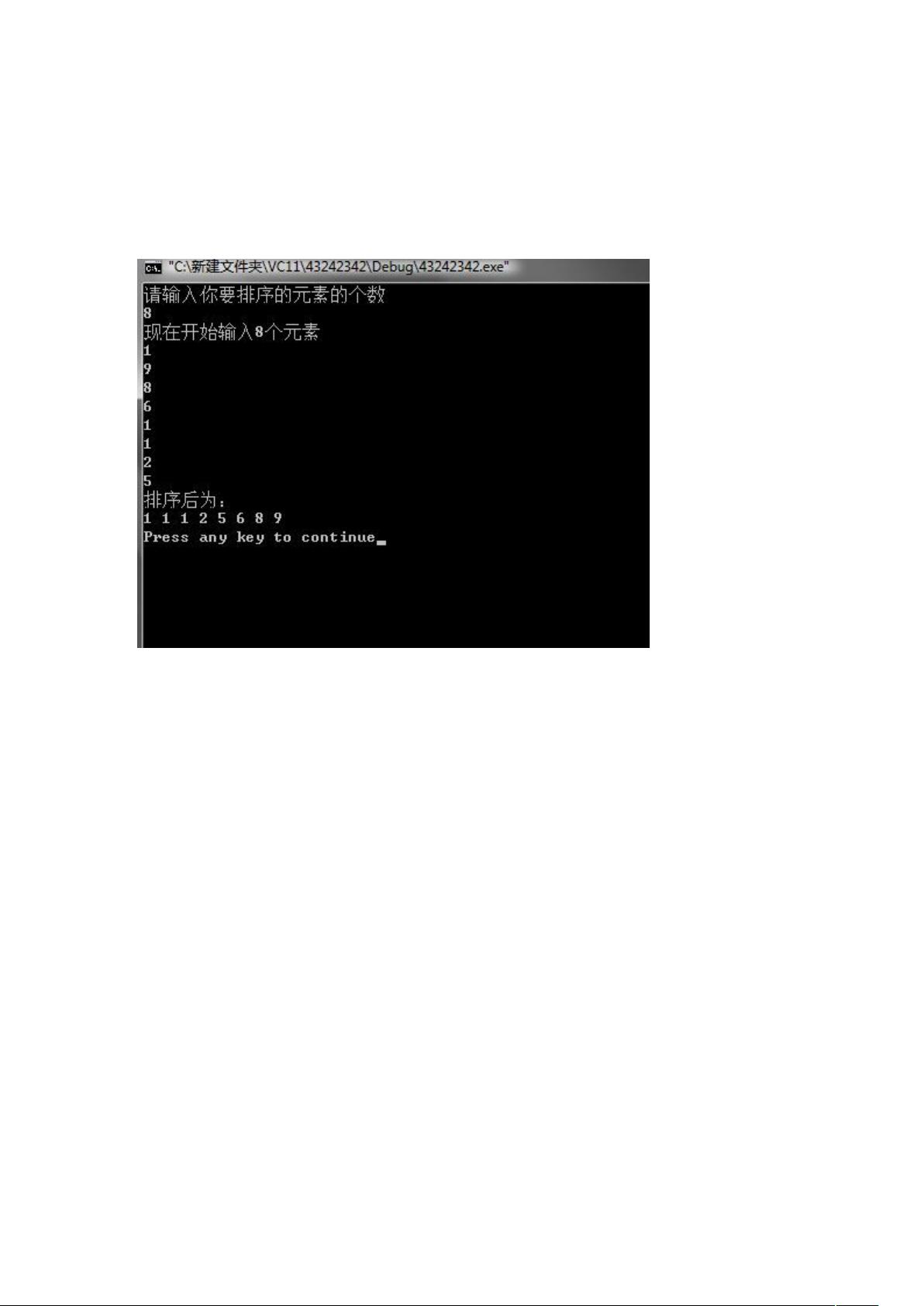
冒泡排序是一种简单的排序算法,通过重复遍历待排序的数组,比较相邻元素并交换位置,较小的元素逐渐“浮”到数组的一端。代码中定义了`mao_pao`函数,通过两个嵌套循环来实现这一过程。首先初始化一个`flag`变量记录是否有交换发生,如果没有,则表示数组已经有序,算法结束。主函数中,用户输入待排序的元素个数和数值,然后调用`mao_pao`进行排序。
2. **选择排序**:
选择排序每次从未排序的部分中找到最小(或最大)元素,并将其放到已排序部分的末尾。选择排序的`xuan_zhe`函数中,通过两个嵌套循环找到未排序部分的最大值索引,然后将该值与当前未排序部分的第一个元素交换。主函数中同样负责用户输入和释放内存。
3. **插入排序**、**快速排序**、**希尔排序**、**归并排序**、**堆排序**和**基数排序**:
这些排序算法各自有其特点和复杂度。插入排序是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。快速排序是一种分治算法,通过选取一个基准元素,将数组分为两部分,一部分小于基准,一部分大于基准,递归地对这两部分进行排序。希尔排序是对插入排序的一种改进,通过设置增量序列来优化排序过程。归并排序是稳定的,将数组分成两半,分别排序后再合并。堆排序利用堆数据结构实现,具有较高的效率。基数排序则是非比较排序,适用于整数数组,按照位数进行逐次排序。
以上这些排序算法都是C语言中的经典实现,学习者可以通过对比它们的代码结构和时间复杂度,理解不同排序方法的特点和适用场景。掌握这些基本的排序算法对于深入理解计算机科学基础和优化程序性能至关重要。通过实践编写和调试这些代码,可以提高编程技能,并在实际项目中灵活运用。
*) 565#(
)* #(
1
;,插入排序
* !"#
$
"%"(
)* +((--#
$
+/-0(
)* %+(%+,,/%0(%#
/%-0+/%0(
/--%0+(
1
1
剩余15页未读,继续阅读
131 浏览量
1261 浏览量
2021-07-14 上传
2022-07-08 上传
2022-06-14 上传
2014-11-04 上传
2022-06-20 上传
2011-03-01 上传

franky_1984
- 粉丝: 0
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- 软件能力成熟度模型 软件工程
- 连续刚构桥外文文献(Stability Analysis of Long-Span Continuous Rigid Frame Bridge with Thin-Wall Pier)
- 网络管理不可或缺的十本手册
- JAVA设计模式.pdf
- ucosii实时操作系统word版本
- 英语词汇逻辑记忆法WORD
- 《开源》旗舰电子杂志2008年第7期
- 图书馆管理系统UML建模作业
- struts2权威指南
- jdk+tomcat+jfreechart+sql_server2000安装心得
- 40个单片机汇编和C程序
- 嵌入式linux系统开发技术详解
- quartus使用手册
- struts2教程英文版
- 虚拟串口软件驱动设计文档
- C++内存分配的对齐规则
