GPU与CUDA技术解析:从简介到Tesla系统架构
"GPU与CUDA简介,由上海超级计算中心研发部徐磊主讲,涵盖了GPU的基本概念,Tesla GPU的系统架构,CUDA架构和编程模型,以及CUDA在多个行业的应用实例和实践情况。"
正文:
一、GPU简介
GPU,全称为Graphic Processing Unit,是一种专门用于处理图形和图像显示的处理器。GPU的制造商主要包括NVIDIA和AMD(ATI)。与传统的CPU相比,GPU在设计上更注重计算密集型任务和大量数据并行化处理,拥有更多的计算单元,而较少的缓存和控制电路。这种设计使得GPU在浮点运算和存储器带宽方面表现出显著优势,特别适合于高性能计算和图形渲染等应用场景。
二、GPU(Tesla)系统架构
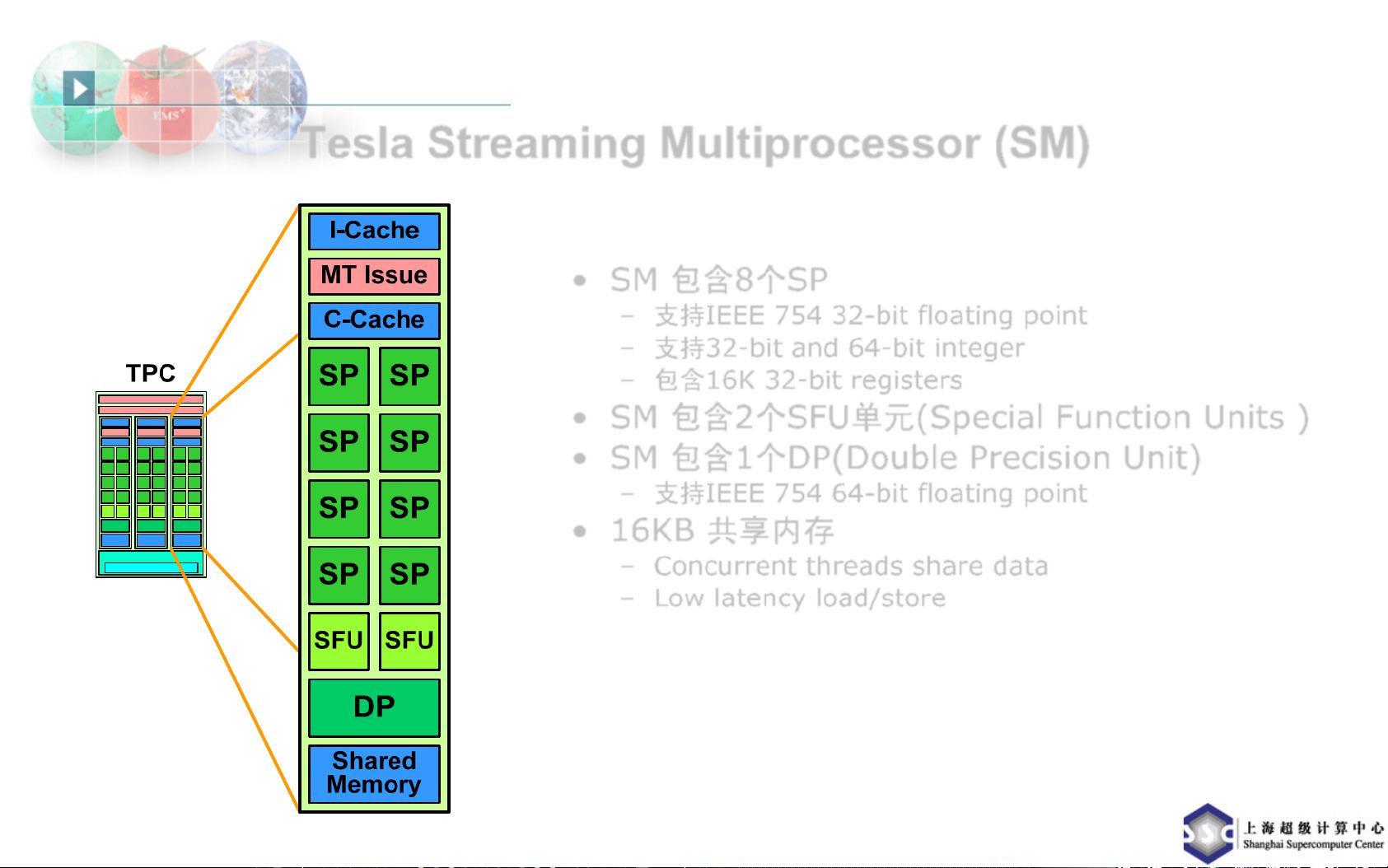
NVIDIA的Tesla系列GPU是为高性能计算而设计的,如Tesla T10处理器。它具有240个核心,运行频率为1.296GHz,配备4.0GB的板载内存,峰值内存带宽可达102GB/s。该GPU采用512-bit, 800MHz GDDR3内存,单精度和双精度浮点运算性能分别为933GFlops和78GFlops,并通过PCIe x16 Gen2接口与系统连接,功耗约为160W。Tesla系统的内部结构由10个Thread Processor Clusters (TPC),每个TPC包含3个Stream Multiprocessors (SM),每个SM又由8个Stream Processors (SP)组成。SP支持32位和64位浮点及整数运算,并配有特殊功能单元(SFU)和双精度单元(DP)。
三、CUDA Architecture
CUDA是NVIDIA推出的一种并行计算平台和编程模型,它允许程序员利用GPU的并行计算能力来解决复杂问题。CUDA架构包括设备端的GPU和主机端的CPU,通过CUDA C/C++编程语言,开发者可以编写直接对GPU进行操作的程序。CUDA的核心组件包括Kernel(可并行执行的函数),Block(一组线程的集合),Grid(多组Block的集合),以及共享内存和全局内存等。
四、CUDA Programming Model
在CUDA编程模型中,程序员定义了在GPU上执行的kernel函数,这些函数可以在成千上万的线程中并行执行。线程被组织成线程块和线程网格,以便有效地利用GPU的并行处理能力。CUDA还提供了丰富的内存层次,如寄存器、共享内存、纹理内存和全局内存,以优化数据访问速度。
五、CUDA应用与实践
CUDA已广泛应用于各个领域,如生命科学中的分子动力学模拟,机械工程的仿真分析,石油行业的地震数据分析,金融领域的风险计算,数学中的数值方法,天文学的宇宙模拟,以及通信行业的信号处理等。CUDA的成功案例展示了其在加速计算和提高效率方面的强大潜力。
总结:
GPU与CUDA的结合为高性能计算提供了新的解决方案,通过充分利用GPU的并行处理能力,可以大幅提高计算密集型任务的执行效率。随着技术的不断进步,CUDA编程模型和GPU硬件的优化,未来将在更多领域中发挥关键作用。
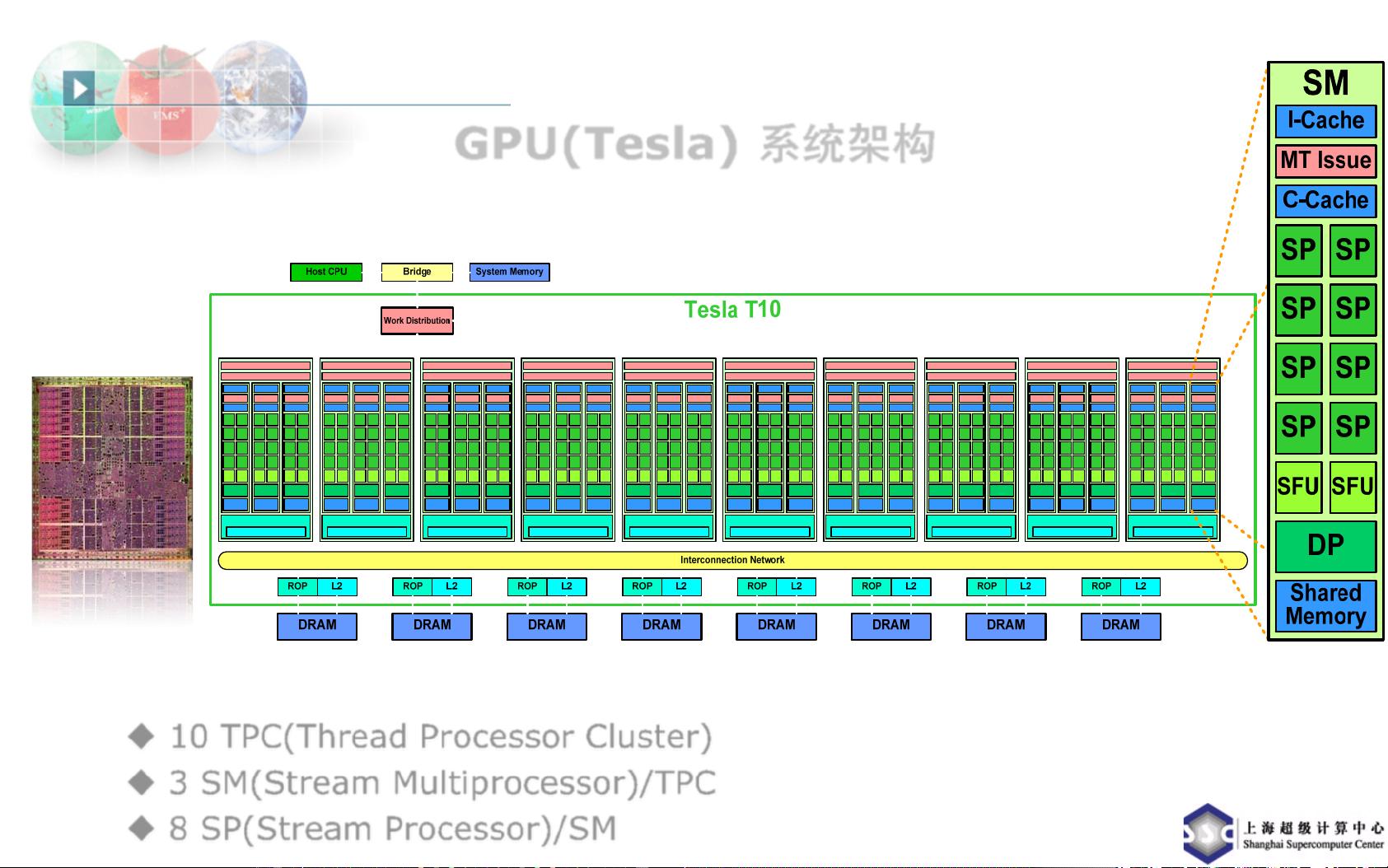
GPU(Tesla) 系统架构
系统组成:
10 TPC(Thread Processor Cluster)
3 SM(Stream Multiprocessor)/TPC
8 SP(Stream Processor)/SM

剩余58页未读,继续阅读
2024-06-10 上传
2022-09-19 上传
2022-09-24 上传
2022-09-20 上传
2014-07-25 上传
2022-09-23 上传
点击了解资源详情
点击了解资源详情

golddreamok
- 粉丝: 0
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- PureMVC AS3在Flash中的实践与演示:HelloFlash案例分析
- 掌握Makefile多目标编译与清理操作
- STM32-407芯片定时器控制与系统时钟管理
- 用Appwrite和React开发待办事项应用教程
- 利用深度强化学习开发股票交易代理策略
- 7小时快速入门HTML/CSS及JavaScript基础教程
- CentOS 7上通过Yum安装Percona Server 8.0.21教程
- C语言编程:锻炼计划设计与实现
- Python框架基准线创建与性能测试工具
- 6小时掌握JavaScript基础:深入解析与实例教程
- 专业技能工厂,培养数据科学家的摇篮
- 如何使用pg-dump创建PostgreSQL数据库备份
- 基于信任的移动人群感知招聘机制研究
- 掌握Hadoop:Linux下分布式数据平台的应用教程
- Vue购物中心开发与部署全流程指南
- 在Ubuntu环境下使用NDK-14编译libpng-1.6.40-android静态及动态库
