云计算平台的Hypertable:分布式结构化数据存储解决方案
139 浏览量
更新于2024-08-28
收藏 1.17MB PDF 举报
"Hypertable是一个基于C++开发的开源分布式数据存储系统,设计灵感来源于Google的Bigtable。它旨在处理大规模的结构化数据,提供高效、可靠且可扩展的数据存储解决方案。Hypertable通过分布式并行文件系统(如GFS、HDFS、KFS)来存储数据,并构建在其上的分布式结构化数据组织,使得PB级别的数据能够以表格形式进行管理和访问,同时提供了类似SQL的接口供应用程序使用。
在Hypertable的数据模型中,数据被组织成一个多维稀疏矩阵,这类似于表格结构。每一行(Row)由一个唯一的行键(RowKey)标识,这个键是一个可自定义的字符序列,最长可达64Kbyte。行按照RowKey的字典顺序排列。数据的第二维度是列族(ColumnFamily),列族是一组具有相同属性的列(ColumnQualifier)集合。列族内的列数量没有限制,命名通常以`family:qualifier`的形式表示。时间戳(Timestamp)作为第四维度,用于区分同一行同一列在不同时间点的值,系统会在插入数据时自动为其分配。
Hypertable的数据操作原子性强,对行的插入、更新和删除都能保证一致性。其设计目标是提供高可用性和可伸缩性,这意味着随着数据量的增长,Hypertable可以通过增加更多的计算节点来扩展其存储和处理能力,同时保持服务的不间断。
Hypertable的架构允许水平扩展,这意味着它可以轻松地在成千上万的计算主机上运行,以应对云计算平台的需求。它通过分布式算法确保数据的复制和容错,即使部分节点故障,系统也能继续正常工作。此外,Hypertable支持多版本并发控制(MVCC),这使得多个并发读写操作可以并行执行,而不会相互干扰,从而提高系统的吞吐量。
Hypertable的接口设计考虑了易用性,尽管它不完全支持关系数据库的所有特性,但提供了类似SQL的查询方式,让开发者可以方便地与数据进行交互。这使得Hypertable成为那些需要处理大量结构化数据但又希望避免传统数据库复杂性的应用程序的理想选择。
总结来说,Hypertable作为一个高效的分布式数据存储系统,利用其独特的数据模型和架构,能够有效地处理大规模的结构化数据,同时提供灵活的查询和强大的扩展性,是应对云计算时代大数据挑战的一个有力工具。"
Hypertable简介简介(一个一个C++的的Bigtable开源实现开源实现)
1.Introduction
随着互联网技术的发展,尤其是云计算平台的出现,分布式应用程序需要处理大量的数据(PB级)。在一个或多个云计算平台中
(成千上万的计算主机),如何保证数据的有效存储和组织,为应用提供高效和可靠的访问接口,并且保持良好的伸缩性和可扩
展性,成为云计算平台需要解决的关键问题之一。分布式并行文件系统,为云计算平台解决了海量数据存储问题,并且提供了
统一的文件系统命令空间,如GFS、Hadoop HDFS、KFS等,在此基础上, Hypertable实现了分布式结构化的数据组
织,Hypertable可以对海量的结构化的数据(PB级)提供面向表形式的组织方式,并向应用提供类似表访问的接口(如SQL接口)
2 Structured Data and Tablet Location
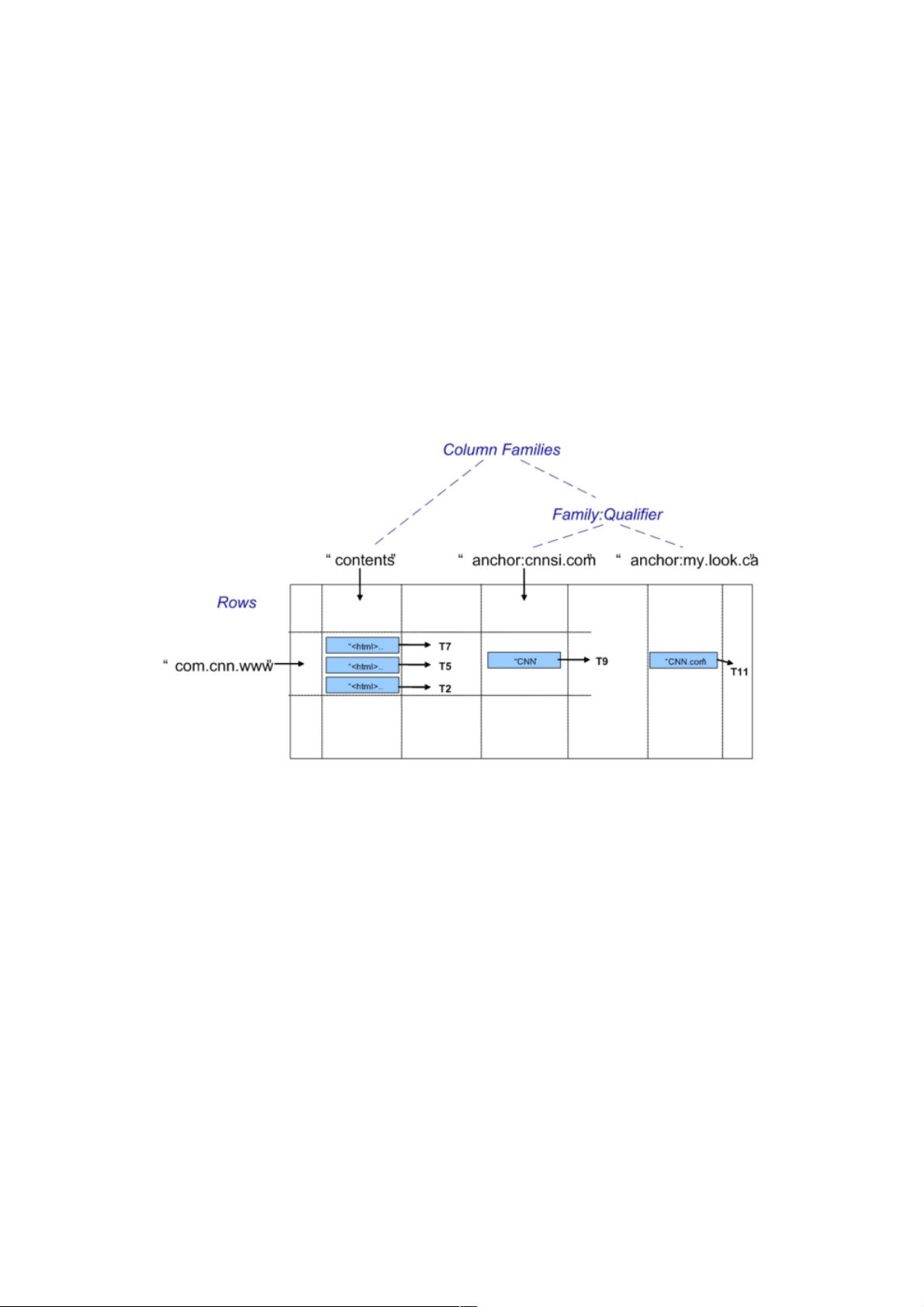
2.1 数据模型(Data Model)
Hypertable采用类似表的形式组织数据,但目前Hypertable并不支持关系数据库中丰富的关系属性。Hypertable将数据组织成
一个多维稀疏矩阵。该矩阵中的所有行信息可以基于主键(Primary Key)进行排序。在该多维矩阵中第一维称为行
(Row),行键值(Row Key)即为Primary Key;第二维即列族(Column Family),一个列族包含多个列(Column
Qualifier)的集合,它们一般具有相同的类型属性,系统在存储和访问表时,都是以Column Family为单元组织;第三维即列
(Column Qualifier),理论上,一个列族中列的个数不受限制,列的命名方式通常采用family:qualifier的方式;最后一维就是
时间戳(Timetstamp),它通常是系统在插入一项数据时自动赋予。如果我们把行和列族看成三维矩阵的行和列,那么我们
可以将“时间戳”看成是纵向深度坐标。如图2-1所示,Tn就是每项值(Value)的“深度”标签。
Figure 2-1 A Multi-Dimensional Table
2.1.1 行键(Row Key)
Hypertable中Row Key定义为任意的字符序列(长度不超过64Kbyte,通常的应用也就百个字节左右),所有行以Row key为
主键进行字典排序。在Hypertable中队行的操作保持原子性,对行的插入(Insert)、更新(Update)、删除(Delete)等都
保持整行的原子操作,无论行操作涉及到的列的个数。在Hypertable中保持行操作的原子性,对应用程序来说显然具有积极的
意义,它使得Hypertable对应用程序来说,行的一致性得到保证。
在Hypertable中,所有的行数据按照Row Key的字典序排列,如图2-1,随着数据量的不断增长(不断的有新的数据插入),
该多维数据表会不断增长,在一个并行的云计算平台中,当该表增长到一定大小时,系统会将该表一分为二,分别由平台中不
同的主机维护,分裂后的表可以独立增长,再进行分裂,由此反复,最终一个多维的Hypertable表实际上是以大量的“小表
(Tablet)”的形式存在于云计算平台中,它们具有完全对等的属性,分别维护表中的部分数据;一个小表(Tablet)由一台主
机维护,一台主机可以维护多个小表。在Hypertable中,表的分裂沿行区间(Row Range)切分,如图2-2所示,一张表在生
长过程中,在一定的行区间被分裂为多个行区间(Row Range),每一个行区间成文一个新的小表(Tablet)。在Hypertable
中缺省是一个Tablet增长到200M左右分裂,同时由于系统在并行处理平台上运行,会根据负载均衡原则进行调解。在云计算
平台中,分裂出来的Tablet基于Load Balance原则被分布在不同的主机上维护,从而,对表的操作演化成对各小表(Tablet)
的操作,处理效率显然高于对整个大表的操作。用户在使用Hypertable时合理的选择Row Key,可以得到更好的数据处理效
率。例如在处理大量网页数据时(网页crawler获取的网页数据),通常把网页URL作为Row Key,其中URL的主机域名被反
序处理(如maps.google.com/index.html被反置为com.google.maps/index.html),如此具有相同域的网页被尽可能的组织在
相同或相邻的Tablet中,因此应用程序在处理这些数据时能得到更好的效率。
下载后可阅读完整内容,剩余9页未读,立即下载
点击了解资源详情
点击了解资源详情
2012-04-19 上传
2013-07-22 上传
2012-04-24 上传
2015-08-04 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38635449
- 粉丝: 5
- 资源: 971
 我的内容管理
展开
我的内容管理
展开







最新资源
- 基于Python和Opencv的车牌识别系统实现
- 我的代码小部件库:统计、MySQL操作与树结构功能
- React初学者入门指南:快速构建并部署你的第一个应用
- Oddish:夜潜CSGO皮肤,智能爬虫技术解析
- 利用REST HaProxy实现haproxy.cfg配置的HTTP接口化
- LeetCode用例构造实践:CMake和GoogleTest的应用
- 快速搭建vulhub靶场:简化docker-compose与vulhub-master下载
- 天秤座术语表:glossariolibras项目安装与使用指南
- 从Vercel到Firebase的全栈Amazon克隆项目指南
- ANU PK大楼Studio 1的3D声效和Ambisonic技术体验
- C#实现的鼠标事件功能演示
- 掌握DP-10:LeetCode超级掉蛋与爆破气球
- C与SDL开发的游戏如何编译至WebAssembly平台
- CastorDOC开源应用程序:文档管理功能与Alfresco集成
- LeetCode用例构造与计算机科学基础:数据结构与设计模式
- 通过travis-nightly-builder实现自动化API与Rake任务构建
