改进TACOTRON模型:端到端语音合成与WaveRNN创新
需积分: 0 107 浏览量
更新于2024-08-04
收藏 750KB DOCX 举报
"本文介绍了TACOTRON端到端语音合成模型以及其在语音合成领域的应用和改进。TACOTRON是一种基于深度学习的文本到语音系统,能够减少特征工程的需求,便于对各种属性进行调节。文章指出,TACOTRON模型的声码器使用Griffin-Lim算法,虽然简化了流程,但可能导致合成语音的保真度较低。为解决这个问题,文中提出了使用WaveRNN网络模型来优化声码器,以实现更高质量、更低计算资源消耗的实时语音合成。WaveRNN通过降低网络深度、权重稀疏化和子采样等策略,提高了效率和音质。"
在语音合成领域,TACOTRON模型因其端到端的学习特性而备受关注。它能够直接从文本输入生成语音输出,省去了传统TTS系统中的多个中间步骤,如分词、词性标注等。这种集成的系统减少了对特征工程的依赖,使得模型能更灵活地处理不同语言和说话风格。然而,TACOTRON的一个局限在于它的声码器部分,它使用Griffin-Lim算法来从幅度谱重建相位信息,这可能导致合成的语音存在人工痕迹,且音质不够理想。
Griffin-Lim算法的工作原理是通过迭代过程,尝试找到一个信号的相位,使得该信号的傅里叶变换幅度与原始信号的傅里叶变换幅度最接近。虽然这种方法相对简单,但在追求高保真度的语音合成中,它的效果可能不尽如人意。
为了解决这个问题,研究者引入了WaveRNN模型来提升TACOTRON的性能。WaveRNN是一种针对音频生成优化的循环神经网络,它在保持高质量合成的同时,降低了计算资源的消耗。通过减少网络的深度、实施权重稀疏化以及使用子采样技术,WaveRNN能够更快地生成样本,这对于实时语音合成尤其关键。
TACOTRON和WaveRNN的结合展示了深度学习在语音合成领域的强大潜力,它不仅提高了语音合成的自然度,还解决了计算效率问题,使得实时、高质量的语音合成成为可能。随着技术的不断进步,未来的语音合成系统有望实现更高效、更逼真的语音生成,为语音交互、语音合成应用等领域带来革新。
基于 TACOTRON 端到端语音合成模型的改进方案
一:背景
语音合成就是将任意文本转换成语音的技术,即 TTS。个典型的语音合成系
统的前端部分主要是对输入文本进行分析并提取语音建模需要的信息,具体包括
分词、词性标注、多音字消歧、字音转换、韵律结构与参数的预测等等。后端的
部分读入前端文本分析结果,并结合文本信息对输出的语音进行建模。在合成过
程中,后端会利用输入的文本信息和训练好的声学模型,生成语音信号。根据所
采用的方法和框架不同,现阶段的语音生成器主要分为波形拼接、参数生成和基
于波形的端到端统计合成这三种形式。现阶段语音合成发展的主要目标是进一步
提高合成语音的清晰度与自然度、降低技术的复杂度等方面。
TACOTRON 是一个直接从文本合成语音的神经网络架构,它将各模块放入
一个黑箱,我们无需花费大量时间了解 TTS 中的各模块或者专业领域知识,可
直接通过深度学习训练出一个 TTS 模型。TACOTRON 作为集成的端到端 TTS
系统具有许多优点:它可以减少繁重的特征工程需要,更容易对各种属性(如说
话者或语言)或情绪等高级功能进行丰富的调节,对新数据的适应也更容易。
TACOTRON 模型声码器部分使用 Griffin-Lim 算法,会产生特有的人工痕迹并
且合成的语音保真度较低。
Griffin-Lim 算法是在仅已知幅度谱、未知相位谱的条件下重建语音的算法。
Griffin-Lim 算法将 Seq2Seq 的输出转化成被合成为波形的目标表达,使得估计得
到的信号傅里叶变换的幅度值与原始信号傅里叶变换的幅度值的平方误差达到
最小。通过迭代重构信号的相位信息和已知的幅度信息,得到语音信号的估算值。
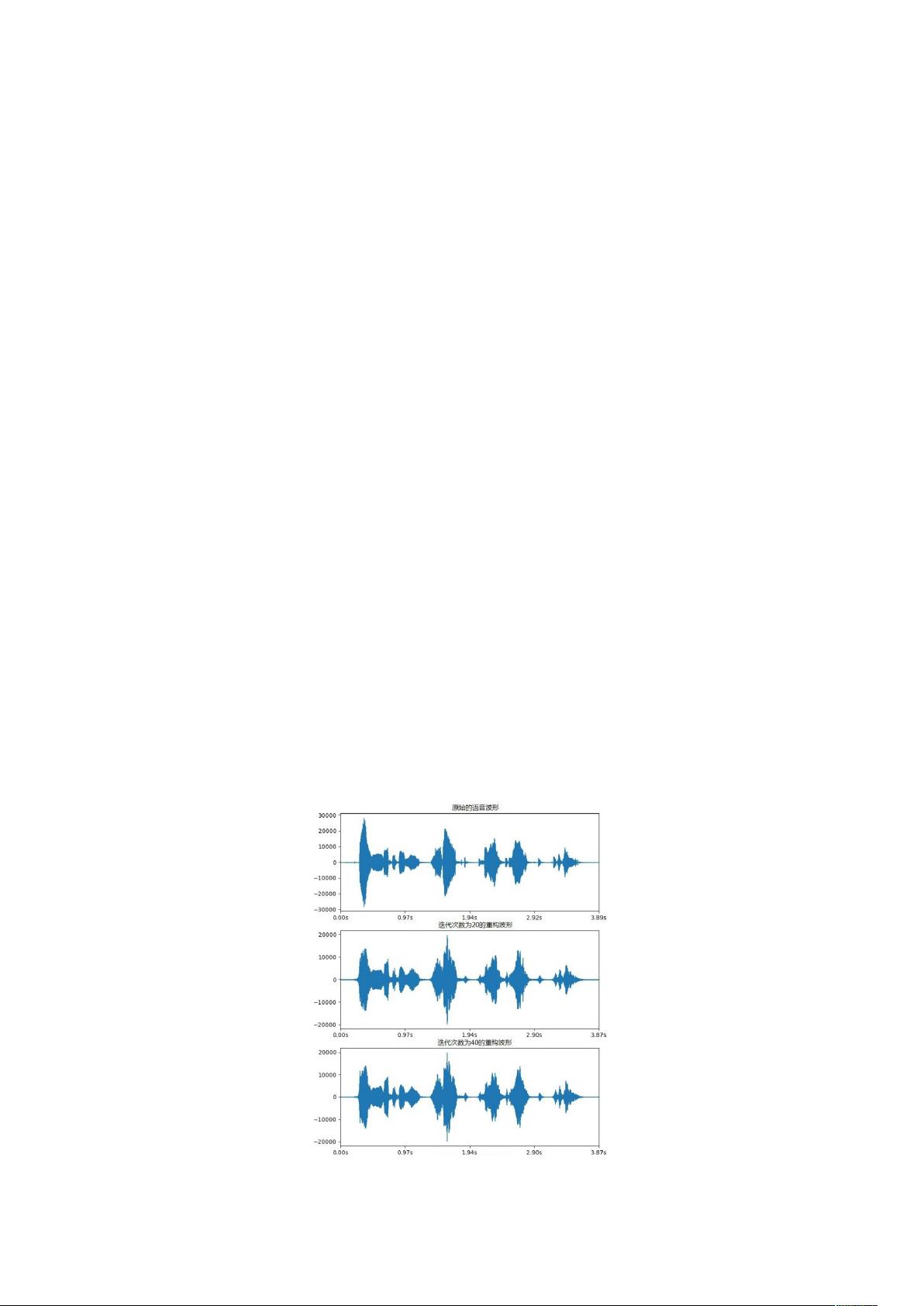
图 1 原始波形与重构波形对比
下载后可阅读完整内容,剩余3页未读,立即下载
2022-06-11 上传
2023-02-16 上传
2024-01-03 上传
2024-01-03 上传
2023-03-31 上传
2023-04-04 上传
2023-06-11 上传
2023-02-22 上传
2023-06-06 上传

挽挽深铃
- 粉丝: 14
- 资源: 274
 我的内容管理
展开
我的内容管理
展开







最新资源
- 解决Eclipse配置与导入Java工程常见问题
- 真空发生器:工作原理与抽吸性能分析
- 爱立信RBS6201开站流程详解
- 电脑开机声音解析:故障诊断指南
- JAVA实现贪吃蛇游戏
- 模糊神经网络实现与自学习能力探索
- PID型模糊神经网络控制器设计与学习算法
- 模糊神经网络在自适应PID控制器中的应用
- C++实现的学生成绩管理系统设计
- 802.1D STP 实现与优化:二层交换机中的生成树协议
- 解决Windows无法完成SD卡格式化的九种方法
- 软件测试方法:Beta与Alpha测试详解
- 软件测试周期详解:从需求分析到维护测试
- CMMI模型详解:软件企业能力提升的关键
- 移动Web开发框架选择:jQueryMobile、jQTouch、SenchaTouch对比
- Java程序设计试题与复习指南
