Spark大数据处理:数据倾斜优化策略与原理
需积分: 50 22 浏览量
更新于2024-07-18
收藏 7.17MB PDF 举报
"本文主要探讨了数据倾斜的概念、危害以及如何针对Spark进行数据倾斜优化,旨在帮助读者理解并解决大数据处理中的这一关键问题。"
在大数据处理中,数据倾斜是一个不容忽视的问题,尤其对于使用Spark或Hadoop等分布式计算框架的情况。数据倾斜指的是数据集在并行处理时,部分分区的数据量远超其他分区,导致这部分处理速度成为整个作业的瓶颈,严重影响系统性能和效率。
数据倾斜的主要后果包括:
1. OutOfMemory:当某一个Task需要处理的数据量过大,超过了其所在节点的内存限制,可能会引发内存溢出错误,导致任务失败。
2. 运行速度极慢:由于个别Task需处理的数据过多,整个作业的执行时间被显著拉长,效率降低,无法满足实时或近实时处理的需求。
数据倾斜通常在Shuffle阶段发生,由于相同Key的数据被聚集到同一个Task中处理,如果某个Key的数据量异常庞大,就会造成数据倾斜。这种现象在现实业务场景中并不罕见,遵循二八定律的分布模式往往容易导致此类问题。
解决数据倾斜需要从以下几个方面入手:
1. 搞定Shuffle:优化Shuffle过程,例如通过增加Shuffle Partition数量,分散数据负载,避免单个Task处理过多数据。
2. 适应业务场景:调整数据模型和算法,如采用更合理的分桶策略,或者对数据进行预处理,减少倾斜Key的出现。
3. 管理CPU和Core的使用:合理分配Task的数量和执行资源,确保每个Task分配到的数据量相对均衡。
4. 解决OOM问题:通过增大内存、调整GC策略或优化代码结构,减轻单个Task的内存压力。
理解数据倾斜的原理至关重要:在Shuffle操作中,相同Key的数据会被归并到同一Task,若某些Key的数据量过大,就会形成倾斜。例如,大部分Key对应少量数据,而少数Key对应大量数据,那么处理大量数据的Task将会成为性能瓶颈。
为解决这个问题,可以采取以下策略:
- Hash分区策略的改进:使用更复杂的分区函数,如基于范围或复合键的分区,以确保数据更均匀地分布在各个分区。
- 增加shuffle阶段的并发度:增加numPartitions,使数据更分散,减少单个分区过大的可能性。
- 数据预处理:在进行Shuffle之前,先对数据进行采样或聚合,减少倾斜Key的数量。
- 利用Spark的Coalesce或Repartition方法,重新分布数据,平衡数据负载。
理解并解决数据倾斜是提升Spark性能的关键。通过对Shuffle机制的深入理解,结合业务场景的优化,以及对资源管理的精细调整,可以有效地防止和应对数据倾斜问题,从而提高大数据处理的效率和稳定性。
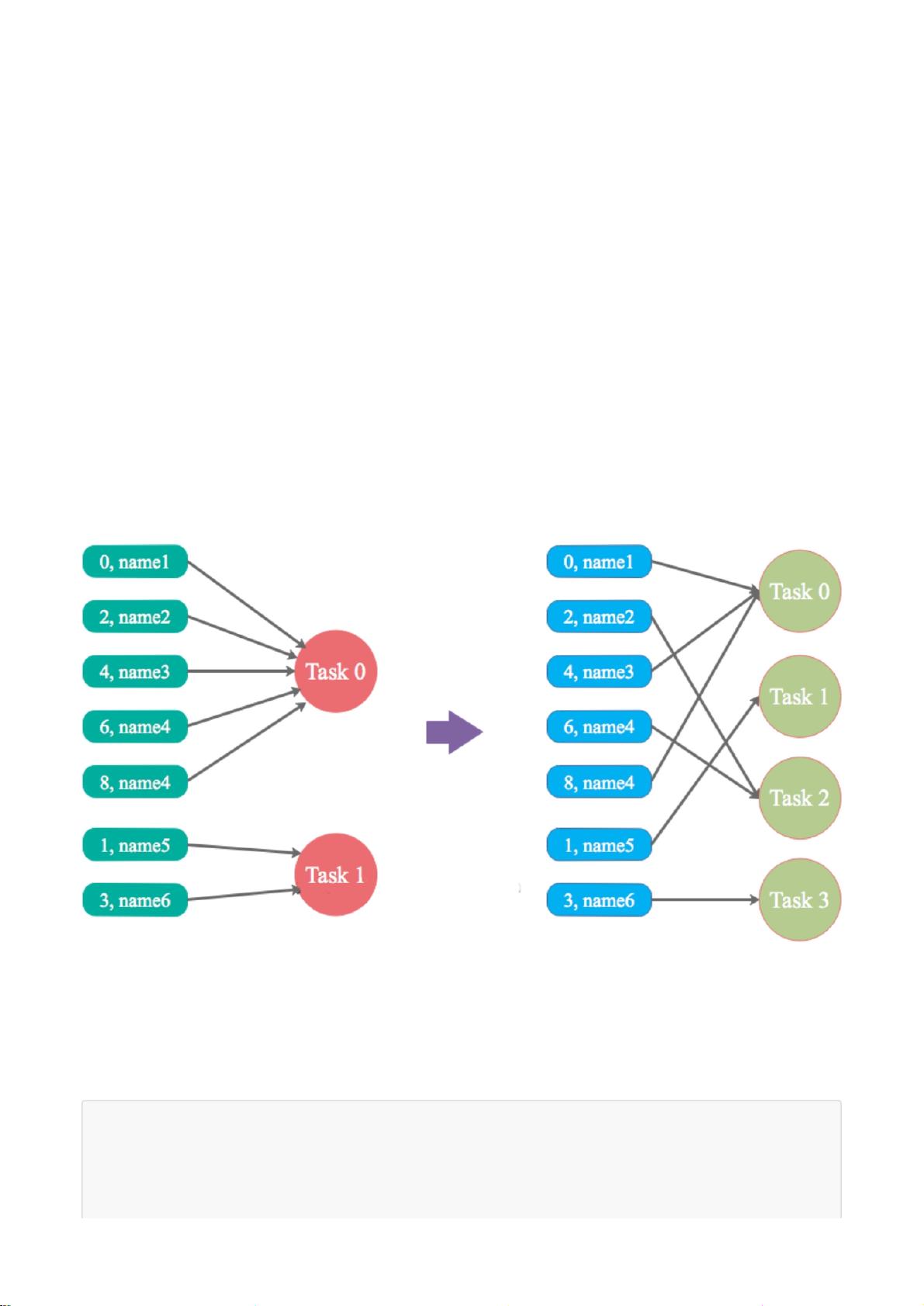
方案实现原理:增加shuffle read task的数量,可以让原本分配给一个task的多个key分配给多个task,从而让每个
task处理比原来更少的数据。举例来说,如果原本有5个key,每个key对应10条数据,这5个key都是分配给一个
task的,那么这个task就要处理50条数据。而增加了shuffle read task以后,每个task就分配到一个key,即每个
task就处理10条数据,那么自然每个task的执行时间都会变短了。具体原理如下图所示。
方案优点:实现起来比较简单,可以有效缓解和减轻数据倾斜的影响。
方案缺点:只是缓解了数据倾斜而已,没有彻底根除问题,根据实践经验来看,其效果有限。
方案实践经验:该方案通常无法彻底解决数据倾斜,因为如果出现一些极端情况,比如某个key对应的数据量有100
万,那么无论你的task数量增加到多少,这个对应着100万数据的key肯定还是会分配到一个task中去处理,因此注
定还是会发生数据倾斜的。所以这种方案只能说是在发现数据倾斜时尝试使用的第一种手段,尝试去用最简单的方
法缓解数据倾斜而已,或者是和其他方案结合起来使用。
原理
Spark在做Shuffle时,默认使用HashPartitioner(非Hash Shuffle)对数据进行分区。如果并行度设置的不合适,
可能造成大量不相同的Key对应的数据被分配到了同一个Task上,造成该Task所处理的数据远大于其它Task,从而
造成数据倾斜。
如果调整Shuffle时的并行度,使得原本被分配到同一Task的不同Key发配到不同Task上处理,则可降低原Task所需
处理的数据量,从而缓解数据倾斜问题造成的短板效应。
案例
现有一张测试数据集,内有100万条数据,每条数据有一个唯一的id值。现通过一些处理,使得id为90万之下的所
有数据对12取模后余数为8(即在Shuffle并行度为12时该数据集全部被HashPartition分配到第8个Task),其它数
据集id不变,从而使得id大于90万的数据在Shuffle时可被均匀分配到所有Task中,而id小于90万的数据全部分配到
同一个Task中。处理过程如下
scala> val sourceRdd = sc.textFile("hdfs://master01:9000/source_index")
sourceRdd: org.apache.spark.rdd.RDD[String] = hdfs://master01:9000/source_index
MapPartitionsRDD[1] at textFile at <console>:24
剩余30页未读,继续阅读
382 浏览量
950 浏览量
245 浏览量
543 浏览量
387 浏览量
点击了解资源详情
543 浏览量
307 浏览量
315 浏览量

HJ-铭
- 粉丝: 9
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- WMAN633:2021年Spring与Rota博士进行的定量生态学
- playground:一种新型的虚拟事件平台:penguin:
- ember-audio:Ember插件,可与Web Audio API超级EZ一起使用
- 行业分类-设备装置-压缩机内部空间划分结构.zip
- 哈尔滨工业大学同义词词林扩展版.rar
- 305372complier2563
- NStudio-开源
- Battleship-Clone
- ember-share:一个Ember插件,可使用ngrok(https:ngrok.com)与世界分享您的本地Ember应用程序
- jena-workspace:用于Apache Jena代码的工作区域
- javascript-jquery:一个Java
- OpenCV for Unity 2.3.3-1,支持安卓,IOS,Windows,WebGL,Linux,MacOS
- 【参赛作品】低成本的智能家居联网控制解决方案-电路方案
- ember-artisans:在Ember.js中使用网络工作者的抽象层
- android-sdk_r24.4.1-windows.7z
- 易语言源码ACCESS数据库分类统计.rar
