基于局部加权主成分分析的ICU患者健康状态监测
17 浏览量
更新于2024-08-27
收藏 1.4MB PDF 举报
"这篇研究论文探讨了基于局部加权主成分分析(Locally Weighted Principal Component Analysis, LWPCA)的重症监护室(ICU)患者健康状况监测方法。该方法旨在帮助医疗人员快速识别和评估疾病变化,以便制定合适的治疗策略。文章指出,目前广泛应用的通用型监测模型在应对ICU患者复杂多变的病情时存在困难,因为这些模型往往无法适应个体差异和病情的实时变化。"
正文:
在医疗领域,特别是重症监护室(ICU),对患者健康状况的实时、准确监测至关重要。传统的监测方法可能无法有效地捕捉到患者病情的细微变化,特别是在面对ICU患者这种病情复杂且快速变化的情况时。论文“Health status monitoring for ICU patients based on locally weighted principal component analysis”提出了一个创新的解决方案,即利用局部加权主成分分析(LWPCA)进行智能状态监测。
主成分分析(PCA)是一种常用的数据降维技术,能够将高维数据转换成一组不相关的低维特征,以揭示数据的主要结构。然而,PCA通常假设数据是静态的,对于ICU患者这种动态变化的数据流并不适用。因此,研究人员引入了LWPCA,这是一种在线学习的、自适应的监测方法。LWPCA通过赋予最近邻数据点更大的权重,使得模型能够更好地适应个体患者的实时状态,以及病情随时间的变化。
论文指出,LWPCA的核心优势在于其灵活性和适应性。与传统的PCA相比,LWPCA可以动态更新模型,不断调整权重以反映最新的观测值,从而更准确地反映出患者当前的健康状况。这种方法特别适合处理ICU环境中的非线性和异步数据,如生理信号、实验室检查结果等。
此外,论文还提到了局部加权投影回归(LWPR),这是一种与LWPCA相关的机器学习技术,用于建立预测模型。LWPR可以处理非线性关系,对异常值具有鲁棒性,有助于预测病情发展趋势,从而辅助医疗决策。
文章详细描述了LWPCA和LWPR的算法实现和性能评估,并与其他监测方法进行了比较。研究表明,LWPCA和LWPR结合的应用在识别病情变化和预警方面表现出色,可以显著提高ICU患者监测的效率和准确性。
总结来说,这篇研究论文为ICU患者健康监测提供了一种新的、适应性强的方法,利用LWPCA和LWPR技术,可以更好地应对ICU环境中复杂多变的病情,及时发现并响应患者状况的任何变化,从而提高医疗服务的质量和效率。未来的研究可能会进一步探索这两种技术与其他医疗数据处理方法的集成,以优化ICU的临床决策支持系统。
Y. Ding et al. / Computer Methods and Programs in Biomedicine 156 (2018) 61–71 63
To measure the locality and the contribution of each data to x
c
,
a Gaussian kernel function is used to compute the weight w ( x, x
c
)
for each data point x ,
w (x, x
c
) ˆ = exp (−0 . 5 (x − x
c
)
T
D ( x − x
c
)) (1)
where D is a positive semi-definite distance metric, which deter-
mines the size and shape of the neighborhood contributing to the
local model.
Without loss of generality, the weights are required to normal-
ize data, which can be realized by subtracting the weighted mean
x or y from the data, where
¯
x
=
N
i =1
w ( x
i
, x
c
) x
i
N
i =1
w ( x
i
, x
c
)
¯
y
=
N
i =1
w ( x
i
, x
c
) y
i
N
i =1
w ( x
i
, x
c
) (2)
where x
i
indicates the i th sample in the dataset, and N is the num-
ber of data points.
During the whole procedure of nonlinear function approxima-
tion, the learning procedure involves automatically determining
the appropriate number of local models K ; parameters β of the hy-
per plane in each model; also the region of validity (called recep-
tive field, RF), parameterized as a distance metric D in a Gaussian
kernel.
Predictions
ˆ
y
k
(x ) (k = 1 , 2 , ··· , K) of each local linear model are
calculated for the given query point x
q
, and the final prediction
˜
y
q
of the learning system is the normalized weighted mean of all K
linear models [36] :
˜
y
q
=
K
k =1
w ( x
q
, x
k
c
)
y
k
K
k =1
w ( x
q
, x
k
c
) (3)
where
˜
y
q
denotes the global prediction of x
q
, x
k
c
indicates the cen-
ter point of the k th local model, and w ( x
q
, x
k
c
) is the weight be-
tween x
q
and x
k
c
.
In LWPR, updating the regression parameters is mainly realized
by using partial weighted partial least square algorithm (LWPLS),
of which the main idea is similar to the standard PLS except the
weight. The optimal projection direction is obtained by maximiz-
ing the covariance between input data and the regression residuals
in each step to find the optimal projection direction. For the k th
local model, the procedure of LWPLS is as follows [36] , and here
w
i
, ( i = 1, 2, , N ) indicates w ( x
i
, x
k
c
) for convenience, so does it in
the following sections.
The distance metric D and hence the locality of the receptive
fields can be learned for each local model individually by stochastic
gradient descent in a penalized leave-one-out cross validation cost
function [36] . D
def
is an original distance matrix, the initial number
of projection is set as R = 2.
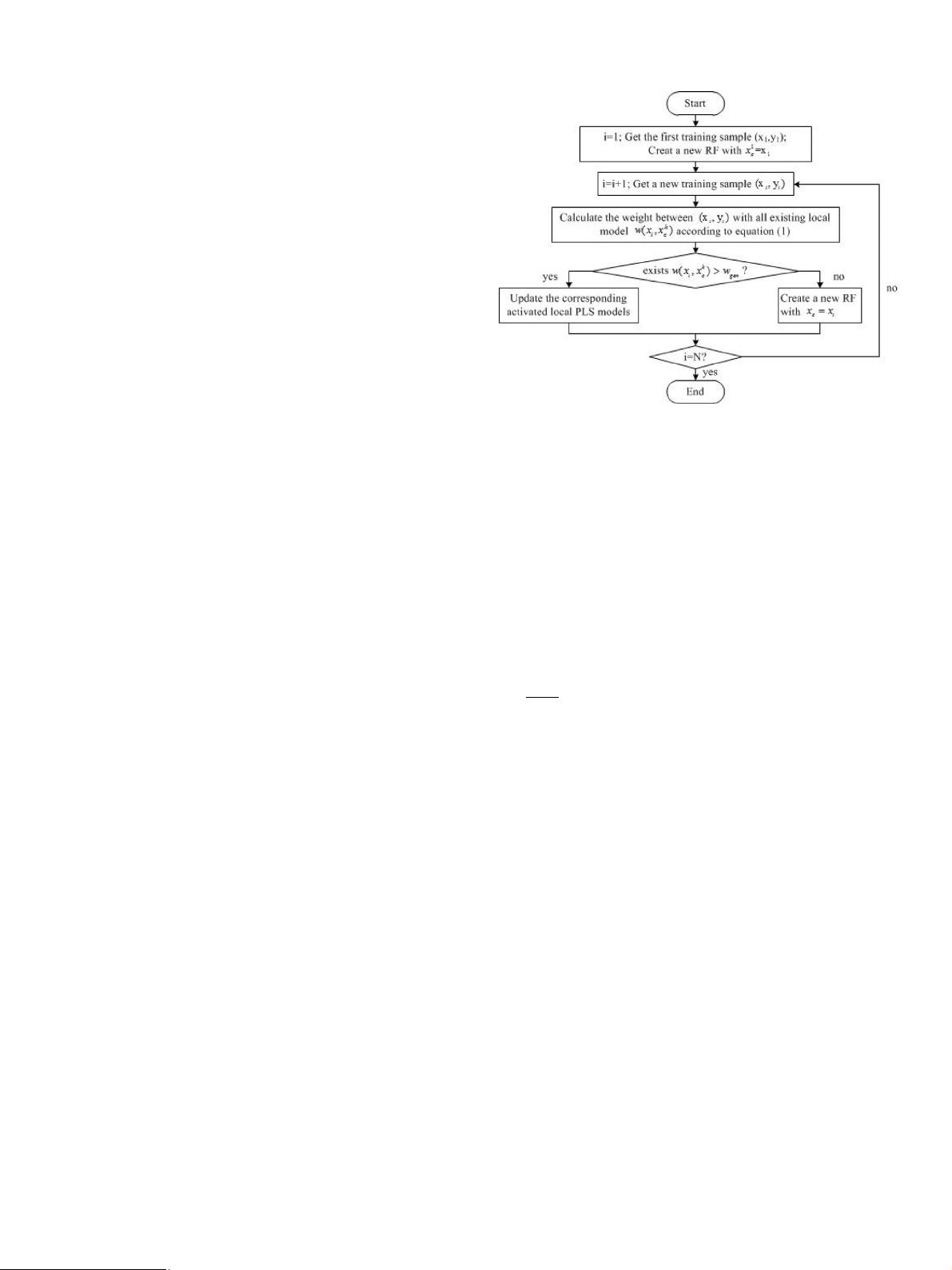
When the first training data ( x
1
, y
1
) is joined, R = 2,
x
c
= x
1
, D = D
def
, ( D
def
is an original distance matrix) and a new
receptive field (RF, the region of validity) is created. Then with
the following training data, both the structure and the number
of local models are updated integrated with Gaussian kernel
weights, meanwhile the parameters R and D also changes. In
addition, a new RF will be created if all the weights are less than
a certain threshold w
gen
. For the sake of more clear illustration of
LWPR algorithm, Fig. 1 provides the simplified procedure of the
learning procedure, and a global model containing a series of local
models will be acquired in final. For a given query sample, the
corresponding global prediction output can be calculated by using
formula (3) .
Fig. 1. Simplified procedure of LWPR algorithm.
2.2. Principal component analysis
In the field of physiological processes, PCA is commonly used
for feature extraction and data compression instead of status mon-
itoring [37,38] . Its core idea is to transform multiple interrelated
variables into a few key independent components, which will de-
scribe the overall information, thus reducing the number of vari-
ables to be monitored. The procedure of simple PCA is as follows.
Assuming X
0
= ( x
ij
)
n × m
represents the original data matrix of
the normal process, where n denotes the measurement number, m
indicates the physical variables number, and n > m [39] . However,
the data matrix must be normalized to zero mean and unity vari-
ance, namely X , and the covariance matrix C is defined by
C =
1
n − 1
X
T
X
For the sake of extracting the main information, singular value
decomposition (SVD) is applied to the covariance matrix.
C = SS
T
=
S
pc
S
res
pc
0
0
res
S
pc
S
res
(4)
where S ∈ R
m × m
refers to the unit feature vectors of the covariance
matrix C , and S
pc
∈ R
m × r
corresponds to the eigenvalues sorted in
decreasing order ( λ
1
> λ
2
> λ
r
), while S
res
∈ R
m × ( m − r )
refers
to the remaining smaller eigenvalues ordered by λ
r + 1
> λ
r + 2
>
λ
m
, r denotes the number of exacted components, which can be
decided by several proposed approaches in the literature, such as
the SCREE procedure [22] , Cumulative Percent Variance (CPV) [40] .
Finally, X will be decomposed into the following two parts,
X =
ˆ
X +
˜
X = S
pc
S
T
pc
X + S
res
S
T
res
X (5)
where
ˆ
X abstracts the most information of the original variables,
while
˜
X , namely residual matrix, denotes the noise or uncertain
disturbance mostly when the measurements are fault free. Further-
more, the columns of S
pc
and S
res
tension into two orthogonal sub-
spaces, which refer to the principal component subspace and the
residual subspace, respectively.
Generally speaking, PCA uses two complementary statistics as
detection indices to measure the variation of the sample vectors’
projections in the principal component subspace and the residual
subspace, respectively, that is Hoteling’s T
2
[41] and squared pre-
diction error (SPE, also known as Q statistics) [42] , defined as
T
2
= X
T
S
pc
−1
pc
S
T
pc
X
SP E = X
T
S
res
S
T
res
X
(6)
剩余10页未读,继续阅读
2009-05-24 上传
2021-10-04 上传
2021-02-21 上传
2021-05-11 上传
2021-02-09 上传
2021-02-11 上传
2021-02-22 上传
2021-02-21 上传
2021-02-07 上传

weixin_38628243
- 粉丝: 1
- 资源: 907
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索数据转换实验平台在设备装置中的应用
- 使用git-log-to-tikz.py将Git日志转换为TIKZ图形
- 小栗子源码2.9.3版本发布
- 使用Tinder-Hack-Client实现Tinder API交互
- Android Studio新模板:个性化Material Design导航抽屉
- React API分页模块:数据获取与页面管理
- C语言实现顺序表的动态分配方法
- 光催化分解水产氢固溶体催化剂制备技术揭秘
- VS2013环境下tinyxml库的32位与64位编译指南
- 网易云歌词情感分析系统实现与架构
- React应用展示GitHub用户详细信息及项目分析
- LayUI2.1.6帮助文档API功能详解
- 全栈开发实现的chatgpt应用可打包小程序/H5/App
- C++实现顺序表的动态内存分配技术
- Java制作水果格斗游戏:策略与随机性的结合
- 基于若依框架的后台管理系统开发实例解析
