北京大学NLP课程:信息检索基础与文本挖掘
版权申诉
124 浏览量
更新于2024-07-04
收藏 3.46MB PDF 举报
"互联网数据挖掘课程 北大NLP课程-自然语言处理系列课程 第02章 信息检索基础(一) 文本信息检索 共80页.pdf"
本课程是北京大学自然语言处理(NLP)课程的一部分,专注于介绍信息检索的基础知识,特别是文本信息检索。课程适合对NLP感兴趣的初学者或希望巩固知识的学习者。课件内容详实,逐步引导学生深入理解相关概念。
信息检索是一个普遍存在于日常生活中的行为,从简单的书包查找到复杂的图书馆文献检索,它的发展经历了从早期的手工卡片检索到现代的计算机数据库检索。早期的信息检索基于物理卡片目录,随着技术进步,演变为基于数据库的电子检索系统,大大提高了检索效率。
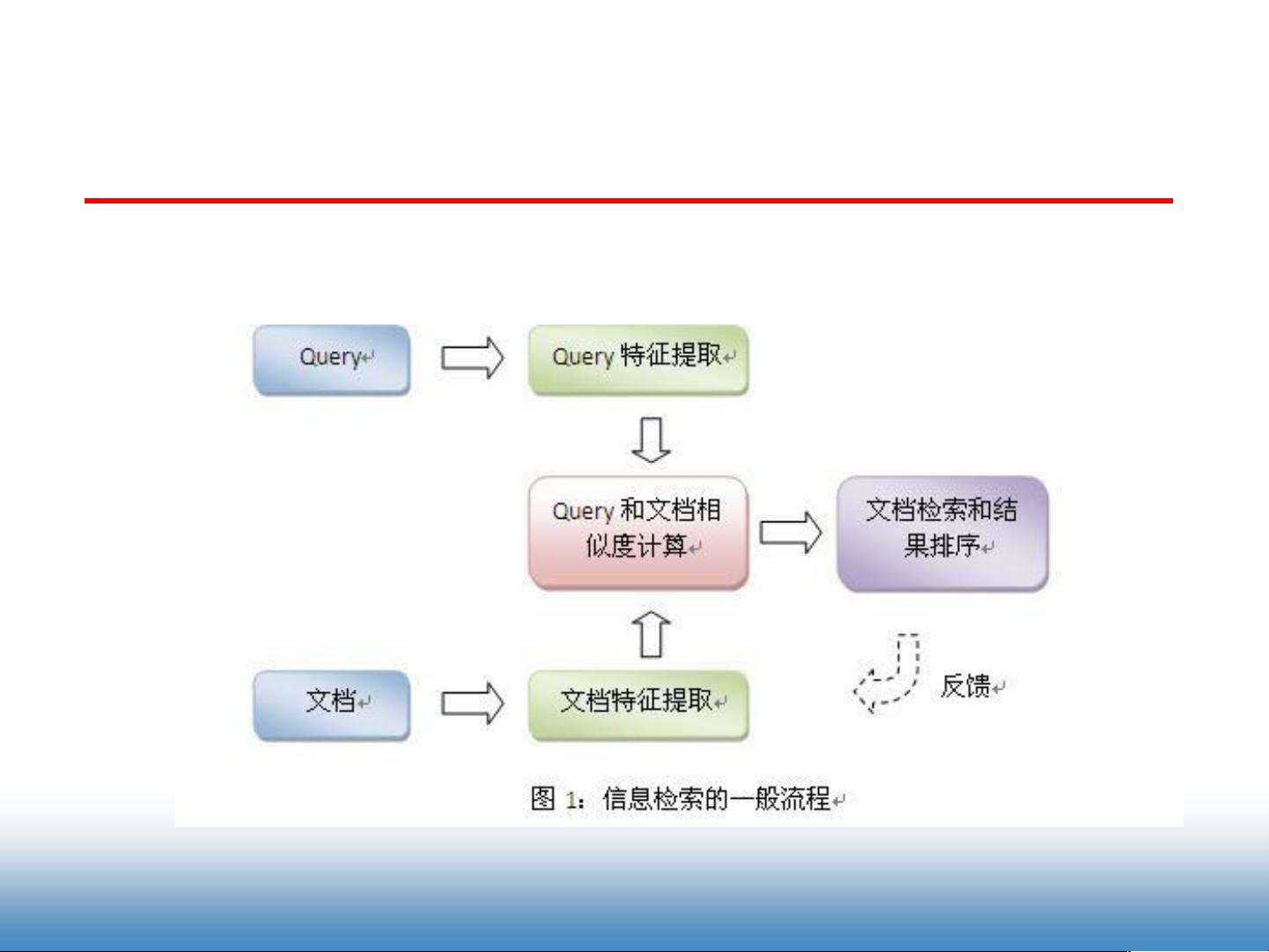
信息检索可分为广义和狭义两种。广义上,它涵盖了信息的存储、组织和检索;狭义上,主要关注从信息集合中快速找到所需信息的过程。文本信息检索作为其重要分支,主要处理和分析文本数据,如通过关键词查询来匹配文档。
文本信息检索的核心问题包括效果和效率。效果涉及到如何准确匹配查询和文档,这通常基于各种检索模型;而效率则关注如何快速返回检索结果,这依赖于有效的索引机制。文档可以由元描述(如作者、标题和日期)来表示,这种方法依赖于人工标注,虽然准确但耗时。为解决这一问题,出现了词袋模型(Bag-of-Words),它忽略了词语顺序,只考虑词频,通过词干提取和词形还原等方法减少词汇形态的影响,从而简化文档表示。
在实际操作中,词袋模型会先进行符号化和词语形态规范化处理,如区分大小写,去除词缀以得到词根。这些步骤对于构建索引和执行查询至关重要,它们帮助系统在大量文本数据中快速定位相关文档。
此外,课程可能还会涉及其他类型的检索,如Web检索、数据库检索以及多媒体检索(图像、视频、音乐等)。信息检索技术在互联网时代有着广泛应用,如搜索引擎、智能问答系统、情感分析和信息推荐等,这些都依赖于高效、精准的信息检索策略。
通过本课程的学习,学生将能够理解和掌握信息检索的基本原理和技术,为深入研究自然语言处理和数据挖掘打下坚实基础。


点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-04-26 上传
690 浏览量
357 浏览量
258 浏览量
155 浏览量
2021-09-29 上传

passionSnail
- 粉丝: 476
 我的内容管理
展开
我的内容管理
展开







最新资源
- S3C2440上运行的UCOS-II操作系统开发代码
- Java完整文件上传下载demo解析
- Angular 8+黄金布局集成方案:ng6-golden-layout概述
- 科因网络OA:党政机关全方位信息化解决方案
- Linux下LAMP环境与PHP网站搭建指南
- 新语聊天系统:ASP.NET C# 实现的WebChat
- 中国移动专线拨测工具:高效测试数据与互联网线路
- AT89S52单片机直流电源设计:原理图、程序及详解
- 深入掌握WPF与C# 2010编程技术
- C#初学者百例实例程序解析
- express-mongo-sanitize中间件:防止MongoDB注入攻击
- 揭秘精品课程源码:提升教育质量的秘密武器
- 中文版SC系列OTP语音芯片特性详解
- Lombok插件0.23版发布,提高开发效率
- WebTerminal:InterSystems数据平台的全新Web终端体验
- 多功能STM32数字时钟设计:全技术栈项目资源分享
