
13!
Learning by gradient descent!
Iterative minimisation through gradient descent:!
236 5. NEURAL NETWORKS
Figure 5.5 Geometrical view of the error function E(w) as
a surface sitting over weight space. Point w
A
is
a local minimum and w
B
is the global minimum.
At any point w
C
, the local gradient of the error
surface is given by the vector ∇E.
w
1
w
2
E(w)
w
A
w
B
w
C
∇E
Following the discussion of Section 4.3.4, we see that the output unit activation
function, which corresponds to the canonical link, is given by the softmax function
y
k
(x, w)=
exp(a
k
(x, w))
!
j
exp(a
j
(x, w))
(5.25)
which satisfies 0 ! y
k
! 1 and
"
k
y
k
=1. Note that the y
k
(x, w) are unchanged
if a constant is added to all of the a
k
(x, w), causing the error function to be constant
for some directions in weight space. This degeneracy is removed if an appropriate
regularization term (Section 5.5) is added to the error function.
Once again, the derivative of the error function with respect to the activation for
a particular output unit takes the familiar form (5.18).Exercise 5.7
In summary, there is a natural choice of both output unit activation function
and matching error function, according to the type of problem being solved. For re-
gression we use linear outputs and a sum-of-squares error, for (multiple independent)
binary classifications we use logistic sigmoid outputs and a cross-entropy error func-
tion, and for multiclass classification we use softmax outputs with the corresponding
multiclass cross-entropy error function. For classification problems involving two
classes, we can use a single logistic sigmoid output, or alternatively we can use a
network with two outputs having a softmax output activation function.
5.2.1 Parameter optimization
We turn next to the task of finding a weight vector w which minimizes the
chosen function E(w). At this point, it is useful to have a geometrical picture of the
error function, which we can view as a surface sitting over weight space as shown in
Figure 5.5. First note that if we make a small step in weight space from w to w +δw
then the change in the error function is δE ≃ δw
T
∇E(w), where the vector ∇E(w)
points in the direction of greatest rate of increase of the error function. Because the
error E(w) is a smooth continuous function of w, its smallest value will occur at a
240 5. NEURAL NETWORKS
evaluations, each of which would require O(W ) steps. Thus, the computational
effort needed to find the minimum using such an approach would be O(W
3
).
Now compare this with an algorithm that makes use of the gradient information.
Because each evaluation of ∇E brings W items of information, we might hope to
find the minimum of the function in O(W ) gradient evaluations. As we shall see,
by using error backpropagation, each such evaluation takes only O(W ) steps and so
the minimum can now be found in O(W
2
) steps. For this reason, the use of gradient
information forms the basis of practical algorithms for training neural networks.
5.2.4 Gradient descent optimization
The simplest approach to using gradient information is to choose the weight
update in (5.27) to comprise a small step in the direction of the negative gradient, so
that
w
(τ+1)
= w
(τ)
− η∇E(w
(τ)
) (5.41)
where the parameter η > 0 is known as the learning rate. After each such update, the
gradient is re-evaluated for the new weight vector and the process repeated. Note that
the error function is defined with respect to a training set, and so each step requires
that the entire training set be processed in order to evaluate ∇E. Techniques that
use the whole data set at once are called batch methods. At each step the weight
vector is moved in the direction of the greatest rate of decrease of the error function,
and so this approach is known as gradient descent or steepest descent. Although
such an approach might intuitively seem reasonable, in fact it turns out to be a poor
algorithm, for reasons discussed in Bishop and Nabney (2008).
For batch optimization, there are more efficient methods, such as conjugate gra-
dients and quasi-Newton methods, which are much more robust and much faster
than simple gradient descent (Gill et al., 1981; Fletcher, 1987; Nocedal and Wright,
1999). Unlike gradient descent, these algorithms have the property that the error
function always decreases at each iteration unless the weight vector has arrived at a
local or global minimum.
In order to find a sufficiently good minimum, it may be necessary to run a
gradient-based algorithm multiple times, each time using a different randomly cho-
sen starting point, and comparing the resulting performance on an independent vali-
dation set.
There is, however, an on-line version of gradient descent that has proved useful
in practice for training neural networks on large data sets (Le Cun et al., 1989).
Error functions based on maximum likelihood for a set of independent observations
comprise a sum of terms, one for each data point
E(w)=
N
!
n=1
E
n
(w ). (5.42)
On-line gradient descent, also known as sequential gradient descent or stochastic
gradient descent, makes an update to the weight vector based on one data point at a
time, so that
w
(τ+1)
= w
(τ)
− η∇E
n
(w
(τ)
). (5.43)
currently estimated label!
5.2. Network Training 235
If we consider a training set of independent observations, then the error function,
which is given by the negative log likelihood, is then a cross-entropy error function
of the form
E(w)=−
N
!
n=1
{t
n
ln y
n
+ (1 − t
n
) ln(1 −y
n
)} (5.21)
where y
n
denotes y(x
n
, w ). Note that there is no analogue of the noise precision β
because the target values are assumed to be correctly labelled. However, the model
is easily extended to allow for labelling errors. Simard et al. (2003) found that usingExercise 5.4
the cross-entropy error function instead of the sum-of-squares for a classification
problem leads to faster training as well as improved generalization.
If we have K separate binary classifications to perform, then we can use a net-
work having K outputs each of which has a logistic sigmoid activation function.
Associated with each output is a binary class label t
k
∈ {0, 1}, where k =1,...,K.
If we assume that the class labels are independent, given the input vector, then the
conditional distribution of the targets is
p(t|x, w )=
K
"
k=1
y
k
(x, w)
t
k
[1 − y
k
(x, w)]
1−t
k
. (5.22)
Taking the negative logarithm of the corresponding likelihood function then gives
the following error functionExercise 5.5
E(w)=−
N
!
n=1
K
!
k=1
{t
nk
ln y
nk
+(1−t
nk
) ln(1 −y
nk
)} (5.23)
where y
nk
denotes y
k
(x
n
, w ). Again, the derivative of the error function with re-
spect to the activation for a particular output unit takes the form (5.18) just as in theExercise 5.6
regression case.
It is interesting to contrast the neural network solution to this problem with the
corresponding approach based on a linear classification model of the kind discussed
in Chapter 4. Suppose that we are using a standard two-layer network of the kind
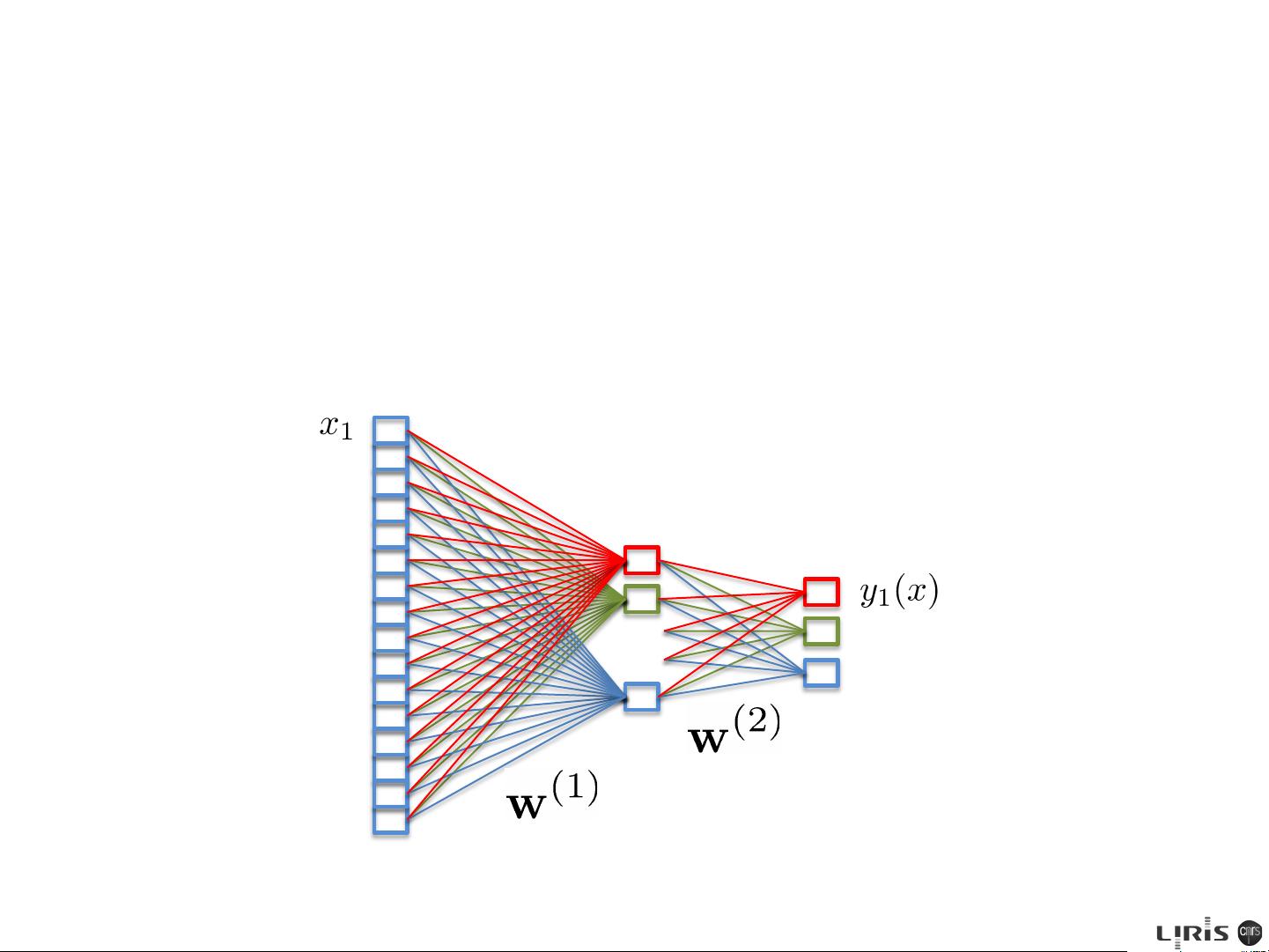
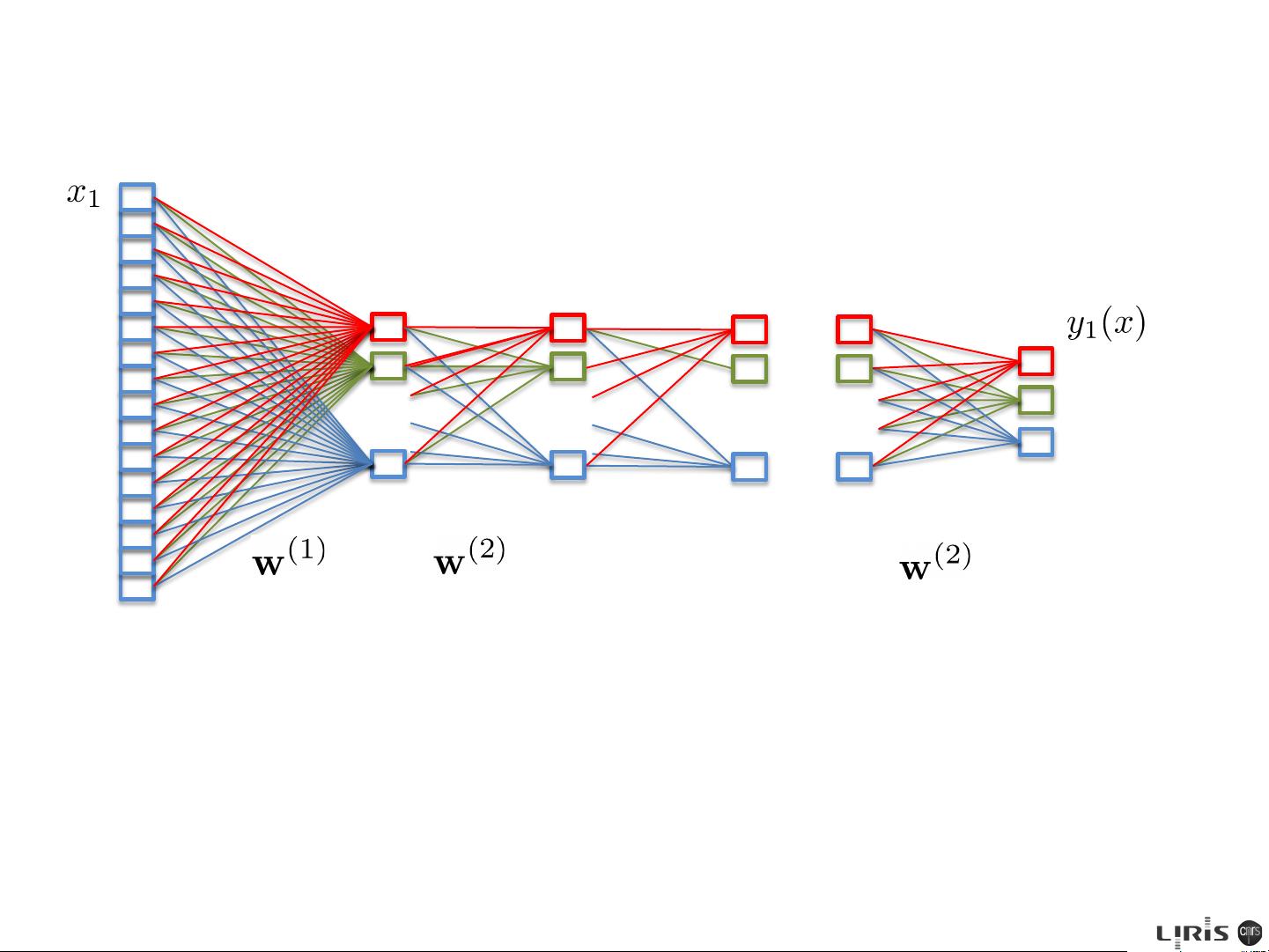
shown in Figure 5.1. We see that the weight parameters in the first layer of the
network are shared between the various outputs, whereas in the linear model each
classification problem is solved independently. The first layer of the network can
be viewed as performing a nonlinear feature extraction, and the sharing of features
between the different outputs can save on computation and can also lead to improved
generalization.
Finally, we consider the standard multiclass classification problem in which each
input is assigned to one of K mutually exclusive classes. The binary target variables
t
k
∈ {0, 1} have a 1-of-K coding scheme indicating the class, and the network
outputs are interpreted as y
k
(x, w)=p(t
k
=1|x), leading to the following error
function
E(w)=−
N
!
n=1
K
!
k=1
t
kn
ln y
k
(x
n
, w ). (5.24)
Given an error (loss) function:!
Can be blocked in a local
minimum (not that it matters
much …)!
[C. Bishop, Pattern recognition and Machine learning, 2006]!
target (ground-truth) label!


 我的内容管理
展开
我的内容管理
展开









