"PySpark Day03:RDD操作详解-构建、转换与执行"
需积分: 0 74 浏览量
更新于2024-01-17
收藏 5.88MB PDF 举报
《PySpark_Day03:RDD(弹性分布式数据集).pdf》是关于Spark中的RDD(弹性分布式数据集)的文档。Spark是建立在分布式数据集的概念上的,这些数据集包含任意的Java或Python对象。你可以从外部数据创建数据集,并对其应用并行操作。Spark API的构建块是其RDD API。在RDD API中,有两种类型的操作:转换操作,它们基于先前的数据集定义一个新的数据集;和行动操作,它们启动一个作业在集群上执行。
Spark是用Scala编写的,运行在JVM上。Spark具有内置的优化引擎,可以自动处理大规模数据处理任务。Spark支持多种数据源,可以从Hadoop分布式文件系统(HDFS)、本地文件系统、Hive、HBase等读取数据。它还提供了丰富的库和工具,用于数据处理、机器学习、图计算等领域。
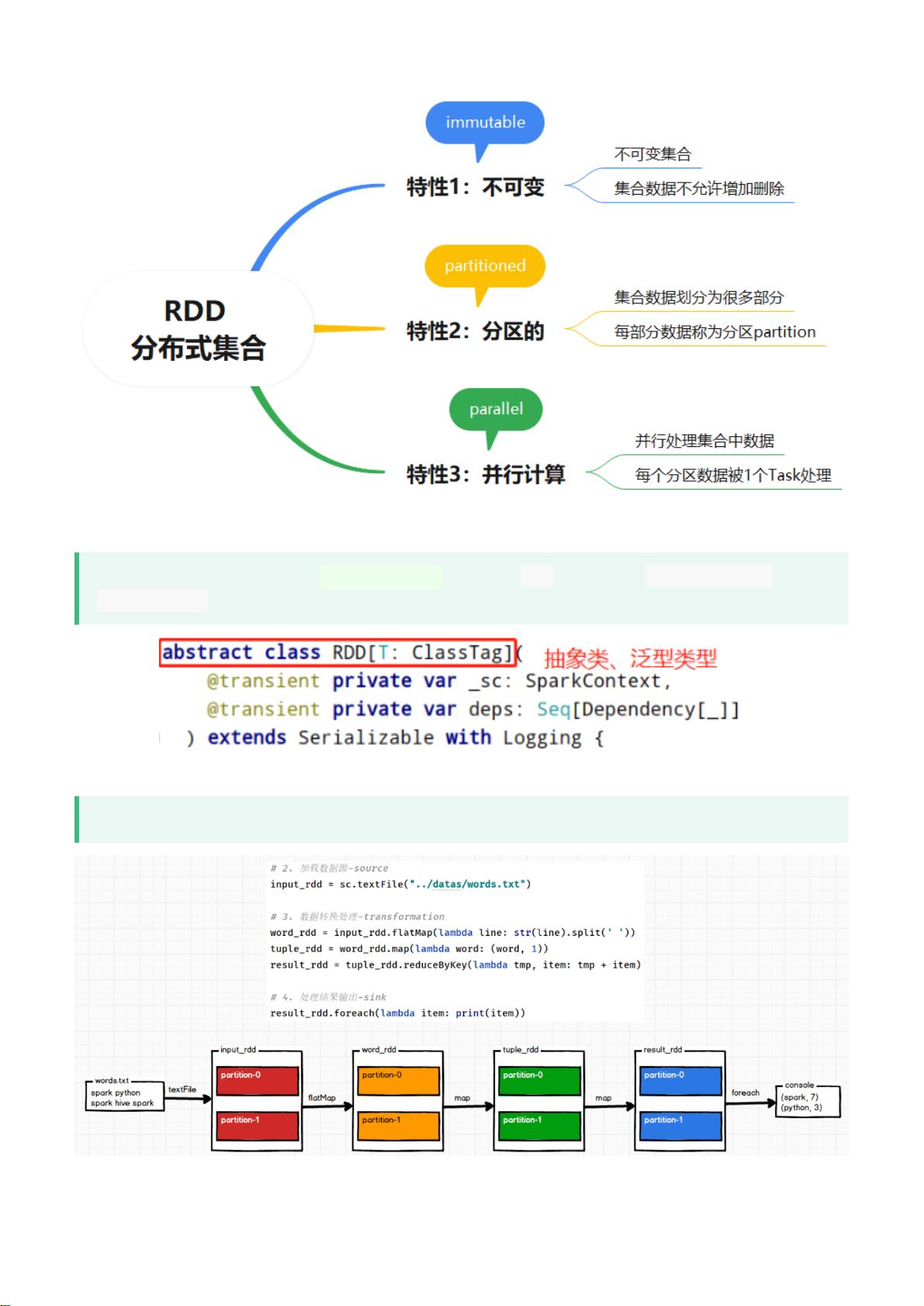
RDD是Spark中最基本的数据结构之一,代表了一个分布式的、不可变的、弹性的数据集。RDD可以存储不同类型的数据,包括数字、字符串、对象等。RDD具有容错性,即使在节点失败时也可以恢复数据,并且可以通过并行操作在集群上并行处理数据。RDD支持多种转换和行动操作,如map、filter、reduce等,可以对数据集执行各种复杂的计算。
在使用RDD时,首先需要创建一个RDD对象,可以通过从外部数据源读取数据或对已有数据集进行转换操作来创建。然后可以使用各种转换操作定义新的RDD,并连续应用多个转换操作来构建出复杂的数据处理流程。最后,可以将行动操作应用于RDD,触发实际的计算并返回计算结果。
使用RDD进行数据处理时,需要注意一些性能优化的技巧。例如,避免频繁的数据拷贝和网络通信,合理选择并行度和分区数,使用广播变量传播共享数据等。此外,可以通过持久化RDD来提高计算效率,以避免重复计算。
总之,RDD是Spark中弹性分布式数据集的核心概念,通过RDD可以方便地进行并行数据处理和分布式计算。它提供了丰富的转换和行动操作,以及优化引擎和各种工具库,使得Spark成为大数据处理和分析的强大工具。

Spark实现词频统计,首先将要处理数据封装到RDD,处理数据时,直接调用函数,最后将结果RDD输出。
思考:Spark中RDD到底是什么呢? RDD就是一个集合,封装数据,往往数据是大规模海量数据

剩余45页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-03-24 上传
2023-03-24 上传
2023-03-24 上传
2023-03-24 上传
2023-03-24 上传
2023-03-24 上传

weixin_45955420
- 粉丝: 0
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







