Python实现高斯判别分析实例:多元正态分布与参数估计
174 浏览量
更新于2024-08-31
收藏 429KB PDF 举报
本文将详细介绍如何在Python中实现高斯判别分析(Gaussian Discriminant Analysis, GDA)算法,这是一项用于解决多元分类问题的统计方法,特别是在输入特征是连续随机变量的情况下。GDA基于高斯分布假设,即每个类别对应的样本分布遵循多元正态分布,其参数包括均值向量μ和协方差矩阵∑。
首先,我们需要理解高斯分布的基本概念。多元正态分布由两个参数构成:均值向量μ,它表示数据点的中心位置;协方差矩阵∑,描述了不同特征间的关系,其对角线元素代表各特征的方差,非对角线元素则衡量特征间的相关性。协方差矩阵越大,数据点的分布越分散;反之,数据点更集中。
在GDA中,我们假设每个类别的观测值X给定类别y后,服从类条件概率p(x|y)的多元正态分布。算法的目标是估计这些参数,以便根据样本的特征来确定其所属类别。具体来说,我们最大化似然函数L,从而得到参数的估计:
1. **参数估计**:
- 对于每个类别c,我们有μc和∑c,它们通过最大化似然函数找到最优解,即:
- μc = E[X|Y=c]
- ∑c = E[(X-μc)(X-μc)^T | Y=c]
2. **决策规则**:
- 通常采用贝叶斯公式进行分类,计算后验概率p(y|x),选择具有最高后验概率的类别作为预测结果。
3. **Python实现示例**:
- 文章提供了实际的Python代码演示,展示了如何使用scikit-learn库中的`GaussianClassifier`来构建和训练GDA模型。通过实例,读者可以看到如何处理数据、拟合模型以及进行预测。
在实践中,GDA特别适用于特征之间存在线性关系或者数据维度较高的情况下,因为其假设所有类别的数据都遵循同一种类型的正态分布。然而,如果数据不符合这些假设,例如存在非线性关系或离群值,可能需要考虑使用其他更为复杂的模型。
总结,本文提供了Python实现高斯判别分析算法的详细步骤和代码示例,帮助读者理解和应用这一经典的统计学习方法来解决实际的分类问题。同时,理解协方差矩阵如何影响数据分布的形状,是理解GDA工作原理的关键。
python实现高斯判别分析算法的例子实现高斯判别分析算法的例子
今天小编就为大家分享一篇python实现高斯判别分析算法的例子,具有很好的参考价值,希望对大家有所帮助。一起跟随
小编过来看看吧
高斯判别分析算法(高斯判别分析算法(Gaussian discriminat analysis))
高斯判别算法是一个典型的生成学习算法(关于生成学习算法可以参考我的另外一篇博客)。在这个算法中,我们假设p(x|y)p(x|y)服从多
元正态分布。
注:在判别学习算法中,我们假设p(y|x)p(y|x)服从一维正态分布,这个很好类比,因为在模型中输入数据XX通常是拥有很多维度的,所
以对于XX的条件概率建模时要取多维正态分布。
多元正态分布多元正态分布
多元正态分布也叫多元高斯分布,这个分布的两个参数分别是平均向量μ∈Rnμ∈Rn和一个协方差矩阵∑∈Rn×n∑∈Rn×n
关于协方差矩阵的定义;假设XX是由nn个标量随机变量组成的列向量,并且μkμk是第kk个元素的期望值,即μk=E(Xk)μk=E(Xk),那么协
方差矩阵被定义为
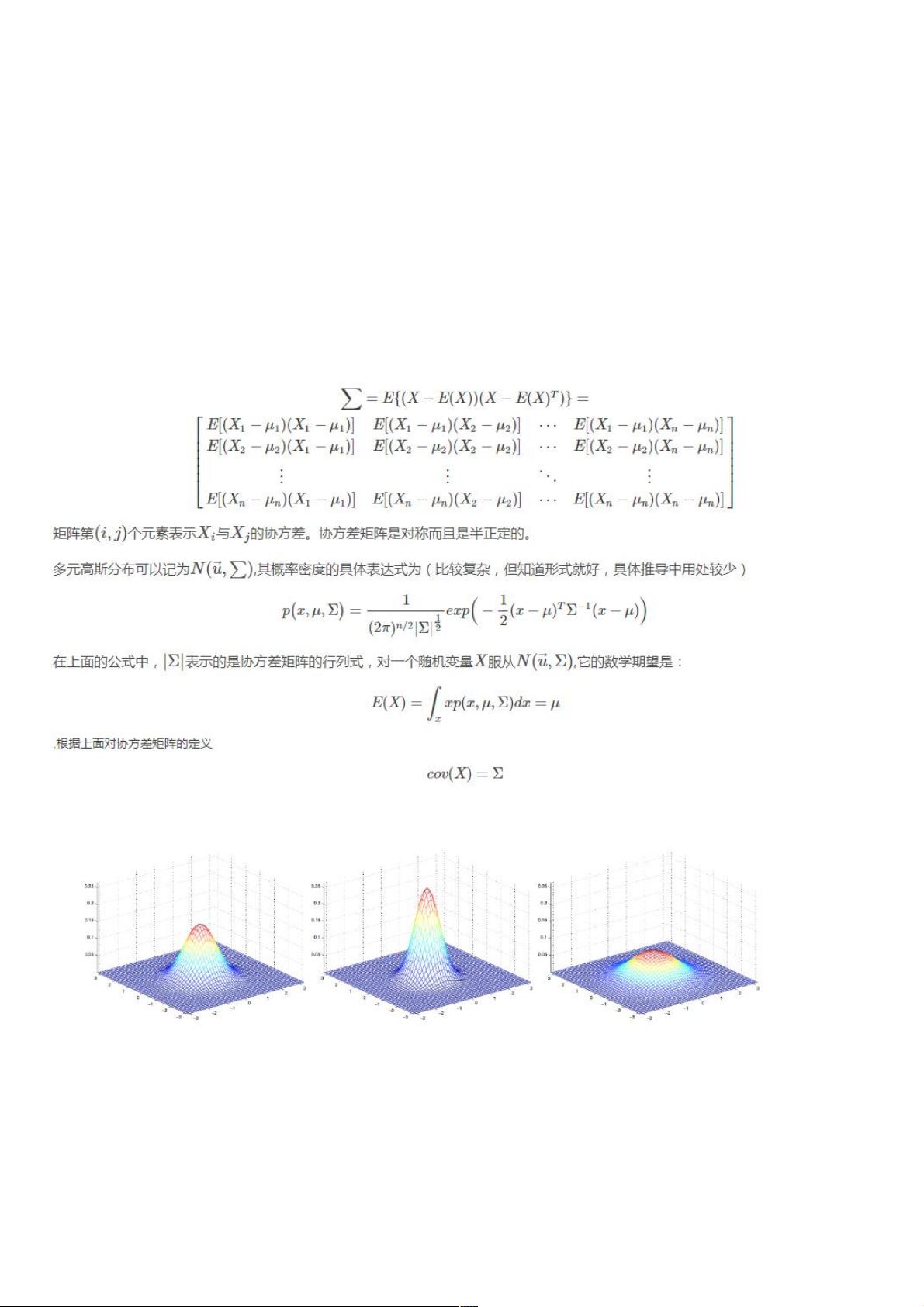
下面是一些二维高斯分布的概率密度图像:下面是一些二维高斯分布的概率密度图像:
最右边的图像展现的二维高斯分布的均值是零向量(2x1的零向量),协方差矩阵Σ=IΣ=I(2x2的单位矩阵),像这样以零向量为均值以单位
阵为协方差的多维高斯分布称为标准正态分布,中间的图像以零向量为均值,Σ=0.6IΣ=0.6I;最右边的图像中Σ=2IΣ=2I,观察发现当ΣΣ越
大时,高斯分布越“铺开”,当ΣΣ越小时,高斯分布越“收缩”。
让我们看一些其他例子对比发现规律让我们看一些其他例子对比发现规律
下载后可阅读完整内容,剩余5页未读,立即下载
2017-04-09 上传
2018-08-08 上传
2022-09-21 上传
2021-03-17 上传
138 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38522253
- 粉丝: 2
- 资源: 878
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
