使用Keras进行图像预处理与生成数据生成器
176 浏览量
更新于2024-08-30
收藏 164KB PDF 举报
"该资源是一个使用Keras库实现图像预处理和生成数据生成器的案例。作者通过建立特定的目录结构来存储图像,然后利用`ImageDataGenerator`进行数据增强,包括调整像素值、随机旋转、水平翻转等操作。接着,代码创建了训练集和验证集的数据生成器,用于在模型训练过程中按批次读取图像。模型训练时,使用`fit_generator`方法配合保存最佳权重的回调函数`ModelCheckpoint`。"
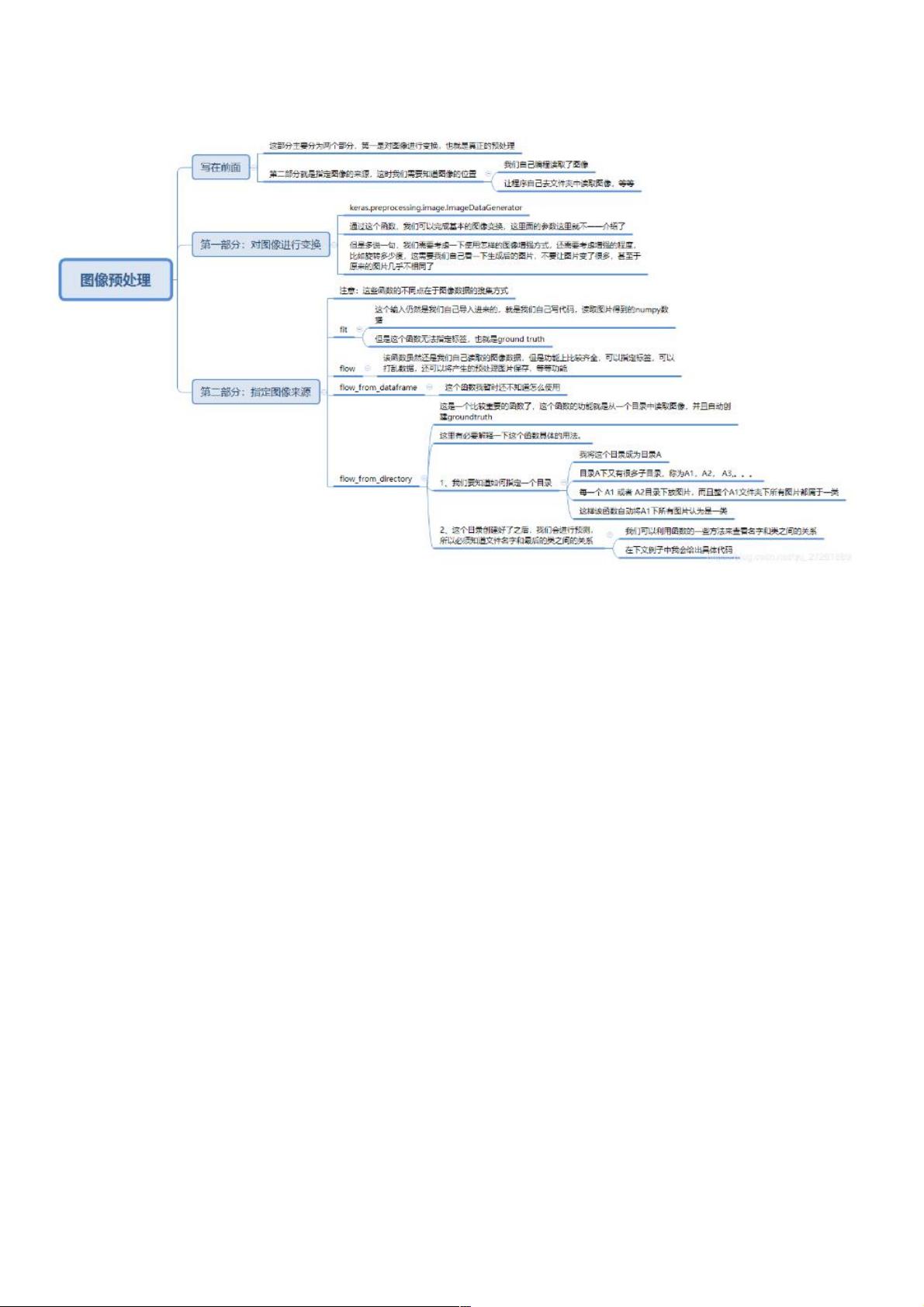
在机器学习领域,尤其是深度学习应用于图像识别时,预处理和数据扩增是非常重要的步骤。Keras库提供了一个强大的工具——`ImageDataGenerator`,用于处理这些任务。在这个案例中,我们看到了如何利用`ImageDataGenerator`来预处理图像并生成数据生成器。
首先,预处理是将图像的像素值归一化到0到1之间,这可以通过设置`rescale=1./255`来实现。这样做有助于神经网络更快地收敛。除此之外,还使用了`rotation_range=50`来允许图像在50度的范围内随机旋转,增加图像多样性。`height_shift_range`和`width_shift_range`参数允许图像在垂直和水平方向上进行小范围的位移,`horizontal_flip=True`则表示图像可能会被随机水平翻转,这些都是数据增强的常见手段,可以防止模型过拟合,提高泛化能力。
然后,通过`flow_from_directory`方法,`ImageDataGenerator`可以从指定的目录读取图像,这里分为训练集和验证集。`target_size=(height, width)`确保所有图像被调整到相同的尺寸,`batch_size`定义了每个批次中包含的样本数量,对于训练集是16,验证集是64。
在模型训练阶段,`fit_generator`函数接收`train_generator`作为输入,它会按照设定的`steps_per_epoch`遍历整个训练集。`epochs=300`表示模型将训练300个周期。同时,`ModelCheckpoint`回调函数用于在验证损失下降时保存模型的最佳权重,这有助于在训练过程中捕获模型的最优性能。
总结来说,这个案例展示了如何在Keras中高效地进行图像预处理和数据扩增,以及如何使用数据生成器训练深度学习模型,这对于处理大规模图像数据集是非常实用的。通过这种方式,我们可以有效地提升模型的性能,同时减少对内存的需求。
keras实现图像预处理并生成一个实现图像预处理并生成一个generator的案例的案例
如下所示:
接下来,给出我自己目前积累的代码,从目录中自动读取图像,并产生generator:
第一步:建立好目录结构和图像第一步:建立好目录结构和图像
下载后可阅读完整内容,剩余4页未读,立即下载
188 浏览量
141 浏览量
点击了解资源详情
123 浏览量
点击了解资源详情
点击了解资源详情
147 浏览量
点击了解资源详情
133 浏览量

抹蜜茶
- 粉丝: 303
- 资源: 935
 我的内容管理
展开
我的内容管理
展开







最新资源
- QT 3.3 中文白皮书.pdf
- CMMI能力成熟度模型1.2版
- 信息系统项目管理师讲义
- 做PPT的技巧 doc !
- 想成为嵌入式程序员应知道的0x10个基本问题
- oracle 031 ppt les04 ppt
- 高质量C、C++编程指南
- oracle 031 ppt les02 ppt
- 不错的网上书店文档自己做个人项目的时候整理的
- oracle 031 ppt les01 ppt
- Springer.Algorithms.And.Data.Structures
- MATLABstudy.doc
- 《卓有成效的程序员》迷你书
- JavaScript 语言精髓与编程实践迷你书
- 正则表达式基础知识与常用类型
- 2006南开上机100题
