使用Keras进行图像预处理与生成器构建教程
113 浏览量
更新于2024-09-01
收藏 163KB PDF 举报
"本文将介绍如何使用Keras库在Python中进行图像预处理,并创建一个数据生成器(generator),这对于大规模图像数据集的训练尤为重要。Keras的`ImageDataGenerator`类提供了一系列方法来对图像进行随机变换,以增强训练数据的多样性。"
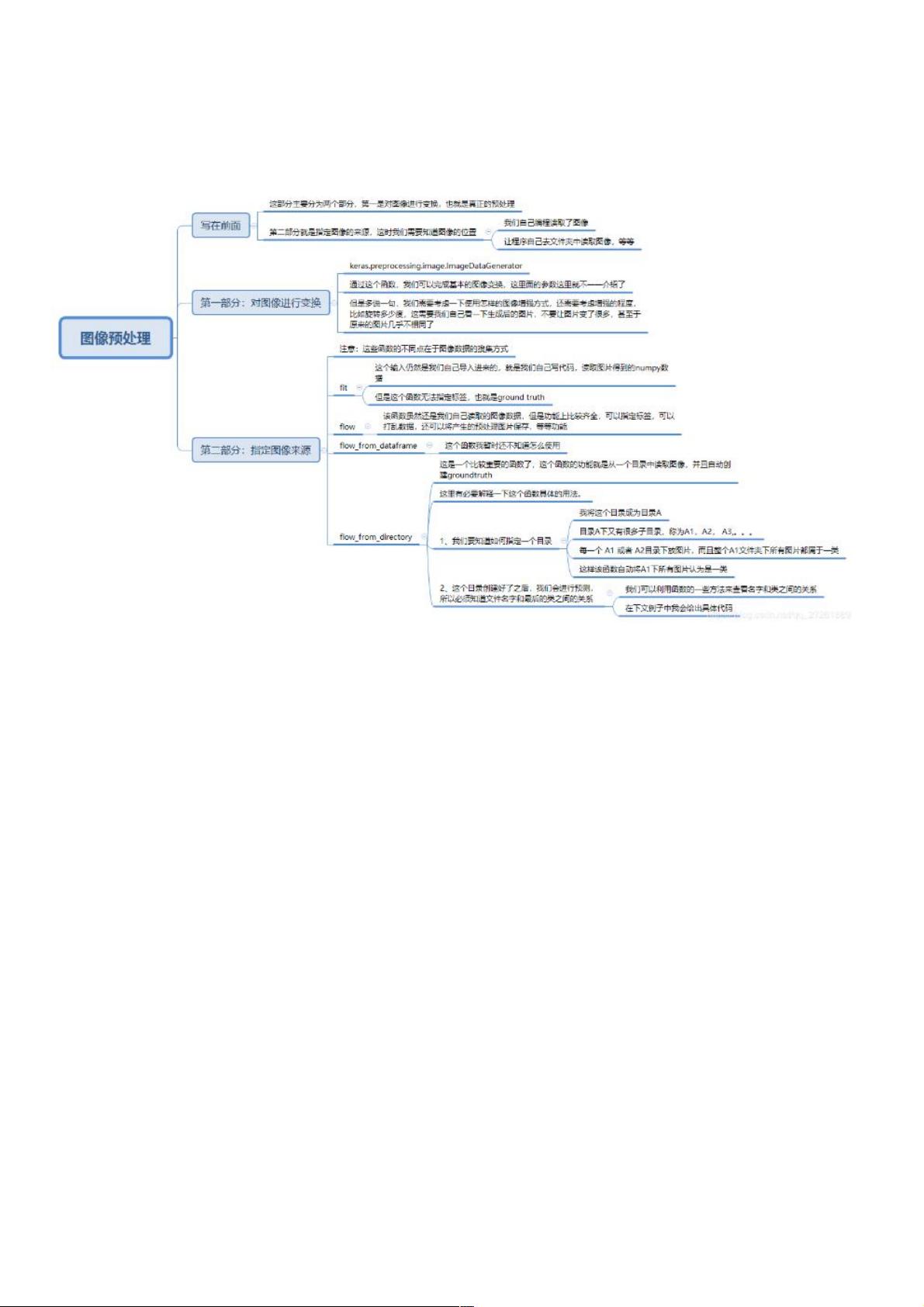
在机器学习,特别是深度学习中,图像预处理是至关重要的步骤,它能够帮助模型更好地理解和学习图像特征。Keras库提供了一个强大的工具`ImageDataGenerator`,它可以生成带有时域变化的图像批次,用于增强训练数据。这包括但不限于调整图像的亮度、对比度、旋转、平移以及水平翻转等。
首先,我们来看如何构建一个`ImageDataGenerator`实例。在这个案例中,预处理步骤包括:
1. `rescale=1./255`: 这一步是将图像的像素值归一化到0-1之间,通常是对所有图像处理的常见步骤。
2. `rotation_range=50`: 允许图像随机旋转最大50度,增加数据的多样性。
3. `height_shift_range`和`width_shift_range`:允许图像在高度和宽度方向上随机偏移,数值范围是[-0.005, 0, 0.005],表示图像可以在每个维度上随机移动最多0.5%的距离。
4. `horizontal_flip=True`: 图像可能会被随机水平翻转,模拟不同的观察角度。
5. `fill_mode='reflect'`: 当图像边界外的像素需要填充时,使用反射填充方式。
创建好预处理实例后,我们使用`flow_from_directory`方法从指定的目录加载图像。这个方法会根据目录结构自动将图像分类。例如,这里的`'AgriculturalDisease_trainingset/images_keras_dict'`和`'AgriculturalDisease_validationset/images_keras_dict'`分别用于训练和验证数据。
`target_size=(height, width)`定义了输入模型的图像尺寸,而`batch_size`指定了每次迭代时处理的图像数量。在这里,训练数据的批量大小为16,验证数据的批量大小为64。
为了保存训练过程中性能最好的模型权重,可以使用`ModelCheckpoint`回调函数。`filepath='models/best_weights.hdf5'`指定了权重文件的保存路径,`monitor='val_loss'`意味着监控验证集上的损失,如果发现验证损失下降,就会保存当前权重。`save_best_only=True`确保只保存最优模型。
最后,`model.fit_generator`方法调用生成器`train_generator`进行训练。通过这种方式,我们可以高效地处理大量图像,而无需一次性加载所有数据到内存中,这对于内存有限的环境特别有用。
总结来说,Keras的`ImageDataGenerator`和数据生成器是处理和训练大规模图像数据的有效工具,它们不仅可以提高模型的泛化能力,还能有效利用计算资源。这个案例中的代码示例展示了如何设置预处理参数、创建生成器以及训练模型,对于理解Keras图像处理流程具有很高的参考价值。
keras实现图像预处理并生成一个实现图像预处理并生成一个generator的案例的案例
主要介绍了keras实现图像预处理并生成一个generator的案例,具有很好的参考价值,希望对大家有所帮助。一
起跟随小编过来看看吧
如下所示:
接下来,给出我自己目前积累的代码,从目录中自动读取图像,并产生generator:
第一步:建立好目录结构和图像第一步:建立好目录结构和图像
下载后可阅读完整内容,剩余4页未读,立即下载
292 浏览量
193 浏览量
128 浏览量
146 浏览量
133 浏览量
313 浏览量
点击了解资源详情
155 浏览量
点击了解资源详情

weixin_38529251
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- Web远程教学系统需求分析指南
- 禅道6.2版本发布,优化测试流程,提高安全性
- Netty传输层API中文文档及资源包免费下载
- 超凡搜索:引领搜索领域的创新神器
- JavaWeb租房系统实现与代码参考指南
- 老冀文章编辑工具v1.8:文章编辑的自动化解决方案
- MovieLens 1m数据集深度解析:数据库设计与电影属性
- TypeScript实现tca-flip-coins模拟硬币翻转算法
- Directshow实现多路视频采集与传输技术
- 百度editor实现无限制附件上传功能
- C语言二级上机模拟题与VC6.0完整版
- A*算法解决八数码问题:AI领域的经典案例
- Android版SeetaFace JNI程序实现人脸检测与对齐
- 热交换器效率提升技术手册
- WinCE平台CPU占用率精确测试工具介绍
- JavaScript实现的压缩包子算法解读
