Hadoop源码深度解析:HDFS与MapReduce核心组件
需积分: 9 13 浏览量
更新于2024-07-29
1
收藏 6.2MB PDF 举报
Hadoop源码分析深入探讨了Google的分布式计算技术在开源社区的发展,特别是其核心组件HDFS和MapReduce。Hadoop源于Google Cluster、Chubby、GFS、BigTable和MapReduce等技术,其中Chubby被Apache的ZooKeeper所继承,GFS演变为Hadoop Distributed File System (HDFS),BigTable的开源版本是HBase,而MapReduce则成为Hadoop的主要计算模型。
HDFS是Hadoop生态系统的基础,作为分布式文件系统,它负责存储大规模数据并提供高可用性和容错性。HDFS的设计使得它能够处理大量数据,适合批量处理和数据分析场景。在Hadoop的顶层包图中,依赖关系复杂,反映了HDFS的分布式特性以及与底层系统交互的灵活性。例如,包conf依赖于fs,因为系统配置的读取需要文件系统支持,这种设计允许HDFS无缝集成各种存储解决方案。
Hadoop的关键部分集中在图中的蓝色区域,主要包括HDFS和MapReduce框架。HDFS的组件包括NameNode(主节点)和DataNode(数据节点),前者管理文件系统的元数据,后者存储实际的数据块。MapReduce则由Mapper、Reducer和JobTracker组成,提供了编程模型来执行并行计算任务,将复杂的任务分解为一系列小的子任务。
深入Hadoop源码分析不仅有助于理解分布式计算的工作原理,还能洞察其优化策略,如数据块复制、数据块调度和容错机制。此外,理解MapReduce的Shuffle和Sort-Reduce过程对性能优化至关重要。通过学习Hadoop源码,开发者可以更好地利用其在大数据处理和云计算领域的优势,并根据具体需求进行定制或扩展。
在后续的分析中,将深入剖析Hadoop的工具包,如工具模块(如DistCp和archive),以及MapReduce的编程接口,包括InputFormat、OutputFormat、Mapper和Reducer接口的实现细节。通过这些分析,读者可以全面掌握Hadoop的运作机制和应用实践,为进一步的开发和优化奠定坚实基础。

(为了简单起见,BlockSender 和 BlockReceiver 的成员变量没有进入 UML 模型中)
DataXceiverServer 很简单,它打开一个端口,然后每接收到一个连接,就创建一个 DataXceiver,服务于该连接,并记录该连
接的 socket,对应的实现在 DataXceiverServer 的 run 方法里。当系统关闭时,DataXceiverServer 将关闭监听的 socket 和所
有 DataXceiver 的 socket,这样就导致了 DataXceiver 出错并结束线程。
DataXceiver 才是真正干活的地方,目前,DataXceiver 支持的操作总共有六条,分别是:
OP_WRITE_BLOCK (80):写数据块
OP_READ_BLOCK (81):读数据块
OP_READ_METADATA (82):读数据块元文件
OP_REPLACE_BLOCK (83):替换一个数据块
OP_COPY_BLOCK (84):拷贝一个数据块
OP_BLOCK_CHECKSUM (85):读数据块检验码
DataXceiver 首先读取客户端的版本号并检验,然后再读取一个字节的操作码,并转入相关的子程序进行处理。我们先看一下
读数据块的过程吧。
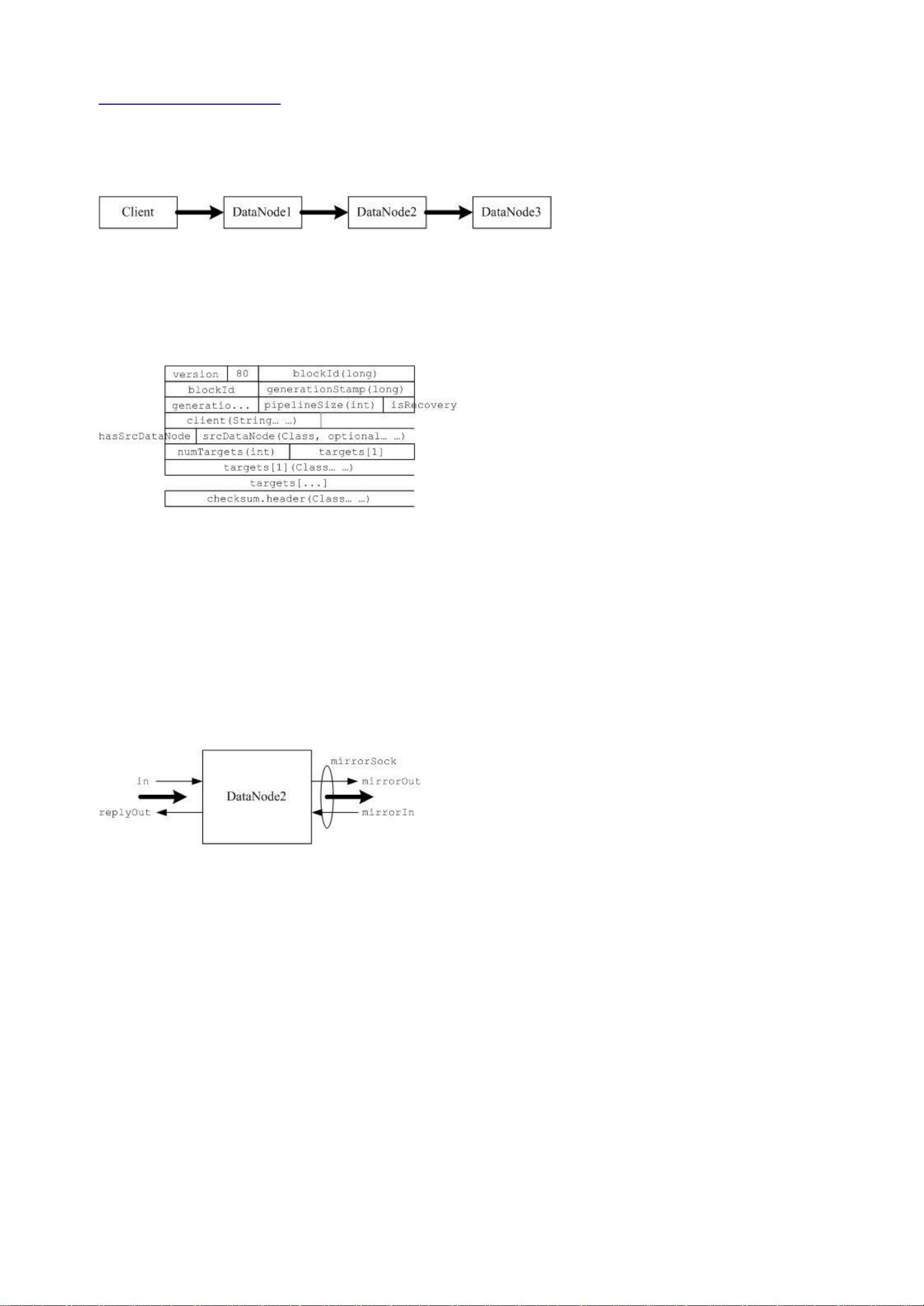
首先看输入,下图是读数据块时,客户端发送过来的信息:
包括了要读取的 Block 的 ID,时间戳,开始偏移和读取的长度,最后是客户端的名字(貌似只是在写日志的时候用到了)。根
据上面的信息,我们可以创建一个 BlockSender,如果 BlockSender 没有出错,返回客户端一个正确指示后,否则,返回错误
码。成功创建 BlockSender 以后,就可以开始通过 BlockSender.sendBlock 发送数据。
下面我们就来分析 BlockSender。BlockSender 的构造函数看似很复杂,其实就是根据需求(特别是在处理 checksum 上,因为
checksum 是基于块的),打开相应的数据流。close()用于释放各种资源,如已经打开的数据流。sendBlock 用于发送数据,数
据发送包括应答头和后续的数据包。应答头如下(包含 DataXceiver 中发送的成功标识):
然后后面的数据就组织成数据包来发送,包结构如下:
各个字段含义:
packetLen:包长度,包括包头
offset:偏移量
seqno:包序列号
tail:是否是最后一个包
len:数据长度
checksum:检验数据
data:数据块数据
需要注意的,在写数据前,BlockSender 会校验数据,保证数据包中的 checksum 和数据的一致性。同时,如果数据出错,将会
有 ChecksumException 抛出。
数据传输结束的标志,是一个 packetLen 长度为 0 的包。客户端可以返回一个两字节的应答
OP_STATUS_CHECKSUM_OK
(5)


剩余82页未读,继续阅读
306 浏览量
2024-06-23 上传
2022-08-05 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

ccqjs
- 粉丝: 1
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- Sniffer学习手册中文版.pdf
- matlab图形图像处理函数
- 计算机类--电脑维修的基本方法
- 生活水泵电气控制课程设计
- 交换环境下的ARP欺骗和Sniffer
- ActionScript 3.0 Cookbook 中文完整版(翻译版).pdf
- Practical Apache Struts2 Web 2.0 Projects
- Thinking.In.Java.3rd.Edition.Chinese.eBook-YSSY.txt
- JAVA课程复习试题
- MXC6202GHMN-MEMSIC
- JSP数据库编程指南.pdf
- HTML学习:css命名规则
- 电子密码锁设计电子密码锁设计
- 指法练习软件需求说明书
- 基于ATmega16L 单片机的六路抢答器设计
- 指纹识别系统 超经典 绝对
