SparkSQL Analyzer深度解析:转化与优化LogicalPlan
187 浏览量
更新于2024-08-27
收藏 260KB PDF 举报
"SparkSQLCatalyst源码分析之Analyzer"
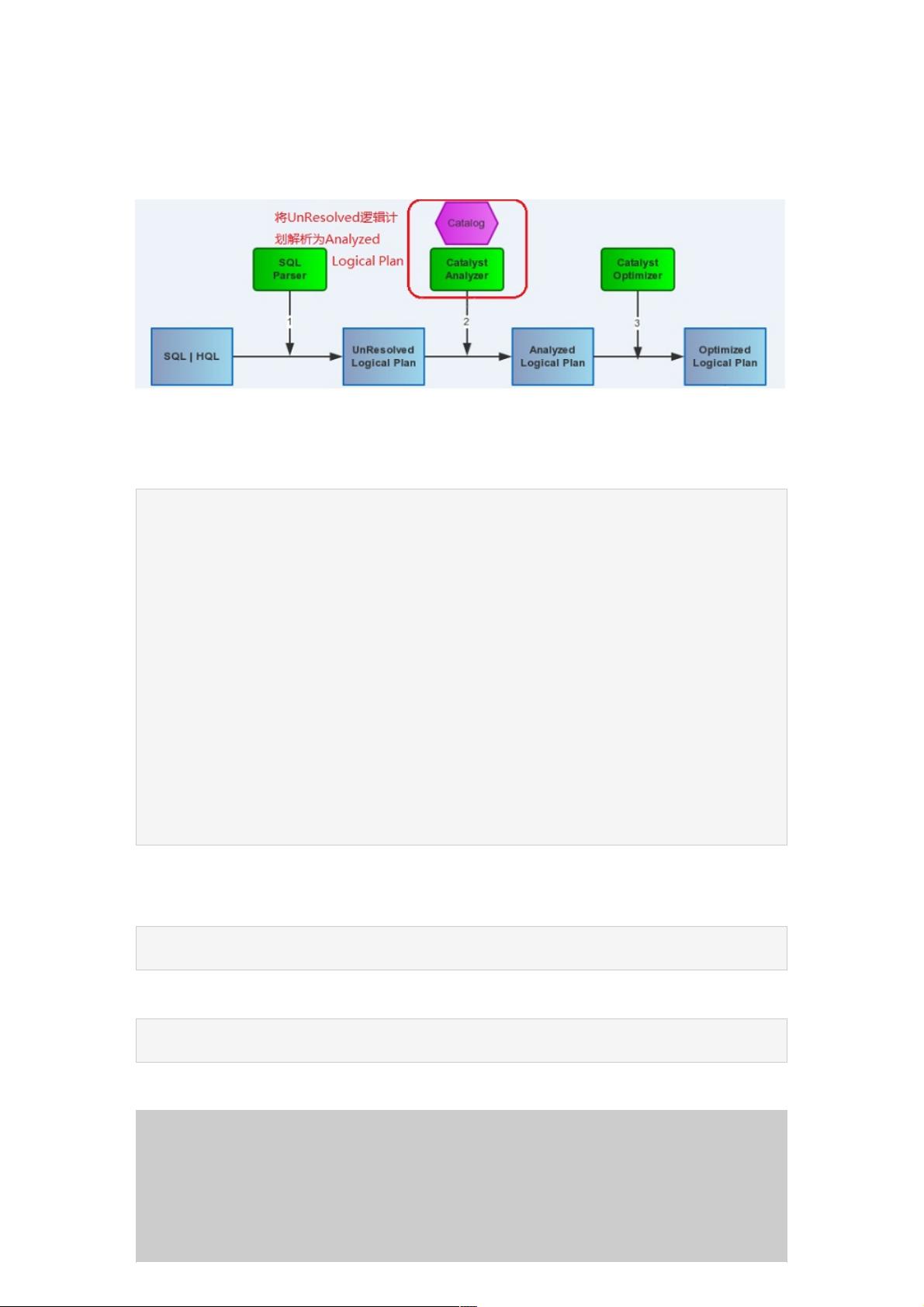
SparkSQL的Catalyst框架是其查询优化的核心部分,Analyzer作为其中的关键组件,扮演着将解析后的未解析(Unresolved)逻辑计划(LogicalPlan)转化为完全解析的逻辑计划的重要角色。Analyzer的主要任务是解决SqlParser在处理用户输入的SQL语句时未能完成的解析工作。
Analyzer位于Catalyst的`analysis`包内,它利用Catalog和FunctionRegistry来处理解析过程中遗留的`UnresolvedAttribute`和`UnresolvedRelation`。Catalog是一个存储元数据的接口,它包含了数据库、表以及它们的相关信息。FunctionRegistry则包含了所有可用的函数,包括内置函数和用户定义的函数。Analyzer通过这两个组件,确保所有的列引用和表引用都能被正确地关联到实际的数据源和函数。
Analyzer的构造函数接收三个参数:Catalog、FunctionRegistry和一个布尔值`caseSensitive`,用于确定是否区分大小写。Analyzer内部使用了一个`FixedPoint`对象,这是一个迭代次数可配置的规则执行器,确保分析过程能够达到稳定状态。`fixedPoint`变量设置了最多迭代100次,以防止无限循环。
Analyzer的工作流程被组织成多个批处理(Batches),每个批处理包含一系列规则。这些规则按顺序执行,以逐步完善逻辑计划。批处理包括:
1. MultiInstanceRelations:创建新的关系实例。
2. CaseInsensitiveAttributeReferences:根据`caseSensitive`参数,将列引用转换为大小写敏感或不敏感。
3. Resolution:这是一个固定点批处理,意味着它会一直执行直到没有更多的更改。该批处理包含了多个规则,如:
- ResolveReferences:解析列引用,将其与表中的实际字段关联。
- ResolveRelations:解析表引用,将它们映射到实际的表或者视图。
- NewRelationInstances:创建新的关系实例。
- ImplicitGenerate:隐式生成列。
- StarExpansion:处理星号(*)操作符,展开为表的所有列。
- ResolveFunctions:解析并注册函数调用。
- GlobalAggregates:处理全局聚合操作。
- typeCoercionRule:类型转换规则,确保数据类型的一致性。
通过以上步骤,Analyzer完成了对原始逻辑计划的解析,使其成为可以进一步优化和执行的完全解析计划。这个过程不仅涉及到基础的列和表解析,还包括函数解析、类型转换以及可能的优化操作,确保SparkSQL能够正确地理解并执行用户提交的SQL语句。
SparkSQLCatalyst源码分析之源码分析之Analyzer
前面几篇文章讲解了Spark SQL的核心执行流程和Spark SQL的Catalyst框架的Sql Parser是怎样接受用户输入sql,经过解析
生成Unresolved Logical Plan的。我们记得Spark SQL的执行流程中另一个核心的组件式Analyzer,本文将会介绍Analyzer在
Spark SQL里起到了什么作用。
Analyzer位于Catalyst的analysis package下,主要职责是将Sql Parser 未能Resolved的Logical Plan 给Resolved掉。
一、Analyzer构造
Analyzer会使用Catalog和FunctionRegistry将UnresolvedAttribute和UnresolvedRelation转换为catalyst里全类型的对象。
Analyzer里面有fixedPoint对象,一个Seq[Batch].
class Analyzer(catalog: Catalog, registry: FunctionRegistry, caseSensitive: Boolean)
extends RuleExecutor[LogicalPlan] with HiveTypeCoercion {
// TODO: pass this in as a parameter.
val fixedPoint = FixedPoint(100)
val batches: Seq[Batch] = Seq(
Batch("MultiInstanceRelations", Once,
NewRelationInstances),
Batch("CaseInsensitiveAttributeReferences", Once,
(if (caseSensitive) Nil else LowercaseAttributeReferences :: Nil) : _*),
Batch("Resolution", fixedPoint,
ResolveReferences ::
ResolveRelations ::
NewRelationInstances ::
ImplicitGenerate ::
StarExpansion ::
ResolveFunctions ::
GlobalAggregates ::
typeCoercionRules :_*),
Batch("AnalysisOperators", fixedPoint,
EliminateAnalysisOperators)
)
Analyzer里的一些对象解释:
FixedPoint:相当于迭代次数的上限。
/** A strategy that runs until fix point or maxIterations times, whichever comes first. */
case class FixedPoint(maxIterations: Int) extends Strategy
Batch: 批次,这个对象是由一系列Rule组成的,采用一个策略(策略其实是迭代几次的别名吧,eg:Once)
/** A batch of rules. */,
protected case class Batch(name: String, strategy: Strategy, rules: Rule[TreeType]*)
Rule:理解为一种规则,这种规则会应用到Logical Plan 从而将UnResolved 转变为Resolved
下载后可阅读完整内容,剩余7页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-03-03 上传
2021-03-03 上传
2021-01-30 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38626943
- 粉丝: 5
- 资源: 935
 我的内容管理
展开
我的内容管理
展开







最新资源
- JHU荣誉单变量微积分课程教案介绍
- Naruto爱好者必备CLI测试应用
- Android应用显示Ignaz-Taschner-Gymnasium取消课程概览
- ASP学生信息档案管理系统毕业设计及完整源码
- Java商城源码解析:酒店管理系统快速开发指南
- 构建可解析文本框:.NET 3.5中实现文本解析与验证
- Java语言打造任天堂红白机模拟器—nes4j解析
- 基于Hadoop和Hive的网络流量分析工具介绍
- Unity实现帝国象棋:从游戏到复刻
- WordPress文档嵌入插件:无需浏览器插件即可上传和显示文档
- Android开源项目精选:优秀项目篇
- 黑色设计商务酷站模板 - 网站构建新选择
- Rollup插件去除JS文件横幅:横扫许可证头
- AngularDart中Hammock服务的使用与REST API集成
- 开源AVR编程器:高效、低成本的微控制器编程解决方案
- Anya Keller 图片组合的开发部署记录
