TensorRT优化Openpose模型实战:加速与分析
需积分: 0 110 浏览量
更新于2024-08-04
收藏 1.59MB DOCX 举报
"TensorRT试用总结1"
在本文中,我们将深入探讨TensorRT技术及其在加速神经网络推理(inference)过程中的应用。TensorRT是一个由NVIDIA开发的高性能库,专为深度学习模型的优化、验证和部署而设计。它主要用于提升GPU的计算效率,尤其是在推理阶段,支持包括Jetson TX1在内的Pascal架构设备,如Tesla P100、K80、M4和Titan X等,并且能够利用fp16(半精度浮点运算)来提高计算速度。
TensorRT的核心功能之一是将训练好的神经网络模型,如Caffe模型,通过NvCaffeParser解析成支持半精度的新模型。这个过程能够保留原始模型的精度,同时利用半精度运算减少计算量和内存占用,从而提高推理速度。值得注意的是,TensorRT并不支持模型的训练,它仅用于模型的执行阶段。
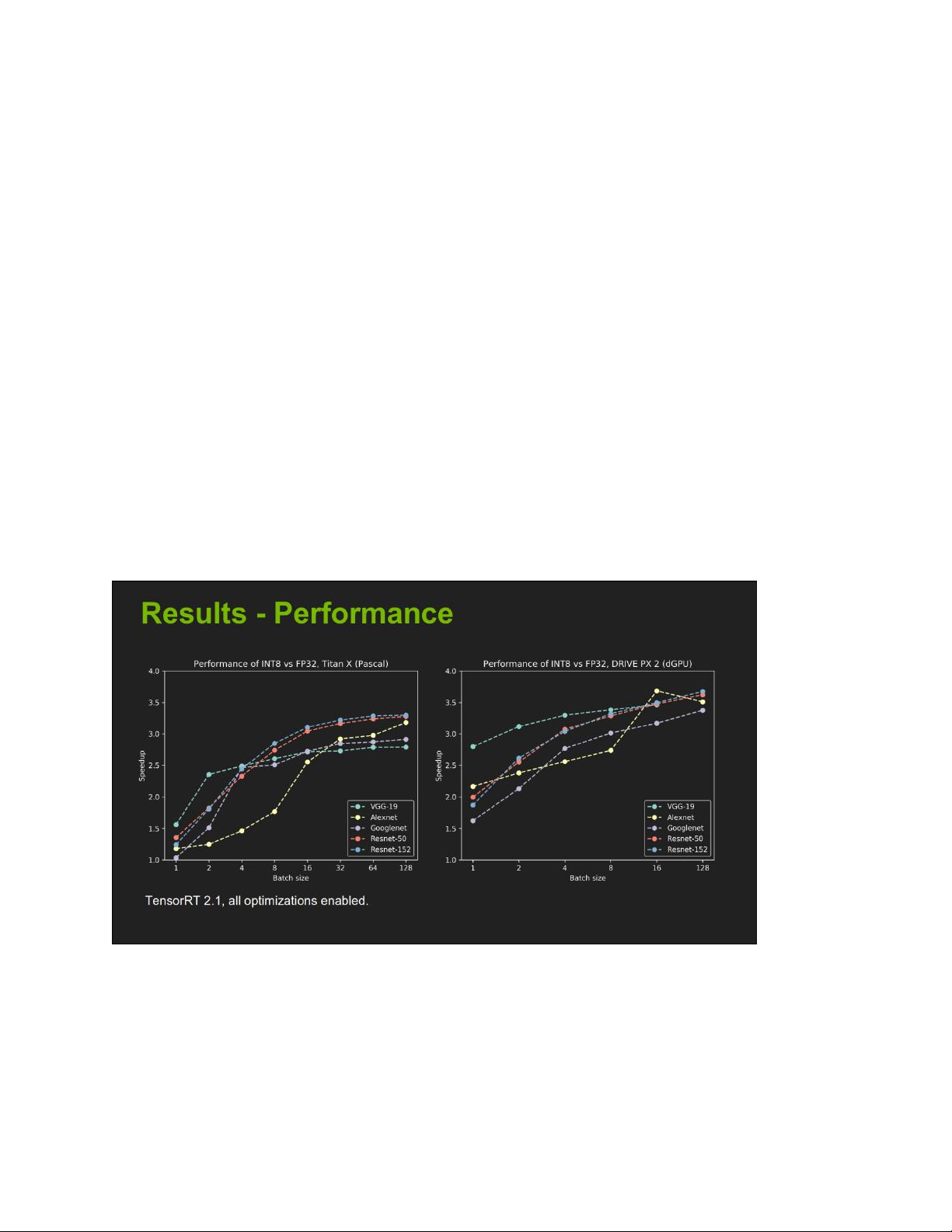
官方数据显示,使用TensorRT对常见的神经网络模型如MNIST、GoogLeNet、AlexNet等进行了加速测试。例如,GoogLeNet在单精度模式下的加速比达到1.6,这意味着使用TensorRT后,推理速度提升了60%。然而,这种加速效果会随着模型的复杂性和批处理大小(batch size)的变化而变化。通常,更大的批处理能带来更显著的加速效果,但也会受到硬件内存限制。
在实际试用过程中,可能会遇到一些问题,导致加速比低于预期或者某些模型无法顺利运行。例如,简单的模型可能由于其层数较少,无法充分利用单精度运算的优势。另一方面,批处理大小的选择也至关重要,它不仅影响模型的收敛速度,还与内存利用率密切相关。错误的参数设置,如不恰当的输出类型配置,或者模型包含TensorRT不支持的层,都可能导致模型转换失败或运行出错。
面对这些问题,未来的探索方向可以包括将更多类型的模型,如CNN和RNN,转换为TensorRT兼容的形式,以便在更广泛的硬件平台上实现高效推理。这可能涉及到调整模型结构、优化参数设置,以及研究如何解决不兼容层的问题。TensorRT为深度学习模型的实时应用提供了强大的工具,但在实际应用中,需要结合具体模型和硬件条件进行细致的调优。
1. 任务描述:使用 TensorRT(GIE)的单精度模型转换加速 Openpose 模型的 inference 过程达到可
用级别。
2. TensorRT 介绍:
i)对已训练的神经网络进行优化、验证和部署;
ii)C++库,官方 API: TX1:/usr/share/doc/gie/doc/API/index.html;
iii)适用于 Jetson TX1 和 Pascal 架构的显卡(Tesla P100, K80, M4 and Titan X 等),支持 fp16 特性---
半精度运算;
iv)对 inference 过程加速,只能用来做 Inference,不能用来做 train;
v)解析 caffe 模型-->NvCaffeParser,根据 prototxt 文件和 caffemodel 权值,转化为支持半精度的新的
模型;
vi)支持 caffe 中大部分的层;
3.官方加速效果:
下载后可阅读完整内容,剩余4页未读,立即下载
781 浏览量
198 浏览量
点击了解资源详情
272 浏览量
2273 浏览量
150 浏览量
109 浏览量
110 浏览量
109 浏览量

daidaiyijiu
- 粉丝: 20
- 资源: 322
 我的内容管理
展开
我的内容管理
展开







最新资源
- 基于YOLO神经网络的实时车辆检测代码
- TravelAdvisor
- uiGradients-Viewer-iOS::artist_palette:一个开放源代码应用程序,用于查看https上发布的渐变
- 15套动态和静态科技风光类PPT模板-共30套
- Tonite
- 正点原子精英Modbus_Master_Template.zip
- 聚合物制造:移至Polymertools monorepo
- AboutMe
- Trello克隆
- IT资讯网_新闻文章发布系统.rar
- Simple Math Trainer Game
- igloggerForSmali
- Tomate
- 4,STM32启动文件.rar
- pghoard:PostgreSQL备份和还原服务
- hw9
