GPU缓存模型:基于重用距离理论的详细分析
需积分: 11 150 浏览量
更新于2024-07-22
收藏 40.78MB PDF 举报
"HPCA 2014 Proceeding——计算机科学与计算机体系结构的重要会议,包含30多篇关于GPU缓存模型和性能优化的文章。"
在计算机科学领域,特别是计算机体系结构,HPCA(High-Performance Computer Architecture)是与ISCA和MICRO齐名的顶级会议,它聚焦于最新的技术进展和研究成果。2014年的HPCA会议收录了一系列文章,虽然上传的只是部分,但包含了30多篇针对GPU缓存模型的深入研究。
GPU(Graphics Processing Unit)在现代计算中扮演着关键角色,尤其是在高性能计算和深度学习等领域。随着GPU对片上内存的依赖增加,如何有效地利用其缓存以提高性能和降低能耗变得至关重要。论文“ADetailedGPUCacheModelBasedonReuseDistanceTheory”关注的正是这一问题。
传统的CPU中,栈距离或重用距离理论被广泛用于预测和理解缓存行为。然而,GPU因其独特的并行执行模型、细粒度多线程、条件分支、非均匀延迟、缓存关联性、Miss Status Holding Registers (MSHRs)以及线程分叉(warp divergence)等特点,使得直接应用该理论变得复杂。
该论文扩展了重用距离理论,以适应GPU的特性:
1. **线程层次结构**:模型考虑了GPU中的线程、线程束(warp)、线程块以及活动线程集,这些是GPU并行执行的基础单元。
2. **条件和非均匀延迟**:GPU的指令执行可能因条件分支而产生不同延迟,模型需能捕捉这种差异。
3. **缓存关联性**:GPU缓存的关联性会影响数据访问模式,模型需要模拟这种情况下的行为。
4. **Miss Status Holding Registers (MSHRs)**:MSHRs在处理缓存未命中时起作用,它们管理并发请求,模型需考虑其影响。
5. **线程分叉(warp divergence)**:当线程束中的线程执行不同的路径时,这会影响缓存行为,模型需要能够表示这种情况。
论文作者实现了一个基于C++的模型,并扩展了Ocelot GPU模拟器,以验证和演示这个扩展的重用距离理论在GPU环境中的适用性。这样的工作对于理解和优化GPU的性能,尤其是在面临内存墙挑战时,具有重大意义。通过深入理解GPU缓存的行为,开发者和研究人员可以设计出更高效、更节能的GPU应用和架构。

Initial Permissions New Permissions
S/PT Hyp. OS User S/PT Hyp. OS User
Rule ID Requester S P R W X R W X R W X S P R W X R W X R W X Action Note
1 Hypervisor - - - - - - - - - - -
* * * * * * * * * * *
None * = don’t care
2 Hypervisor
* * * * * * * * * * *
- - - - - - - - - - - Wipe Page * = don’t care
3 OS - - - - - - - - - - -
* *
- - -
* * * * * *
None * = don’t care
4 OS
* *
- - -
* * * * * *
- - - - - - - - - - - Wipe Page * = don’t care
5 Hypervisor - - - W - - - - - - - - - - - X - - - - - - None Hypervisor code page
6 OS - - - - - - W - - - - - - - - - - - X - - - None OS code page
7 OS - - - - - - - - - W - - - - - - - - - - - X None User-level code page
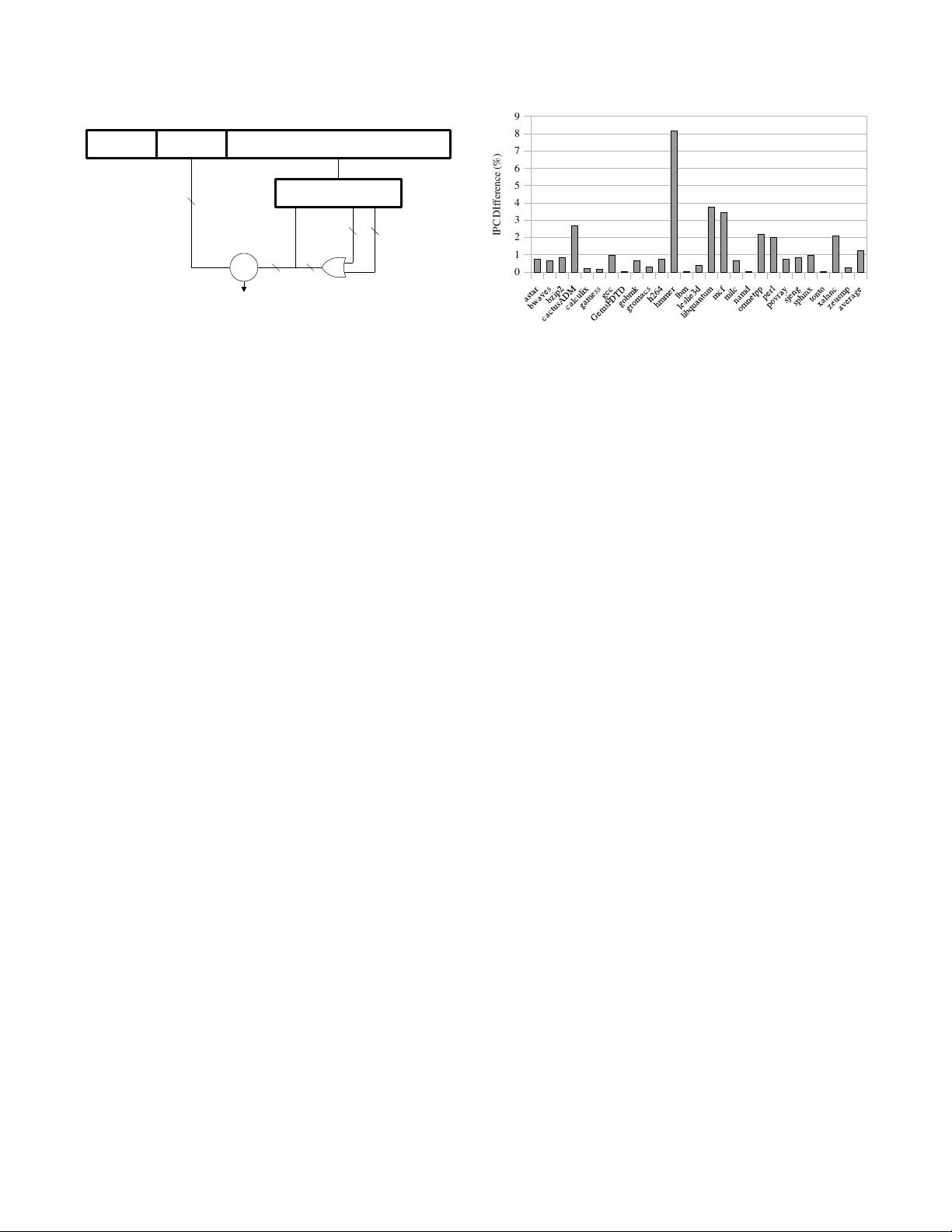
Table 2: Permission Assignment Rules to Mitigate Cross-Layer Attacks Considered in our Threat Model
3.3. PRM and Verification of Permissions
The Permission Reference Monitor (PRM) has two responsi-
bilities. First, it ensures that a given memory access is allowed
by the permissions specified for a given physical page. This
is only a minor extension of the type of permission check
performed by existing hardware.
The second responsibility of the PRM is to ensure that the
permission specified for a given physical page is allowed by
the requested memory access. To better understand this, con-
sider a potential attack against the NIMP permission system
that may allow a compromised OS to violate the confiden-
tiality of a user-level page. Assume a page has permissions
- - - | - - - | R W -
. An application may plan to
use this to store confidential information. During the ap-
plication’s run-time, suppose that the OS returns the page
to the null-state using rule 4 (wiping the page in the pro-
cess) and then uses rule 3 to set the page’s permissions to
- - - | R - - | R W -
, hence allowing itself read ac-
cess. Although existing confidential data on the page was
wiped, any future data written by the application could now
be read by the OS.
One solution to this problem would be to simply not permit
the OS to alter the permissions of the page, and instead make
that the sole responsibility of the application. The problem,
however, is that then the OS cannot reclaim memory from a
killed or misbehaving application, which is an unacceptable
outcome. A better solution is for the application to be able
to verify the permissions of the page prior to accessing it.
Then, if the permissions have changed, the write should not
occur. This check needs to be atomic with the write in order
to prevent time-of-check race conditions.
In order to accomplish this, the instruction set is modified
to allow memory access instructions to specify what permis-
sions they explicitly do not want other privilege levels to have.
This information can be encoded within memory instructions.
When a memory instruction is executed, then the PRM per-
forms verification and either allows or denies the request.
4. NIMP Implementation Details
In this section we describe our implementation of NIMP.
4.1. Permission Store
Permissions for each physical page are stored in a special area
of memory called the permission store. The permission store
is made of individual page permissions stored in a Permission
Structure (PS). The PS entry for each physical page speci-
fies the currently active permissions for this page, such that
separate "read", "write" and "execute" bits are provided for
each of the privilege layers (hypervisor, OS and user-level). In
addition, the shared (S) and page table (PT) bits are also in-
cluded. We assume that 2 bytes are needed in memory to store
each of the PS entries, with five bits reserved for future use.
We include the five reserved bits to make each PS entry byte
aligned. Figure 3a shows the PS layout for a single physical
page.
The PS entries for each physical page are securely stored
in a protected region of memory accessible only by hardware
that is in charge of enforcing these new permissions. Neither
the OS nor the hypervisor have a direct access to this memory
and every request to set up or change the permissions has to
go through the NIMP hardware.
Physical memory demand for storing the PS bits is very
modest. For example, for a system with 16GB of physical
memory and 4KB pages, the PS entries for all pages require
only 8MB of memory (2 bytes for each of the 4M pages in the
system), which represents 0.05% of the total memory space.
Additionally, the PS bits are also cached in the instruction and
data TLB entries, just like regular permission bits are cached
in traditional systems. Therefore, the access to PS data in
memory is only needed following a TLB miss. The PS data is
also stored in the regular caches, similar to other system-level
data, such as the page tables.
It is important to observe that the permission bits are not
modified directly by any software layer. All changes must be
approved by the MPM. In order to facilitate this, we add a
new instruction (called PERM_SET) to the ISA to perform the
validity check against the Rule Database and setup the page
permission. This new instruction is described in detail below.
4.2. Memory Permission Manager
In this section, we describe the MPM implementation.
4.2.1. Rule Database and Secure System Boot
To modify
permissions in NIMP, we rely on the use of securely stored
permission modification rules — only the transitions specified
by the rules are allowed, and this is directly controlled by
the MPM hardware. All transitions not specified in the Rule
Database are disallowed. These modification rules are stored
in a dedicated Rule Database (RD), which is located inside a
processor die in a small TCAM structure. Once loaded at boot
time, the contents of the RD never change. Initially, the rules
are stored as part of the system BIOS. At system boot time,


剩余358页未读,继续阅读
2018-09-20 上传
2018-09-13 上传
2019-02-19 上传
2020-08-10 上传
2023-11-20 上传
2021-04-22 上传
2021-04-22 上传
2021-06-15 上传
2023-07-11 上传

ssy630414
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Elasticsearch核心改进:实现Translog与索引线程分离
- 分享个人Vim与Git配置文件管理经验
- 文本动画新体验:textillate插件功能介绍
- Python图像处理库Pillow 2.5.2版本发布
- DeepClassifier:简化文本分类任务的深度学习库
- Java领域恩舒技术深度解析
- 渲染jquery-mentions的markdown-it-jquery-mention插件
- CompbuildREDUX:探索Minecraft的现实主义纹理包
- Nest框架的入门教程与部署指南
- Slack黑暗主题脚本教程:简易安装指南
- JavaScript开发进阶:探索develop-it-master项目
- SafeStbImageSharp:提升安全性与代码重构的图像处理库
- Python图像处理库Pillow 2.5.0版本发布
- mytest仓库功能测试与HTML实践
- MATLAB与Python对比分析——cw-09-jareod源代码探究
- KeyGenerator工具:自动化部署节点密钥生成
