
A. Shaqour
等人
能源与人工智能
8
(
2022
)
100141
4
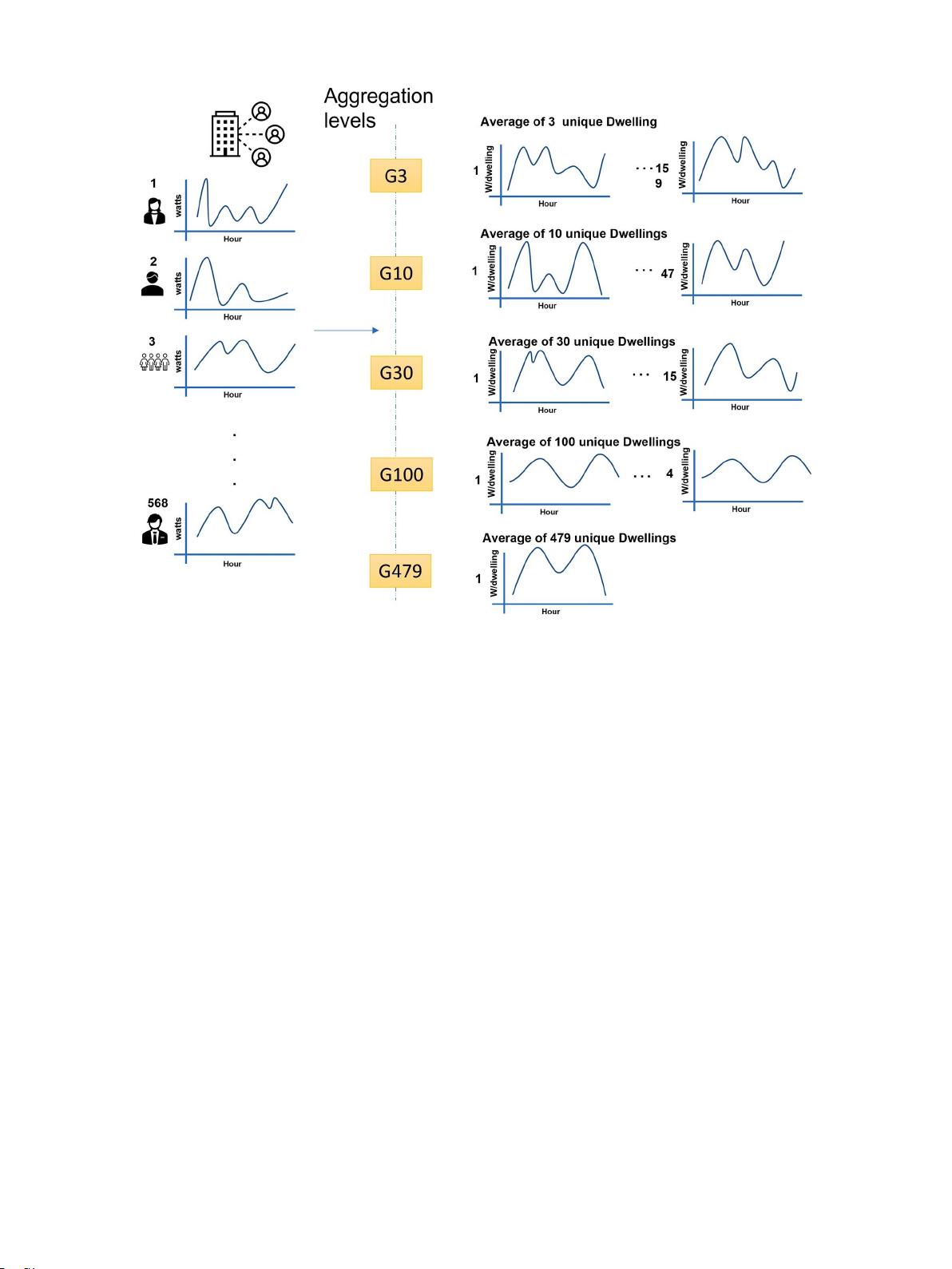
图1.一、
多级聚合及其各自的 子集。
澳大利亚政府的智能电网城市项目(SGSC)。他们的算法被应用到一个
子集的69所房子,其中基于密度的空间聚类被用来评估所选择的子集的
行为一致性,并确定行为的偏心。他们报告说,用于预测大型聚合的传
统时间序列特征可能无法在单米级负载模式上执行,而拟议的LSTM在
预测性能方面有所改进[25]。Cini等人在STLF的情况下使用深度递归神
经网络引入了基于集群的电力需求预测聚合。他们证明了基于频谱的聚
类相对于随机聚类的明显改进,并且多预测器架构实现了最高的准确
性,其中需要进一步研究更有效的配置[26]。 Mocanu等人提出了两种
DL变体之间的比较:条件限制玻尔兹曼机(CRBM)和用于住宅消费者
的STLF的因子条件限制玻尔兹曼机(FCRBM),其中FCRBM表现出优
于ANN,SVM,RNN和CRBM的主导性能[27]。表1列出了与住宅微观病
例相关的STLF
明显 改进 在 预测 精度 有 被
通过所讨论的关于采用深度学习架构的微观STLF的研究来证明。然而,
很少有研究调查的影响,tight的电力需求聚合对住宅STLF。参考文献
[32]对聚集层进行了粗略的分析,住宅需求远高于一般的建筑层公寓,
导致误差较小。此外,由于数据集的原因,检测的聚集水平具有较低的
样品计数,并且由于聚集,较高的样品计数可以提供更稳健的误差范
围。相比之下,参考文献[31]利用聚类算法,并建议对150个房屋进行
聚类,以确保误差低于10%的MAPE准确度。然而,考虑到STLF在智能
电网
以及服务单个或多个家庭的微电网,不可能将具有类似行为模式的客户
分组。因此,结果无法描述最差情况,未考虑低于50的聚合物。此外,
在许多研究中,用于比较的DL模型依赖于先前研究的架构,其中模型结
构的性能在不同的数据集之间可能会有所不同。因此,需要进行局部彻
底的敏感性分析,以便在最先进的DL模型之间进行更稳健和新鲜的比
较。为了填补这一空白,本研究作出了以下贡献
1
将479个房屋的大数据集随机聚合成5个级别的电力需求聚合,覆盖
小和大聚合大小(3,10,30,100和479),每个级别的样本大小
分别为(159,47,15,4和1)。因此,聚合需求的最佳聚合大小
进行了全面的分析,以实现高的STLF性能,并提供了一个全面的基
准,在不同级别的聚合的STLF性能。据我们所知,尚未进行大量样
品的这种综合聚集分析,特别是对较低聚集体的分析
2
利用自相关分析和谱密度分析,对低聚集度下STLF的特征和相关因
素进行了深入的研究。这些分析的结果,再加上仔细的功能选择的
基础上,最近的文献,并用于实现最佳的STLF基准不同的聚合水
平。
3
介绍了一种全面的方法论方法,用于优化五种最先进的DL STLF方
法(DNN,CNN,LSTM,GRU和双向LSTM/GRU)。每个类的四
个架构进行了研究,详细的网格搜索超参数调整,加上不同的敏
感性分析,
剩余19页未读,继续阅读

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新型矿用本安直流稳压电源设计:双重保护电路
- 煤矿掘进工作面安全因素研究:结构方程模型
- 利用同位素位移探测原子内部新型力
- 钻锚机钻臂动力学仿真分析与优化
- 钻孔成像技术在巷道松动圈检测与支护设计中的应用
- 极化与非极化ep碰撞中J/ψ的Sivers与cos2φ效应:理论分析与COMPASS验证
- 新疆矿区1200m深孔钻探关键技术与实践
- 建筑行业事故预防:综合动态事故致因理论的应用
- 北斗卫星监测系统在电网塔形实时监控中的应用
- 煤层气羽状水平井数值模拟:交替隐式算法的应用
- 开放字符串T对偶与双空间坐标变换
- 煤矿瓦斯抽采半径测定新方法——瓦斯储量法
- 大倾角大采高工作面设备稳定与安全控制关键技术
- 超标违规背景下的热波动影响分析
- 中国煤矿选煤设计进展与挑战:历史、现状与未来发展
- 反演技术与RBF神经网络在移动机器人控制中的应用
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


