李志毅实验五:Flink-Kafka数据处理与问题解决
需积分: 0 159 浏览量
更新于2024-08-04
收藏 927KB DOCX 举报
本次实验是关于Flink消费Kafka数据的实践,由学生李志毅于2021年5月8日进行。实验是在前一个实验的基础上进行的,主要包括以下步骤:
1. **Zookeeper的安装与部署**:
实验首先安装并部署了Zookeeper,构建了一个Zookeeper集群,这是分布式系统中的一个重要组件,用于存储配置信息、命名服务和同步数据,为Flink等分布式应用提供一致性保证。
2. **Flink的安装与启动**:
接下来,学生安装了Apache Flink,这是一种开源的流处理框架,能够处理实时和批量数据。安装完成后,对Flink进行了验证,确保其正常运行,为后续的数据处理奠定了基础。
3. **Kafka的配置与对话测试**:
实验者安装并配置了Kafka,这是一个分布式发布订阅消息系统,用于生产者和消费者的通信。在这里,创建了一个topic(主题)并在master节点启动生产者,同时在slave01节点启动消费者,进行了实际的数据流对话测试,确保Kafka与Flink之间的数据传输顺畅。
4. **WordCount示例**:
实验的核心部分是实现一个WordCount程序,使用Flink从Kafka的数据流中读取消息,对文本进行分词并计算每个单词的出现频率。这展示了Flink的实时处理能力以及在大规模数据处理中的实用性。
在实验过程中,遇到了两个主要问题:
- **IntelliJ导入包出错**:
当尝试使用Maven安装依赖时,出现了Processterminated错误,原因是复制依赖包名时出现了错误。学生发现问题后,重新检查并修正了pom.xml中的依赖,学习到了在实验中细致操作的重要性。
- **启动WordCount类的错误**:
启动WordCount程序时,由于入口类定义错误,导致启动失败。学生通过仔细检查错误信息,发现应该直接将入口类设置为WordCount,修正后程序成功启动,锻炼了解决代码问题的能力。
整个实验不仅涉及到了Flink和Kafka的实战应用,还包含了软件工程的最佳实践,如正确管理依赖和调试代码。通过这个过程,学生不仅加深了对Flink和Kafka的理解,也提高了自己的问题解决技巧和编程规范意识。
课程实验五:Flink 消费 Kafka 数据
实验时间:2021 年 05 月 08 日
学生姓名:李志毅
学生班号、学号:2018211314 班 2018211582 号
一、 实验结果截图
注意:以下每一个结果截图,都必须需要包含所圈中标记信息(通过标记信息,
来判别作业是独立完成的)
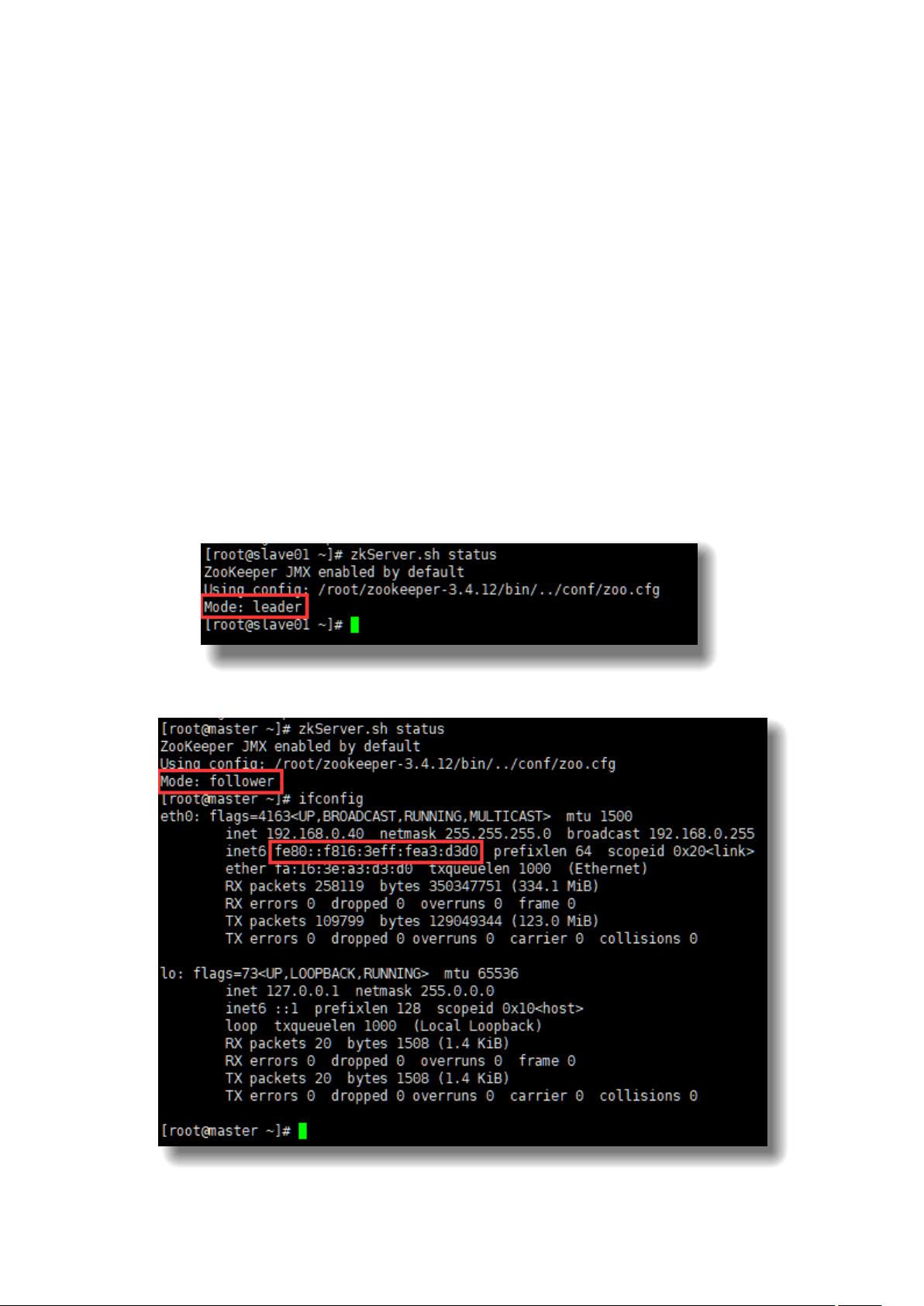
【结果截图 1】Zookeeper 安装验证
下载后可阅读完整内容,剩余9页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-08-03 上传
2022-08-08 上传
2022-08-08 上传
2022-08-08 上传
2022-08-08 上传
2022-08-08 上传

WaiyuetFung
- 粉丝: 946
 我的内容管理
展开
我的内容管理
展开







最新资源
- 彻底清除Office2003 安装残留问题
- Swift动画分类:深度利用CALayer实现
- Swift动画粒子系统:打造动态彗星效果
- 内存SPDTool:性能超频与配置新境界
- 使用JavaScript通过IP自动定位城市信息方法
- MPU6050官方英文资料包:产品规格与开发指南
- 全方位技术项目源码资源包下载与学习指南
- 全新蓝色卫浴网站管理系统模板介绍
- 使用Python进行Tkinter可视化开发的简易指南
- Go语言绑定Qt工具goqtuic的安装与使用指南
- 基于意见目标与词的情感分析研究与实践
- 如何制作精美的HTML网页模板
- Ruby开发中Better Errors提高Rack应用错误页面体验
- FusionMaps for Flex:多种开发环境下的应用指南
- reverse-theme:Emacs的逆向颜色主题介绍与安装
- Ant 1.2.6版本压缩包的下载指南
