深入理解Hive:优化与MapReduce解析
需积分: 7 189 浏览量
更新于2024-07-21
收藏 1.58MB PDF 举报
“Hive高级编程,涉及Hive组件、MapReduce、HiveQL、Hive优化和SQL优化。”
在大数据处理领域,Hive是构建在Hadoop生态系统之上的一种数据仓库工具,它允许用户通过类SQL的查询语言HiveQL来处理和分析存储在HDFS中的大规模数据。本课程主要关注Hive的高级编程,涵盖了以下几个核心概念:
1. **Hive组件**:Hive由多个关键组件构成,包括Hive CLI(命令行接口)用于交互式查询,DDL(数据定义语言)用于表的创建和管理,以及元数据存储(MetaStore)用于存储表的结构信息。此外,Hive还利用MapReduce进行分布式计算,Thrift API提供跨语言服务,SerDe(序列化和反序列化)处理数据的输入和输出,优化器负责查询计划的生成,而执行器则负责实际的数据处理。WebUI则提供了图形化的界面供用户监控和管理Hive。
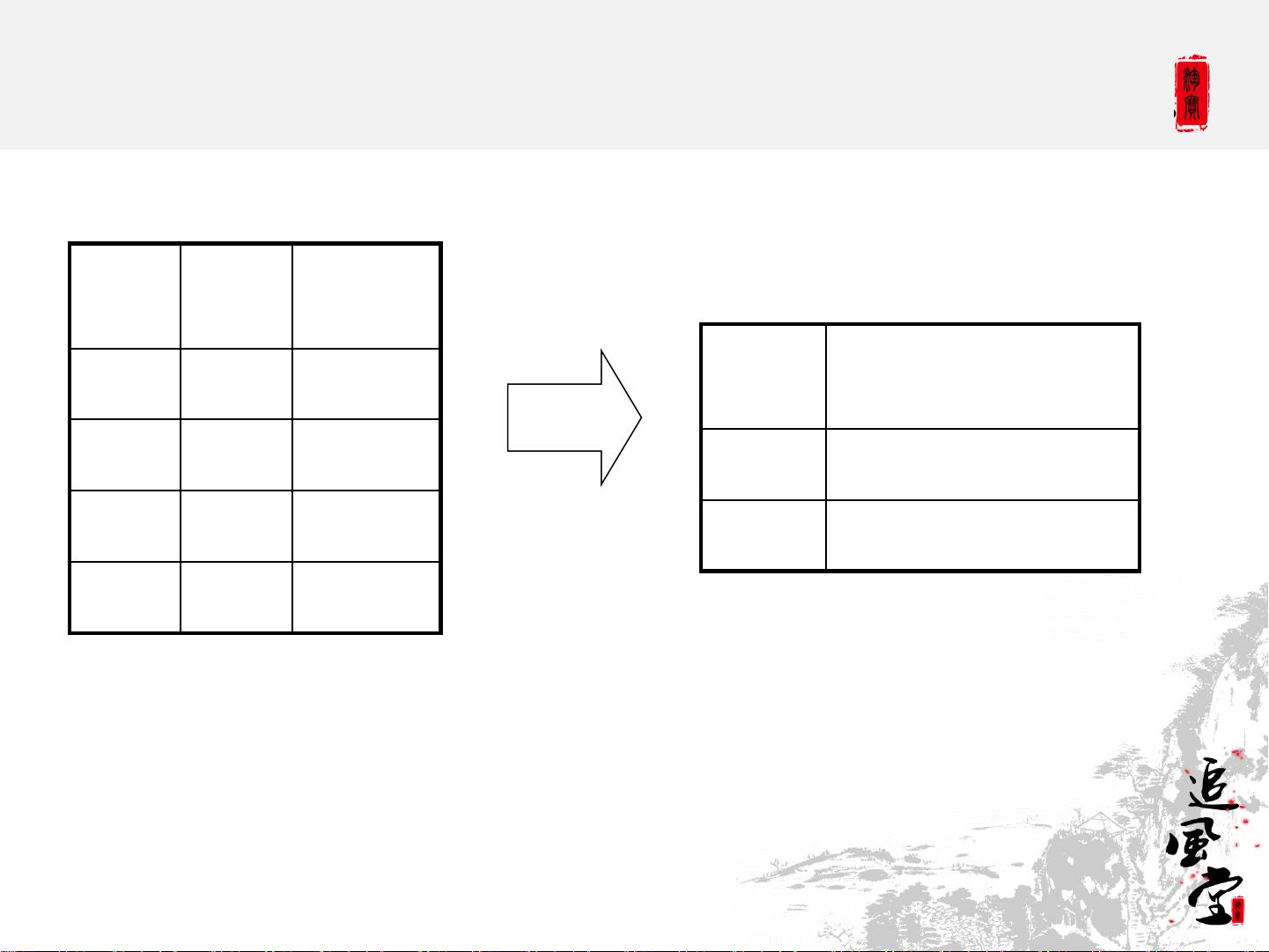
2. **MapReduce**:Hive的执行引擎基于MapReduce,这是一个由Google提出的分布式计算模型,包含Map阶段和Reduce阶段。Map阶段将数据分片并进行预处理,Reduce阶段则聚合Map阶段的结果。在这个过程中,数据首先通过本地排序(Local Sort)和全局排序(Global Shuffle),然后被送入Reduce阶段进行最终处理。
3. **HiveQL**:HiveQL是Hive的查询语言,与SQL非常相似,但具有针对分布式环境的优化。例如,HiveQL支持JOIN操作,如示例中的`INNER JOIN`,将两个表`page_view`和`user`按照共同的`userid`字段连接,生成新的表`pv_users`。
4. **Hive优化**:Hive的性能优化主要包括查询优化和数据倾斜优化。查询优化涉及选择合适的分区策略、避免全表扫描、合理使用索引、减少JOIN操作以及使用STORING子句来减少JOIN操作的数据交换。数据倾斜优化则是解决某些键值对在MapReduce中分布不均的问题,可以通过重新分区、负载均衡或者定制化分区函数来改善。
5. **SQL优化**:在Hive中,SQL查询的性能直接影响到处理大数据的速度。优化SQL查询包括使用适当的JOIN类型(如MERGE JOIN或HASH JOIN)、避免使用子查询、减少数据倾斜、使用bucketing和skewjoin处理、以及对大型JOIN操作使用分桶等技术。
Hive作为大数据处理的重要工具,其高级编程涉及到诸多细节,包括如何编写高效的HiveQL语句、理解Hive与MapReduce的交互机制,以及如何优化查询性能。这些知识点对于数据分析师和大数据工程师来说至关重要,有助于提升数据处理的效率和准确性。
Hive QL – Group By in Map Reduce
pagei
d
age
1 25
2 25
pv_users
pagei
d
1
1
pageid_age_sum
pagei
d
age
1 32
2 25
Map
key value
<1,2
5>
1
<2,2
5>
1
key value
<1,3
2>
1
<2,2
5>
1
key value
<1,2
5>
1
<1,3
2>
1
key value
<2,2
5>
1
<2,2
5>
1
Shuffle
Sort
pagei
d
2
Reduce
剩余40页未读,继续阅读
405 浏览量
2021-12-25 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

zhucanjie
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 实现类似百度的邮箱自动提示功能
- C++基础教程源码剖析与下载指南
- Matlab实现Franck-Condon因子振动重叠积分计算
- MapGIS操作手册:坐标系与地图制作指南
- SpringMVC+MyBatis实现bootstrap风格OA系统源码分享
- Web工程错误页面配置与404页面设计模板详解
- BPMN可视化示例库:展示多种功能使用方法
- 使用JXLS库轻松导出Java对象集合为Excel文件示例教程
- C8051F020单片机编程:全面控制与显示技术应用
- FSCapture 7.0:高效网页截图与编辑工具
- 获取SQL Server 2000 JDBC驱动免分数Jar包
- EZ-USB通用驱动程序源代码学习参考
- Xilinx FPGA与CPLD配置:Verilog源代码教程
- C#使用Spierxls.dll库打印Excel表格技巧
- HDDM:C++库构建与高效数据I/O解决方案
- Android Diary应用开发:使用共享首选项和ViewPager
