达观数据:Hive在大数据平台中的深度解析与实战应用
127 浏览量
更新于2024-08-27
收藏 487KB PDF 举报
达观数据分析平台架构和Hive实践主要探讨了Hadoop生态系统的发展历程及其在大数据处理中的重要角色。Hadoop自2006年成立以来,以其高效的数据存储、处理和分析能力,推动了大数据时代的到来,并且逐渐成为了行业的标准。在大数据处理中,Hive作为Hadoop的重要组成部分,扮演了数据仓库解决方案的角色,特别适合处理互联网产生的大规模数据,如TB或PB级别的原始数据。
Hive的核心价值在于其易用性,它允许数据分析师使用类似SQL的语言进行结构化查询,无需深入理解复杂的MapReduce编程模型。Hive的工作流程包括用户接口、驱动、编译器、元数据管理和执行引擎等组件,这些组件共同协作,使得数据处理过程更加简洁高效。
Hive的数据模型包括Table、ExternalTable、Partition和Bucket,它们分别代表了Hive中的不同数据组织形式,以满足不同场景下的数据存储和查询需求。例如,Table用于常规的数据存储,而Partition则支持按需分割数据,提高查询性能。
在达观数据的实践中,团队不仅积累了丰富的Hadoop技术和经验,还构建了一套完整的分布式大数据处理平台,涵盖了存储、分析、挖掘和应用等多个环节。通过本文,读者可以了解到Hive的基本原理,包括其设计初衷和组件构成,以及如何在实际项目中有效地使用Hive进行数据分析和优化。
作者分享的心得和实战经验涵盖了Hive的深入理解,强调了对于Hadoop和MapReduce模型的掌握对于Hive使用者的重要性,因为这有助于优化查询性能,提升数据处理效率。本文是一篇实用的指南,旨在帮助数据分析师和工程师更好地利用Hive进行大数据处理,提升工作效率。
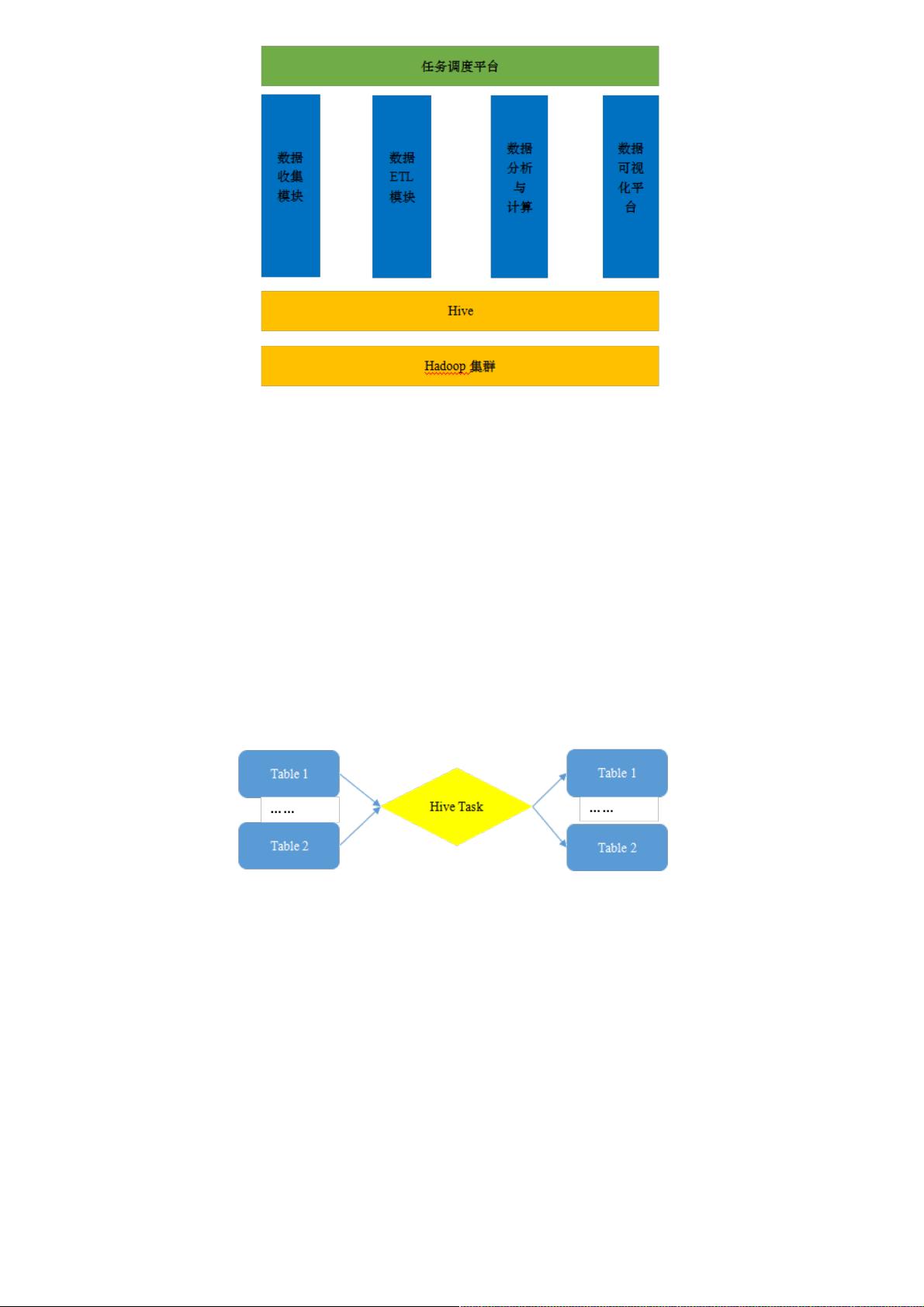
图:数据分析平台基本框架
数据收集模块
数据模块负责收集移动端app、网页端以及服务器端大量的日志数据。移动端可自行开发数据上报功能或者使用sdk来上报数
据。网页端利用植入的js将用户的行为进行上报,服务器端通过http server来收集上报的数据。服务器端的日志信息可以通过
DX模块(一个跨库的数据交换系统)来将待处理数据推入hive数据分析平台。除此之外,数据来源还包括大量的user 、item基本
数据等等。数据收集完成将所有需要处理分析的原始数据推入hadoop平台。从物理形式来看,即将待分析数据写入HDFS。
数据ETL模块
一般而言,上报的数据都是非结构化或者半结构化的。ETL(抽取、转换、加载)模块负责将所有的非结构或者半结构的数据
转换成结构化的数据并加载到hive库表中。例如对于用户访问日志(可能是web server日志),我们需要从每行日志中抽取出
用户的标识(cookie、imei或者userid),ip来源、url等。从形式上来看,ETL将HDFS的原始数据结构化,以表的形式提供分
析。
数据分析与计算
根据业务需求和功能,利用HQL实现各种统计分析。一个Hive任务的来源表可能是多个,结果数据也有可能会写入多张表。
图:Hive任务执行输入输出
任务调度系统
从上图可以看出,Hive任务之间存在依赖关系,不至于Hive任务之间存在依赖,Hive任务与DX任务之间、DX任务之间都可能
存在某种依赖关系,达观数据分析平台支持的任务类型还包括MR任务、shell任务等,达观数据分析平台自行开发司南调度系
统来完成平台中所有任务的调度。关于司南调度系统可见后续讨论。
数据分析平台模块
剩余10页未读,继续阅读
2320 浏览量
2203 浏览量
275 浏览量
246 浏览量
2024-12-30 上传
357 浏览量
186 浏览量
276 浏览量

weixin_38628626
- 粉丝: 5
- 资源: 944
 我的内容管理
展开
我的内容管理
展开







