Zookeeper、Kafka与Storm:分布式协作与实时流处理基石
需积分: 49 143 浏览量
更新于2024-07-21
收藏 1.19MB PPTX 举报
Zookeeper、Kafka和Storm是大数据领域中常见的分布式组件,它们各自扮演着重要的角色,共同构建了一个高效、可靠的分布式计算和消息传递平台。本文将详细介绍这三个组件的基本概念、功能以及它们之间的协作方式。
Zookeeper简介:
Zookeeper是一个开源的分布式协调服务,最初由LinkedIn开发,用于Hadoop生态系统。它具有以下核心特性:
1. **简单性**:Zookeeper提供了一个简化且易于使用的文件系统,使得分布式应用能够方便地进行状态管理和协调。
2. **表现力**:Zookeeper支持丰富的数据结构(如分布式队列、分布式锁、领导者选举等),使得开发者能轻松实现各种协调模式。
3. **高可用性**:Zookeeper通过在多台服务器上部署,形成一个集群,避免了单点故障,确保服务的连续性和可靠性。
4. **松耦合**:Zookeeper的通信机制使得参与者无需详细了解其他节点,只需与Zookeeper服务交互即可。
5. **资源库**:它提供了一套通用的协调模式,帮助开发者解决分布式环境中的一致性问题。
Zookeeper工作原理:
Zookeeper集群由一个Leader节点和多个Follower节点组成,每个节点都保存数据的副本。所有更新请求都会被转发到Leader节点处理,确保全局数据的一致性。客户端通过ZooKeeper的Java API建立连接,并使用create、exists、getData等方法进行操作。创建znode时,开发者需要注意节点数据的大小限制(不超过1MB),并且可以指定监听事件。例如,使用Watcher接口监视节点状态变化,当目录节点状态有变动时,Watcher的process方法会被调用。
Zookeeper典型应用:
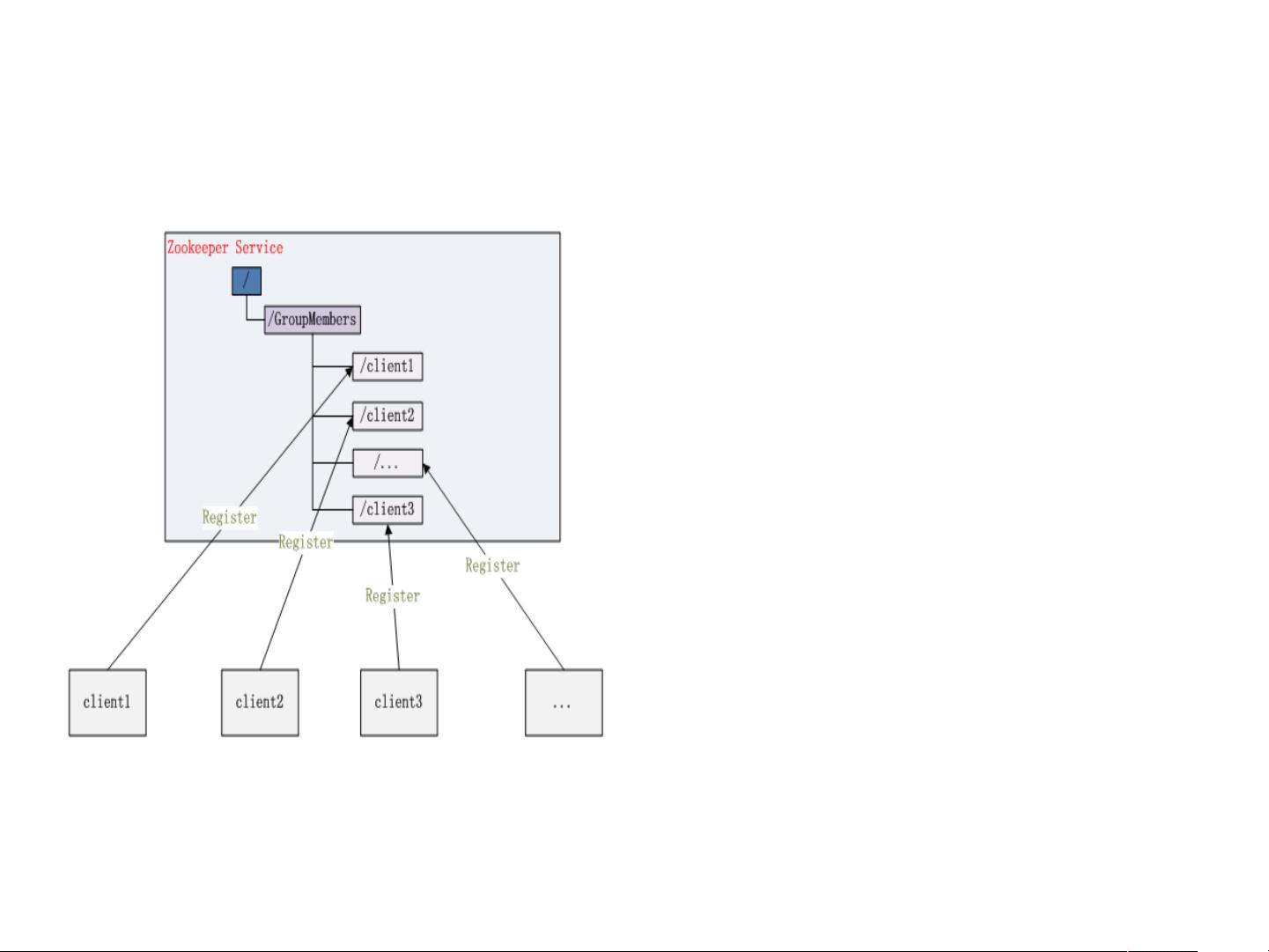
Zookeeper在分布式应用中的一个重要应用是配置管理。它提供了一种集中式的配置存储和分发机制,简化了分布式系统中配置的同步和变更控制,确保所有节点都能访问到相同的配置信息。
Kafka与Storm结合:
Kafka是一个分布式流处理平台,主要用于实时数据处理和发布/订阅模式的消息传递。它与Zookeeper紧密集成,Zookeeper用于存储Kafka的元数据,如主题(topic)和分区(partition)信息。在Storm中,Zookeeper被用来协调拓扑(topology)的部署和管理,如节点的注册和注销、任务分配等。
总结:
Zookeeper、Kafka和Storm三者相辅相成,共同构建了一个强大的分布式数据处理框架。Zookeeper提供了分布式系统的协调和一致性保障,Kafka则专注于高效的消息传输,而Storm则用于实时处理这些消息。理解并熟练运用这些组件,可以帮助开发者构建出稳定、可扩展的分布式应用程序。
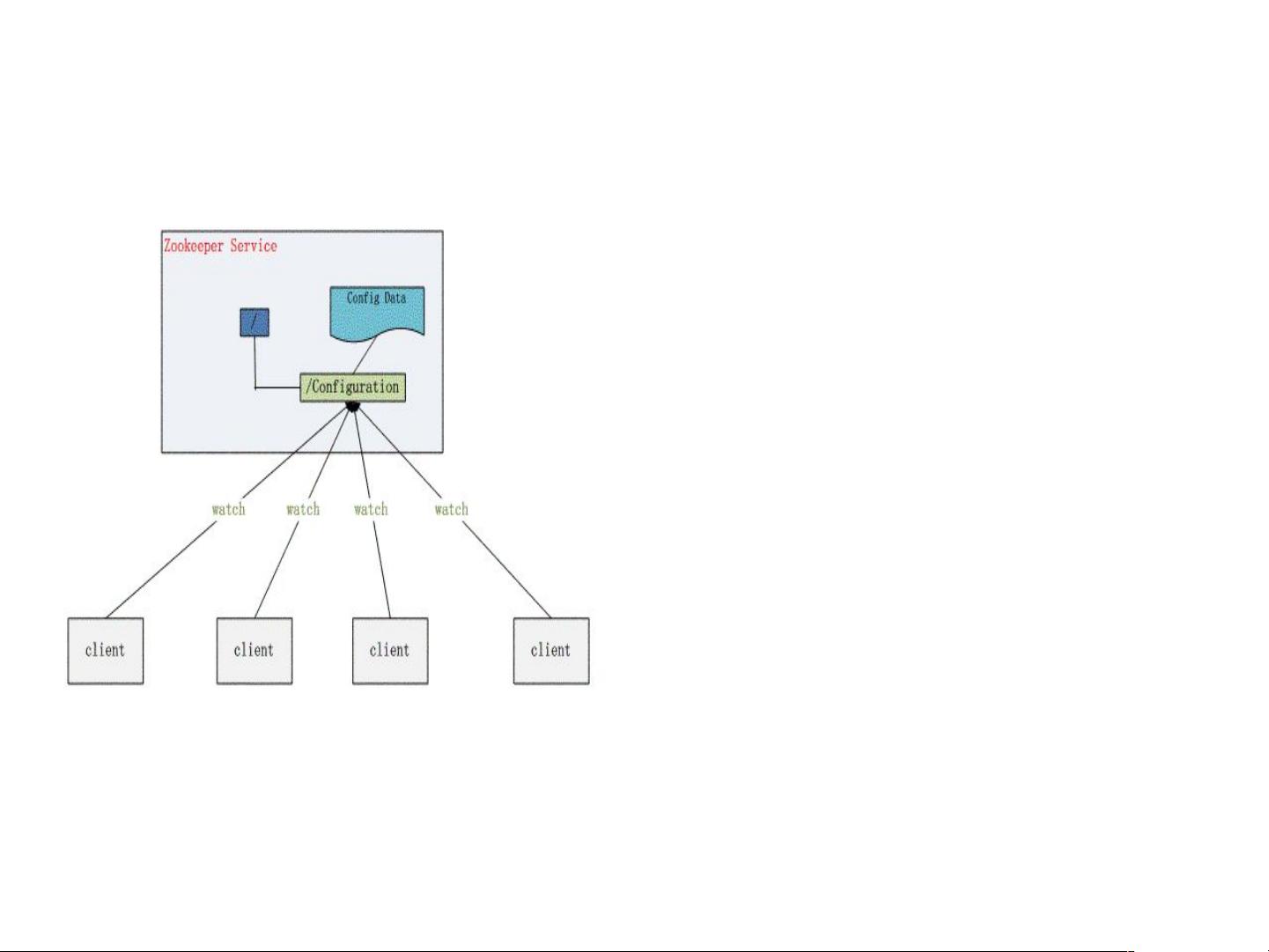
ZooKeeper 典型应用 -- 配置管理
•
配置的管理在分布式应用环境中
很常见,如果要修改这些相同的
配置项,那么就必须同时修改每
台运行这个应用系统的
,这样麻烦而且容易出错。
•
像这样的配置信息完全可以交给
来管理,将配置信息
保存在 的某个目录节
点中,然后将所有需要修改的应
用机器监控配置信息的状态,一
旦配置信息发生变化,每台应用
机器就会收到 的通知,
然后从 获取新的配置
信息应用到系统中。
剩余31页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2017-06-29 上传
2018-02-23 上传
2019-03-07 上传
2016-02-23 上传
2018-12-19 上传
2018-09-12 上传

lijh5257
- 粉丝: 0
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- app:詹金斯的应用程序
- react-hot-export-loader:一个Webpack加载器,自动插入react-hot-loader代码,灵感来自react-hot-loader-loader
- DIY制作属于自己的CP2102 USB-UART桥接器(原理图+PCB源文件)-电路方案
- 雅典:开源网络思想。 内部封闭测试正在进行中! 通过https:forms.gle9L1D1T7R3G7pvh1e7加入候补名单。 赞助我们以更快获得测试版!
- uni-app之flex布局教程 uniapp在线教程 uni app视频教程
- jamesSampica.github.io:自己的博客
- Android动画效果源代码
- 教师招聘学习软件支持幼儿教师招聘,小学中学教师招聘,小学中学教育学心理学等等
- LoveAndShare:基于Python django建造的知识分享与视频播放网站
- fp-gitlab-example:用于转换API请求以使用fp-ts的示例代码
- 彻底搞懂Spring+SpringMVC+MyBatis 框架整合(IDEA版,含源码)
- EmployeeWageComputation
- my-first-webpage
- getting_cleaning_data:回购获取和清洁数据; JHU课程; 数据科学专业
- MPLAB ICD2仿真器原理图+PCB+HEX文件-电路方案
- 灰白经典婚纱照网站模板
