深入解析Java HashMap与ConcurrentHashMap
33 浏览量
更新于2024-08-28
收藏 1.94MB PDF 举报
"深入解析JavaHashMap与ConcurrentHashMap的实现机制"
HashMap是Java中常用的数据结构,它基于数组和链表的结合实现,提供快速的Key-Value存储。在JDK 1.7中,HashMap的内部结构是一个数组,每个数组元素是一个链表,这种结构允许在O(1)的时间复杂度内进行插入、删除和查找操作。数组的大小初始为16,负载因子默认为0.75。当元素数量达到负载因子与当前容量的乘积时,HashMap会进行扩容,扩容过程会导致原有的数据重新分布,可能影响性能。因此,预估HashMap大小并在创建时指定可以避免频繁扩容,提高效率。
HashMap的核心成员变量包括:
- 桶大小`initialCapacity`,默认16
- 桶最大值`maxSize`
- 负载因子`loadFactor`,默认0.75
- 存放数据的数组`table`
- Map存放数量的大小`size`
- 可以自定义的桶大小和负载因子
`put`方法是HashMap的主要操作之一,它首先检查数组是否已初始化,然后计算Key的哈希值,根据哈希值找到对应桶的位置。如果桶中存在相同Key的Entry,就会覆盖旧值并返回旧值;如果桶为空,就新添加一个Entry。
JDK 1.8对HashMap的实现进行了优化,引入了红黑树(Red-Black Tree)的概念。当链表长度超过8时,链表会转换为红黑树,这样在处理大量冲突的情况下,查找、插入和删除的平均时间复杂度降低到O(logn),进一步提升了性能。
接下来,我们转向并发容器ConcurrentHashMap。它是线程安全的HashMap实现,特别适用于多线程环境。在JDK 1.7中,ConcurrentHashMap使用分段锁(Segment)来实现线程安全,每个Segment是一个独立的HashMap,通过锁分段,大大减少了锁的粒度,提高了并发性能。每个Segment包含一个HashEntry数组,结构与HashMap类似,但增加了锁机制。
JDK 1.8进一步优化了ConcurrentHashMap,取消了Segment,改用基于 CAS(Compare and Swap)的无锁算法和树化节点。这样,ConcurrentHashMap在保持高并发性能的同时,也提供了更细粒度的同步控制,使得其在多线程环境下表现更优。
总结来说,HashMap是基础的非线程安全的Key-Value存储结构,适合单线程环境;而ConcurrentHashMap则通过锁机制或无锁算法实现了线程安全,适用于多线程环境。了解它们的实现原理对于优化程序性能、编写高效并发代码至关重要。
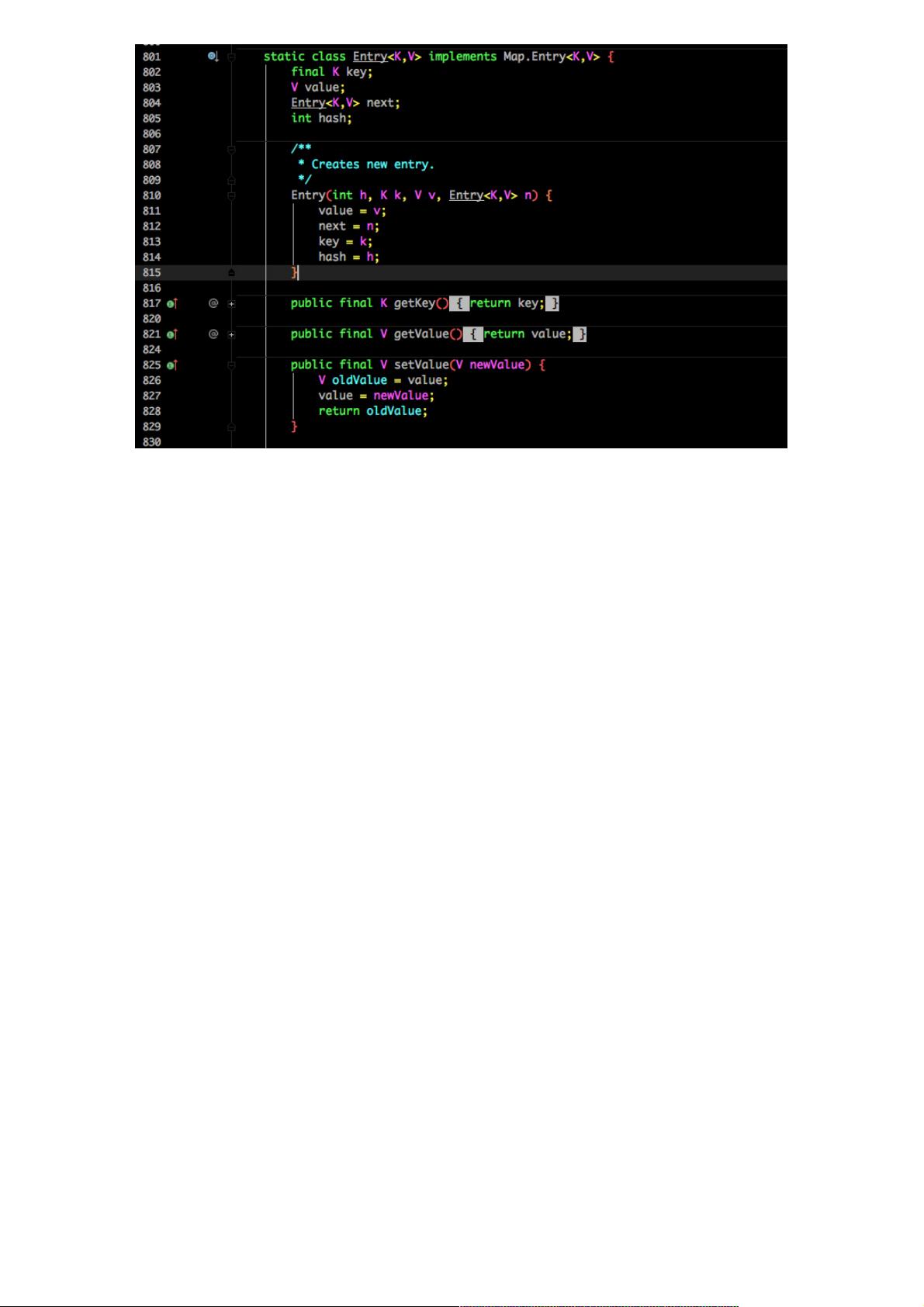
Entry 是 HashMap 中的一个内部类,从他的成员变量很容易看出:
key 就是写入时的键。
value 自然就是值。
开始的时候就提到 HashMap 是由数组和链表组成,所以这个 next 就是用于实现链表结构。
hash 存放的是当前 key 的 hashcode。
知晓了基本结构,那来看看其中重要的写入、获取函数:
put 方法
判断当前数组是否需要初始化。
如果 key 为空,则 put 一个空值进去。
根据 key 计算出 hashcode。
根据计算出的 hashcode 定位出所在桶。
如果桶是一个链表则需要遍历判断里面的 hashcode、key 是否和传入 key 相等,如果相等则进行覆盖,并返回原来的值。
如果桶是空的,说明当前位置没有数据存入;新增一个 Entry 对象写入当前位置。
当调用 addEntry 写入 Entry 时需要判断是否需要扩容。
如果需要就进行两倍扩充,并将当前的 key 重新 hash 并定位。
而在 createEntry 中会将当前位置的桶传入到新建的桶中,如果当前桶有值就会在位置形成链表。
get 方法
再来看看 get 函数:
首先也是根据 key 计算出 hashcode,然后定位到具体的桶中。
判断该位置是否为链表。
不是链表就根据 key、key 的 hashcode 是否相等来返回值。
为链表则需要遍历直到 key 及 hashcode 相等时候就返回值。
啥都没取到就直接返回 null 。
Base 1.8
不知道 1.7 的实现大家看出需要优化的点没有?
剩余11页未读,继续阅读
2019-10-22 上传
点击了解资源详情
2023-04-20 上传
2023-08-24 上传
2023-03-17 上传
2023-10-09 上传
2023-08-31 上传
2024-03-24 上传
2023-11-16 上传

weixin_38695751
- 粉丝: 7
- 资源: 961
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java集合ArrayList实现字符串管理及效果展示
- 实现2D3D相机拾取射线的关键技术
- LiveLy-公寓管理门户:创新体验与技术实现
- 易语言打造的快捷禁止程序运行小工具
- Microgateway核心:实现配置和插件的主端口转发
- 掌握Java基本操作:增删查改入门代码详解
- Apache Tomcat 7.0.109 Windows版下载指南
- Qt实现文件系统浏览器界面设计与功能开发
- ReactJS新手实验:搭建与运行教程
- 探索生成艺术:几个月创意Processing实验
- Django框架下Cisco IOx平台实战开发案例源码解析
- 在Linux环境下配置Java版VTK开发环境
- 29街网上城市公司网站系统v1.0:企业建站全面解决方案
- WordPress CMB2插件的Suggest字段类型使用教程
- TCP协议实现的Java桌面聊天客户端应用
- ANR-WatchDog: 检测Android应用无响应并报告异常
