Hadoop:大数据处理架构详解与应用
需积分: 13 59 浏览量
更新于2024-07-15
收藏 1.54MB PDF 举报
本资源《大数据处理技术》由昆明理工大学计算机科学与技术系的周海河编写,详细介绍了大数据处理架构中的核心——Hadoop。Hadoop是Apache软件基金会的重要开源项目,它起源于2002年的Apache Nutch项目,这个项目最初是一个文本搜索库,由 Doug Cutting 开发,后来发展成为处理大规模数据的分布式计算平台。
2.1 概述部分深入探讨了Hadoop的特点,首先,Hadoop基于Java语言,这使得它具有良好的跨平台性,能够在廉价硬件上部署,降低了大数据处理的入门门槛。其核心技术包括Hadoop Distributed File System (HDFS),这是一个分布式文件系统,为用户提供了一个高度容错的存储解决方案,以及MapReduce,这是一种分布式编程模型,用于在大量数据上并行执行任务。
Hadoop的分布式计算能力使其在业界得到了广泛的认可,几乎所有的主流科技公司,如谷歌、雅虎、微软、思科和淘宝等,都为其提供了相关的开发工具、开源软件、商业产品和服务,反映了其在大数据领域的领导地位。
2.2 Hadoop项目结构中,讲解了Hadoop的安装与使用,这部分内容对初次接触Hadoop的人来说至关重要,它会指导读者如何搭建Hadoop环境,配置和管理HDFS和MapReduce,以及如何在实际项目中有效地利用这些工具进行数据处理。
Hadoop的发展历史中提到,Nutch项目在2004年引入了自己的分布式文件系统NDFS,这是HDFS的前身。而同年,谷歌的MapReduce思想的公开,对Hadoop的设计和实现产生了重大影响。随着时间的推移,Hadoop不断进化和完善,成为了大数据处理不可或缺的部分。
《大数据处理技术》的这一章节为读者提供了一个全面理解Hadoop及其在大数据领域应用的基础,无论是在理论层面还是实践操作,都是学习者探索大数据世界的重要起点。
《大数据处理技术》 昆明理工大学计算机科学与技术系 周海河 18908715777@189.cn
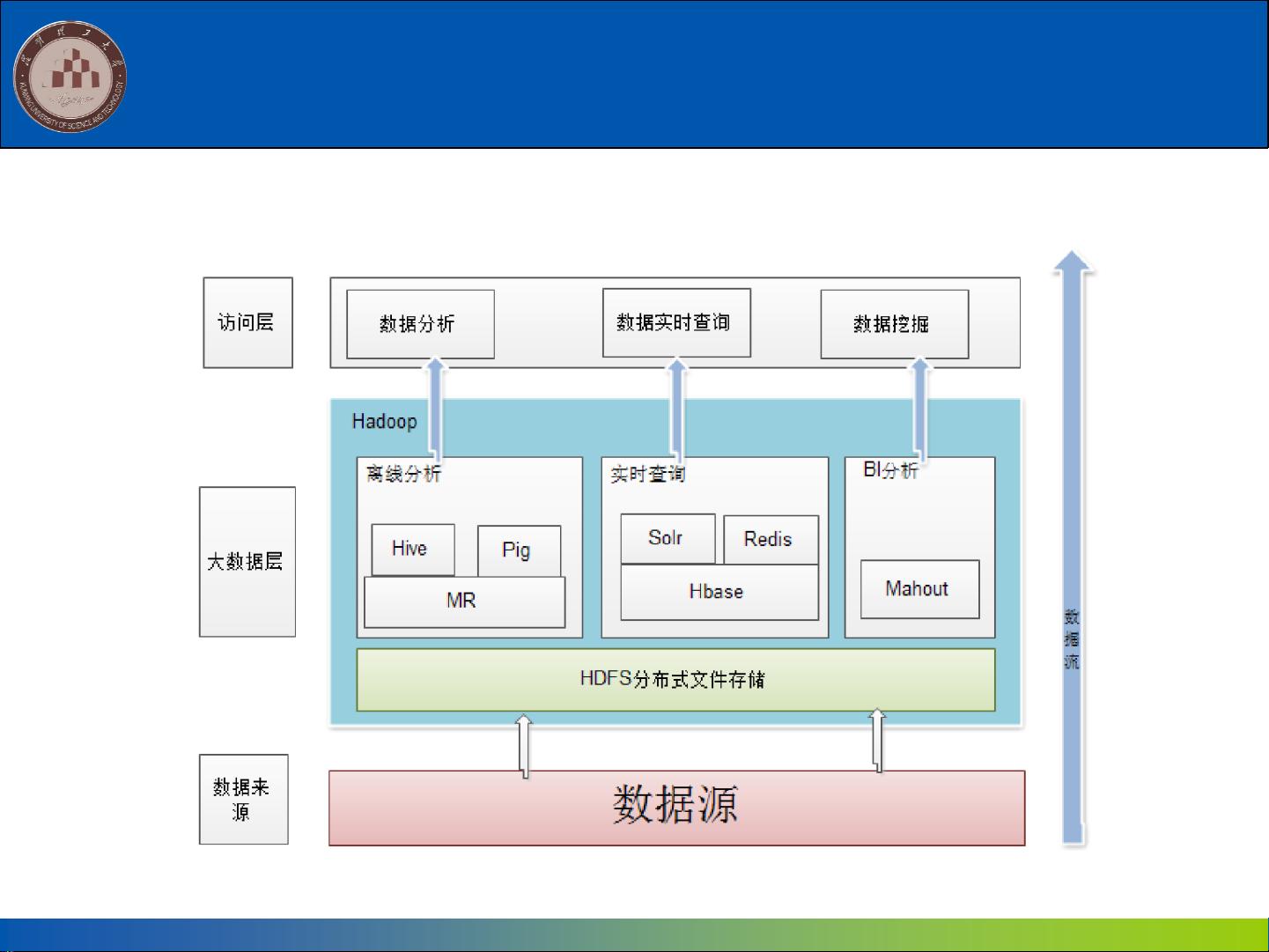
2.1.3 Hadoop的应用现状
Hadoop在企业中的应用架构
剩余42页未读,继续阅读
2020-05-30 上传
2021-07-14 上传
2023-07-02 上传
2023-08-15 上传
2023-06-05 上传
2023-11-07 上传
2024-09-24 上传
2023-06-10 上传
2023-06-10 上传

kmzhouhaihe
- 粉丝: 0
- 资源: 13
 我的内容管理
展开
我的内容管理
展开







最新资源
- 51单片机驱动DS1302时钟与LCD1602液晶屏万年历设计
- React 0.14.6版本源码分析与组件实践
- ChatGPT技术解读与应用分析白皮书
- 米-10直升机3D模型图纸下载-3DM格式
- Tsd Music Box v3.02:全面技术项目源码资源包
- 图像隐写技术:小波变换与SVD数字水印的Matlab实现
- PHP图片上传类源码教程及资源下载
- 掌握图像压缩技术:Matlab实现奇异值分解SVD
- Matlab万用表识别数字仪表教程及源码分享
- 三栏科技博客WordPress模板及丰富技术项目源码资源下载
- 【Matlab】图像隐写技术的改进LSB方法源码教程
- 响应式网站模板系列:右侧多级滑动式HTML5模板
- POCS算法超分辨率图像重建Matlab源码教程
- 基于Proteus的51单片机PWM波频率与占空比调整
- 易捷域名查询系统源码分享与学习交流平台
- 图像隐写术:Matlab实现SVD数字水印技术及其源码
