Facebook的Apache Spark Shuffle I/O 优化:Spark-optimized Shuffle (SO...
需积分: 10 177 浏览量
更新于2024-07-18
收藏 11.67MB PDF 举报
"Apache Spark Shuffle I/O 在 Facebook 的优化 [PDF]"
Apache Spark 是一个流行的分布式数据处理框架,其中Shuffle操作是其核心组件之一,它发生在Spark作业的多个阶段之间,用于重新组织数据以实现数据分区和并行计算。然而,Shuffle操作往往伴随着高昂的I/O成本,特别是在大规模数据处理时,可能会导致大量的磁盘写入和低效的读取操作。Facebook在面临这样的挑战后,开发了一项名为Spark-optimized Shuffle (SOS)的技术来解决这个问题。
在传统的Spark Shuffle过程中,所有mapper任务产生的数据都会被写入磁盘,形成shuffle files,然后被reducer任务逐一读取。这种模式随着数据量的增长,会导致大量的碎片化I/O请求,对硬盘造成极大的压力。例如,在Facebook的环境中,单个Job的Shuffle可能会产生超过300TB的数据,使得I/O性能成为系统瓶颈,延长作业执行时间,并消耗大量系统资源。
SOS技术的主要目标是通过将大量的小规模shuffle读请求合并为少量的大规模顺序I/O请求,从而显著改善这一状况。通过这种方式,Facebook能够减少磁盘的随机访问,提升I/O效率。据描述,应用SOS后,Facebook的作业整体I/O性能提升了两倍,计算效率提高了10%。这意味着,不仅减少了磁盘的负载,也缩短了作业的执行时间,提升了系统的整体性能。
Facebook计划将这项技术开源,与社区共享,以帮助其他面临相同问题的组织和开发者。SOS的引入,不仅仅是技术上的突破,也为大数据处理领域的优化提供了新的思路。它强调了在面对大规模数据时,如何通过改进数据读写策略来提高系统的吞吐量和效率。
在调整Spark作业时,通常的做法是调整任务数量,但这并不能根本解决问题。因为任务过多会导致磁盘I/O碎片化,而任务过少则可能导致内存溢出,增加磁盘spill。SOS提供了一种更有效的方法,通过优化Shuffle过程中的I/O行为,从根本上解决了这个问题。
Spark-optimized Shuffle (SOS)技术是Facebook对大数据处理中Shuffle性能瓶颈的有力回应。通过改变shuffle操作的I/O模式,SOS显著提升了处理大规模数据的效率,减少了对硬件资源的依赖,对于Spark用户来说,这无疑是一项具有重大意义的优化。
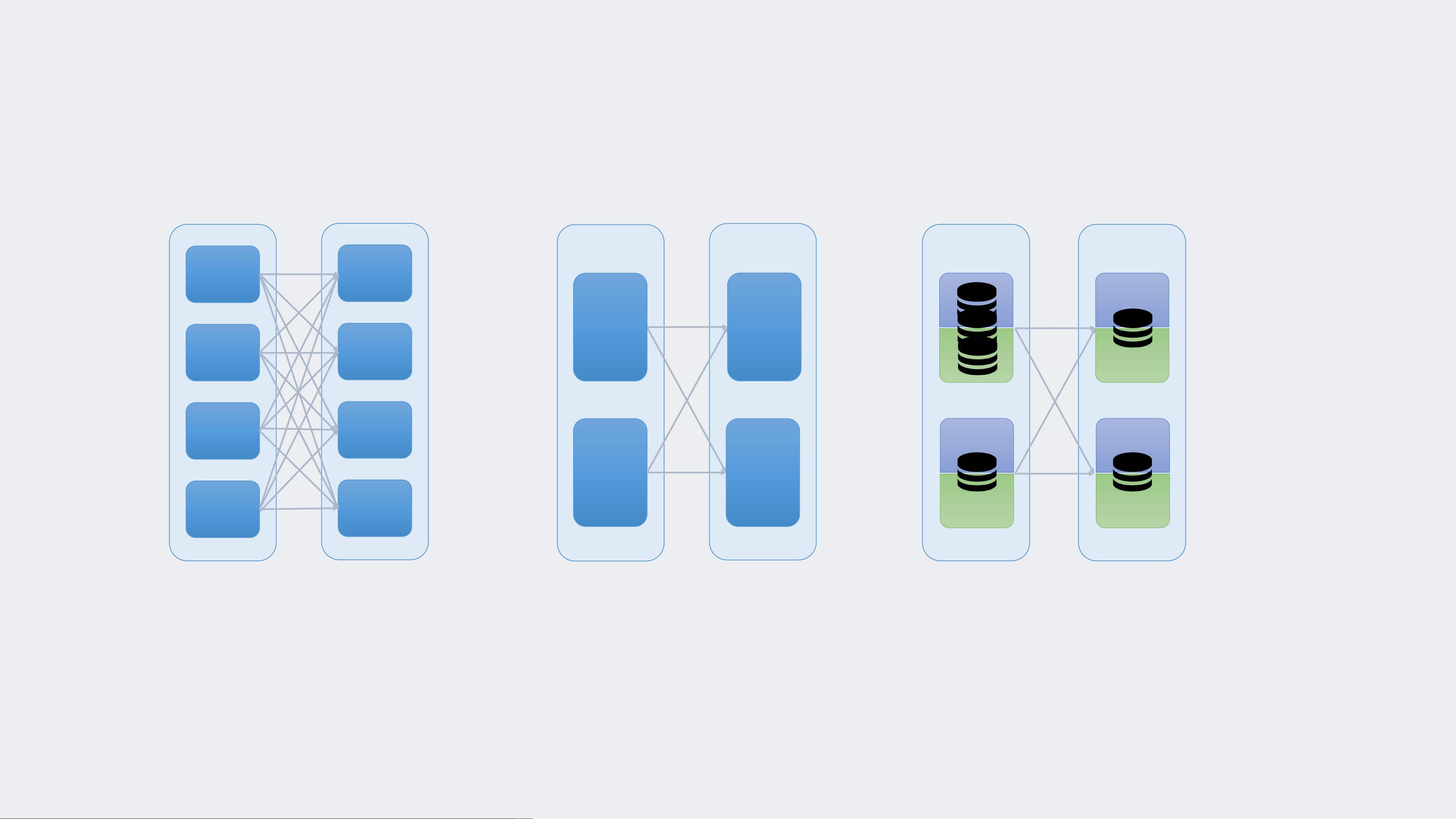
Strawman: tune number of tasks in a job
• Tasks spill intermediate data to disk if data splits exceed memory capacity
• Larger task execution reduces shuffle I/O, but increases spill I/O
剩余31页未读,继续阅读
147 浏览量
2024-07-18 上传
2023-09-09 上传
132 浏览量
203 浏览量
5038 浏览量
2022-11-18 上传
2022-04-05 上传
132 浏览量

过往记忆
- 粉丝: 4401
- 资源: 274
 我的内容管理
展开
我的内容管理
展开







最新资源
- awesome-frontend:精选的很棒的前端资源列表
- 电脑软件m3u8-下载合并配合浏览器嗅探插件使用.rar
- fun-with-WebRTC-part-1:我关于 WebRTC 的文章的第 1 部分的代码存储库
- dCampTokyo2020:2020年东京d.camp研讨会工具
- vqa.pytorch:Pytorch中的可视问题解答
- 基于webpack 5 + lerna 的 可视化学习仓库.zip
- 蓝绿扁平化商务工作总结图表大全PPT模板
- 最近播放器指南针
- ADO_AOK_Demo_DEMO_AOK_Vc_
- grid-gmaps-box:用于 Google Maps API v3 的网格框
- myHtmlCssCourse
- Mockify-crx插件
- fpl_reader:foobar2000 .fpl播放列表阅读器
- 红色扁平化工作计划图表大全PPT模板
- 行进
- Day-24:第 24 天 @ironyard
