尚硅谷大数据技术:Kafka深度解析
需积分: 50 110 浏览量
更新于2024-07-17
收藏 6.07MB DOC 举报
"尚硅谷大数据技术之Kafka教程,适合零基础学员,内容覆盖Java新特性及深度技术,包括大量实战项目和面试题解析,旨在帮助学习者深入理解Kafka在大数据中的作用。"
在大数据领域,Kafka是一款广泛使用的消息队列系统,尤其在实时数据流处理中扮演着重要角色。本教程由尚硅谷大数据研发部提供,详细介绍了Kafka的基础知识和技术要点。
1. Kafka概述
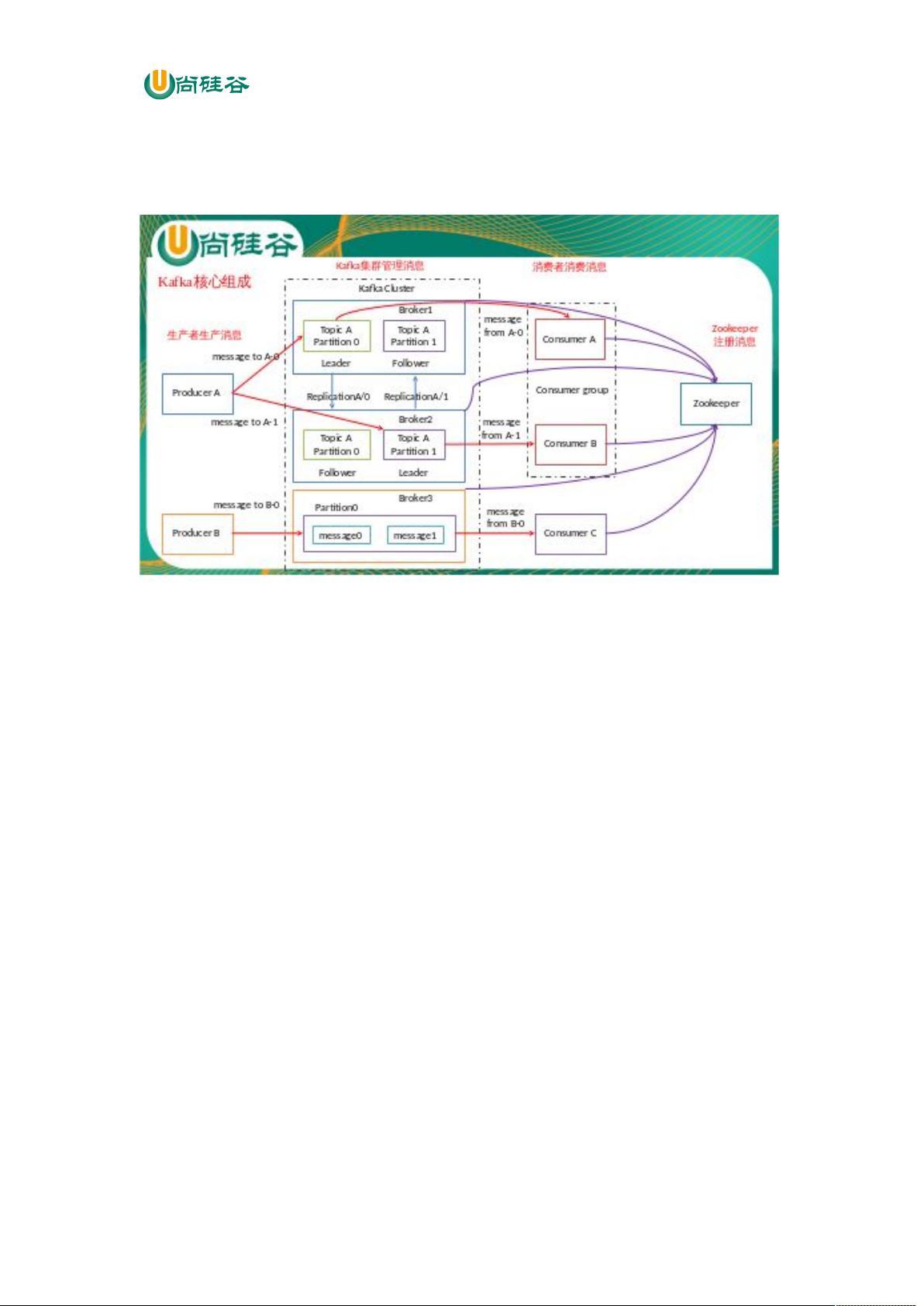
Kafka是一种分布式流处理平台,它主要设计用于构建实时数据管道和流应用程序。Kafka的核心概念包括生产者(Producer)、消费者(Consumer)和主题(Topic)。生产者负责发布消息到主题,消费者则订阅并消费这些消息。Kafka支持两种消息传递模式:
- 点对点模式:每个消息仅被一个消费者消费,消息在被接收后会被清除。
- 发布/订阅模式:一个主题可以有多个订阅者,消息会被推送给所有订阅者。
2. 为什么需要Kafka
- 解耦:Kafka作为中间件,使得生产者和消费者可以独立开发和扩展,只需遵循相同的接口规范。
- 冗余与数据安全:消息持久化存储,避免数据丢失,确保消息被正确处理后才删除。
- 扩展性:通过添加更多的消费者实例,轻松应对高负载。
- 灵活性与峰值处理:在流量激增时,Kafka能保证系统的稳定运行,避免因突发流量导致系统崩溃。
- 可恢复性:即使部分组件故障,系统其他部分仍能正常工作,提高系统稳定性。
- 顺序保证:Kafka的分区机制保证了分区内的消息有序性。
- 缓冲:平衡生产和消费速率,避免数据积压或消费过快。
- 异步通信:允许延迟处理消息,提高系统效率。
3. Kafka的使用场景
Kafka适用于日志收集、监控数据聚合、用户活动跟踪、流式处理等多种场景,尤其在大数据实时分析中,它能有效地处理和传输大规模数据。
4. 尚硅谷的教程特色
尚硅谷的教程针对零基础学员,采用生动的教学方式,涵盖Java新特性和深度技术,如JVM内存结构、设计模式等。课程内容丰富,包含大量代码实践和实战项目,旨在通过大量练习帮助学员掌握Kafka的使用和大数据处理技巧。
通过本教程的学习,学员不仅能掌握Kafka的基本操作,还能深入理解其在大数据环境下的应用,提升自己的专业技能,为未来在大数据领域的职业发展打下坚实基础。
尚硅谷大数据技术之 Kafka
—————————————————————————————
第 3 章 Kafka 工作流程分析
3.1 Kafka 生产过程分析
3.1.1 写入方式
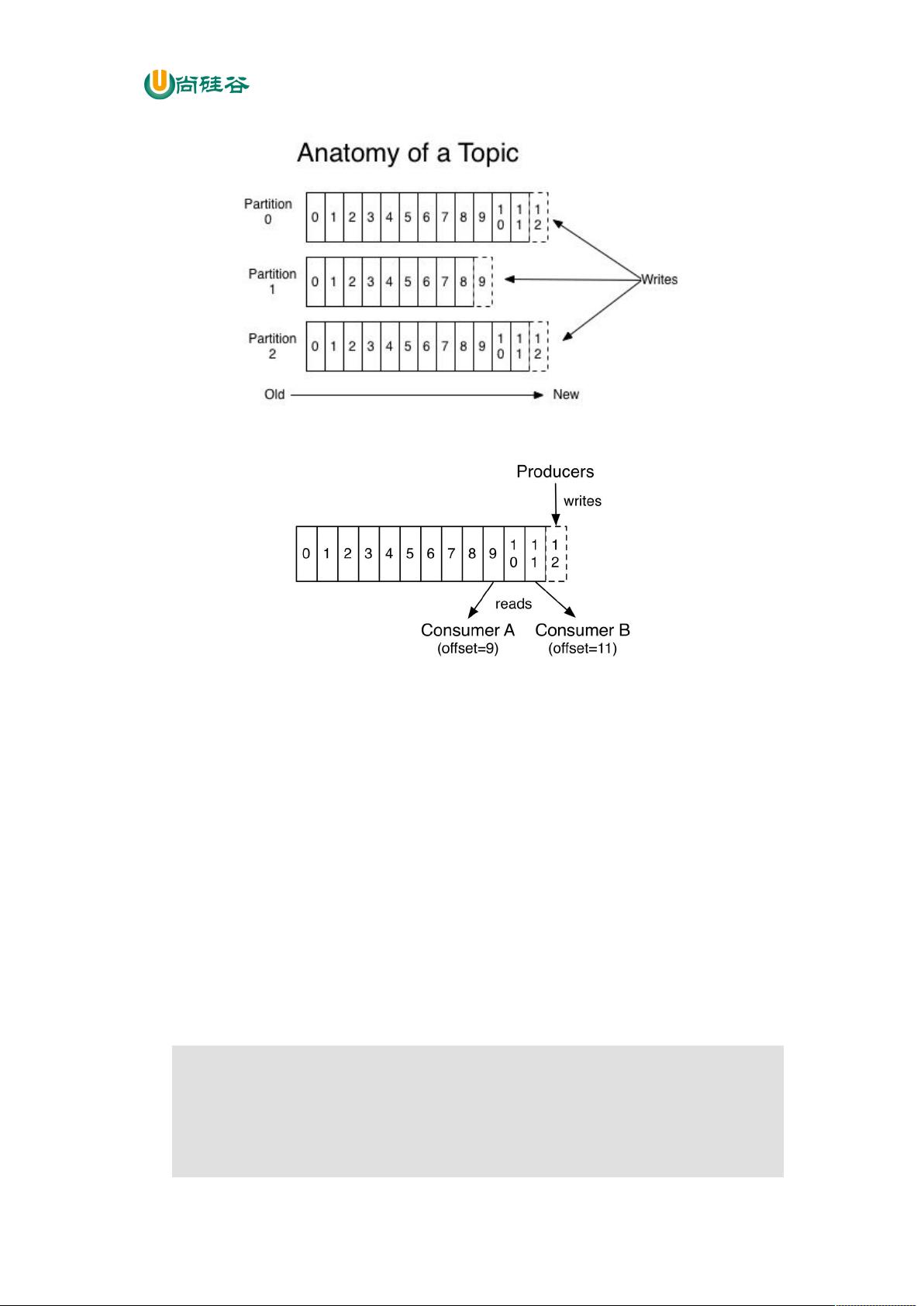
producer 采用推(push)模式将消息发布到 broker,每条消息都被追加(append)到分
区(patition)中,属于顺序写磁盘(顺序写磁盘效率比随机写内存要高,保障 kafka 吞吐
率)。
3.1.2 分区(Partition)
消息发送时都被发送到一个 topic,其本质就是一个目录,而 topic 是由一些 Partition
Logs(分区日志)组成,其组织结构如下图所示:
更多 Java –大数据 –前端 –python 人工智能资料下载,可百度访问:尚硅谷官网
剩余43页未读,继续阅读
2019-05-28 上传
2021-06-29 上传
2019-12-13 上传
2022-08-08 上传
2021-02-19 上传
点击了解资源详情

墨白与海.
- 粉丝: 10
- 资源: 92
 我的内容管理
展开
我的内容管理
展开







最新资源
- 网站绐终显示app_offline.htm的解决方法
- SQL2005常见错误排除
- wince教程wince教程
- SQL2005的数据类型详解
- Asp.net常用函数集锦
- linux下shell编程
- Windows应用程序捆绑核心编程
- Oracle 10g 的闪回恢复区 (PDF)
- 如何解决Oracle 常见错误 ORA-04031(PDF)
- 基于ASP_NET的在线考试系统的设计与实现.pdf
- 基于ASP_NET的网上购物系统的设计与实现.pdf
- 《Google搜索引擎优化指南》中英文电子版.pdf
- 学生成绩管理系统论文
- C C++常用算法实例.doc
- 很有实用价值的神奇代码 只要你在IE浏览器任意打开一个网站 就可以……
- linux+内核完全注释+修正版本v3.0.pdf(即linux内核完全刨析基于0.12内核)
