学习尚硅谷大数据技术之Flume:快速入门与实战【章节导读】
 已收录资源合集
已收录资源合集
需积分: 0 3 浏览量
更新于2024-03-20
2
收藏 2.03MB PDF 举报
尚硅谷大数据技术之Flume是由尚硅谷大数据研发部提供的一个高可用、高可靠的分布式海量日志采集、聚合和传输系统。Flume基于流式架构,灵活简单,能够实时读取服务器本地磁盘的数据,并将数据写入到HDFS中。它是Cloudera推出的一个重要工具,能够满足大数据处理的需求。
Flume的基础架构如图1-1所示。其中,Agent是一个JVM进程,其作用是以事件的形式将数据从源头送至目的地。通过Agent的工作,Flume可以实现从不同数据源(如Python爬虫数据、Java后台日志数据、网络端口数据等)到HDFS的数据传输。Agent的功能不仅包括数据采集和传输,还能实现数据的过滤、转换等操作,为数据处理提供了更多灵活性和多样性。
在Flume的快速入门中,我们首先需要安装Flume。安装地址、文档查看地址和下载地址可以在官方文档中查看到。安装部署过程比较简单,只需按照官方指引进行操作即可。另外,为了方便监控Flume的运行状态,我们还可以设置监控端口来进行数据监控。这些基本的安装和配置工作是使用Flume的第一步,也是保证Flume正常运行的重要步骤。
在Flume的官方案例中,我们对Flume的具体应用进行了介绍。案例需求是使用Flume实现实时读取服务器本地磁盘的数据,然后将数据写入到HDFS中。这个案例展示了Flume在大数据处理中的重要作用,能够帮助用户快速、高效地完成数据采集和传输的工作。通过这个案例,我们可以更深入地理解Flume的工作原理和应用场景,为后续的数据处理工作奠定基础。
总的来说,Flume作为一款强大的数据采集工具,具有数据高可用性、高可靠性、分布式处理等优势,适用于各种数据源的接入和数据传输。通过学习Flume的相关知识和实践案例,我们可以更好地理解和应用Flume,为大数据处理工作提供更多可能性和解决方案。希望通过不断学习和实践,能够更深入地掌握Flume的工作原理和应用技巧,为大数据技术的发展和应用做出贡献。
尚硅谷大数据技术之 Flume
—————————————————————————————
实时读取本地文件到HDFS案例
# Name the components on this agent
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F /opt/module/hive/logs/hive.log
a2.sources.r2.shell = /bin/bash -c
# Describe the sink
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://hadoop102:9000/flume/%Y% m%d/%H
a2.sinks.k2.hdfs.filePrefix = logs-
a2.sinks.k2.hdfs.round = true
a2.sinks.k2.hdfs.roundValue = 1
a2.sinks.k2.hdfs.roundUnit = hour
a2.sinks.k2.hdfs.useLocalTimeStamp = true
a2.sinks.k2.hdfs.batchSize = 1000
a2.sinks.k2.hdfs.fileType = DataStream
a2.sinks.k2.hdfs.rollInterval = 60
a2.sinks.k2.hdfs.rollSize = 134217700
a2.sinks.k2.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2 .capacity = 1000
a2.channels.c2 .transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
#上传文件的前缀
#是否按照时间滚动文件夹
#多少时间单位创建一个新的文件夹
#重新定义时间单位
#是否使用本地时间戳
#积攒多少个Event才flush到HDFS一次
#设置文件类型,可支持压缩
#多久生成一个新的文件
#设置每个文件的滚动大小
#文件的滚动与Event数量无关
#定义source
#定义sink
#定义channel
#定义source类型为exec可执行命令的
#执行shell脚本的绝对路径
3.运行 Flume
[atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name
a2 --conf-file job/flume-file-hdfs.conf
4.开启 Hadoop 和 Hive 并操作 Hive 产生日志
[atguigu@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh
[atguigu@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh
[atguigu@hadoop102 hive]$ bin/hive
hive (default)>
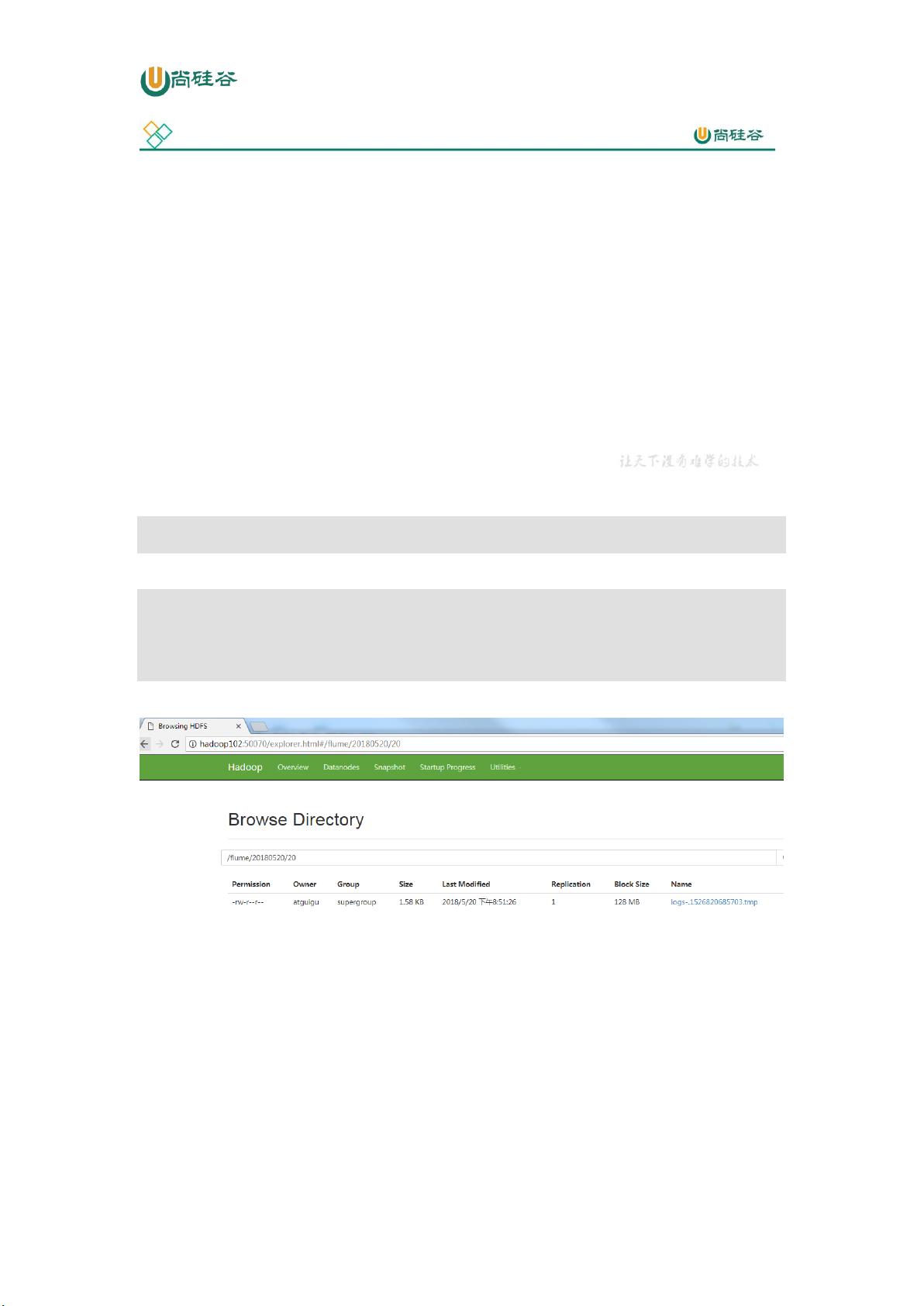
5.在 HDFS 上查看文件。
2.2.3 实时监控目录下多个新文件
1)案例需求:使用 Flume 监听整个目录的文件,并上传至 HDFS
2)需求分析:
剩余41页未读,继续阅读
2022-08-03 上传
2022-08-04 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

光与火花
- 粉丝: 27
- 资源: 335
 我的内容管理
展开
我的内容管理
展开







最新资源
- JHU荣誉单变量微积分课程教案介绍
- Naruto爱好者必备CLI测试应用
- Android应用显示Ignaz-Taschner-Gymnasium取消课程概览
- ASP学生信息档案管理系统毕业设计及完整源码
- Java商城源码解析:酒店管理系统快速开发指南
- 构建可解析文本框:.NET 3.5中实现文本解析与验证
- Java语言打造任天堂红白机模拟器—nes4j解析
- 基于Hadoop和Hive的网络流量分析工具介绍
- Unity实现帝国象棋:从游戏到复刻
- WordPress文档嵌入插件:无需浏览器插件即可上传和显示文档
- Android开源项目精选:优秀项目篇
- 黑色设计商务酷站模板 - 网站构建新选择
- Rollup插件去除JS文件横幅:横扫许可证头
- AngularDart中Hammock服务的使用与REST API集成
- 开源AVR编程器:高效、低成本的微控制器编程解决方案
- Anya Keller 图片组合的开发部署记录
