Elasticsearch异构数据迁移与实时同步实战指南
需积分: 15 57 浏览量
更新于2024-08-05
收藏 1.29MB DOCX 举报
本文档深入探讨了ElasticSearch(ES)的数据迁移与容灾实践,ES作为一款基于Lucene的分布式搜索引擎,因其高效和广泛应用,特别是在搜索、日志管理(APM)、IoT等领域而备受关注。文章首先聚焦于异构数据与ES之间的同步问题。
在实际应用中,异构数据源与ES的同步涉及到多种数据库和数据结构,如MySQL、PostgreSQL、MongoDB等关系型数据库,以及Kafka、RabbitMQ这样的消息队列系统。将这些数据迁移到ES的主要目的是为了提高搜索性能,例如在电商场景中,商品信息存储在MySQL主库,为了快速响应搜索请求,需要将数据实时同步至ES。同步方式可以分为离线同步和实时同步:
1. 离线同步:这种方式通常用于全量数据导入,如一次性或批量导入,通过Logstash组件结合JDBC驱动从MySQL中读取数据,并通过API批量写入ES。然而,这种方法仅适用于数据量相对固定且无频繁删除操作的情况,实时性较差。
2. 实时同步:为了实现数据的即时更新,通常会利用MySQL的Binlog或开源工具如canal/Mypipe,这些工具可以实时捕获数据库操作日志并解析,然后写入ES。为了确保数据的可靠性和高可用性,有时会借助消息队列(如Kafka),将解析后的数据持久化后推送至ES,这样可以提供较高的同步速度和实时性。
针对MongoDB文档数据库,同样可以使用Logstash进行数据迁移,将MongoDB的文档结构映射到ES中,确保数据的完整性和一致性。
此外,文档还提到了将ES数据归档到对象存储(如腾讯云COS、阿里云OSS或Amazon S3)以降低存储成本,这是一种常见的数据备份和归档策略,可以实现长期的数据保护和成本优化。
本文档详细介绍了如何在实际项目中有效地迁移和同步异构数据到Elasticsearch,同时强调了实时性和数据可靠性的关键要素,这对于在高并发、大数据量的环境中维护ES集群的稳定运行至关重要。
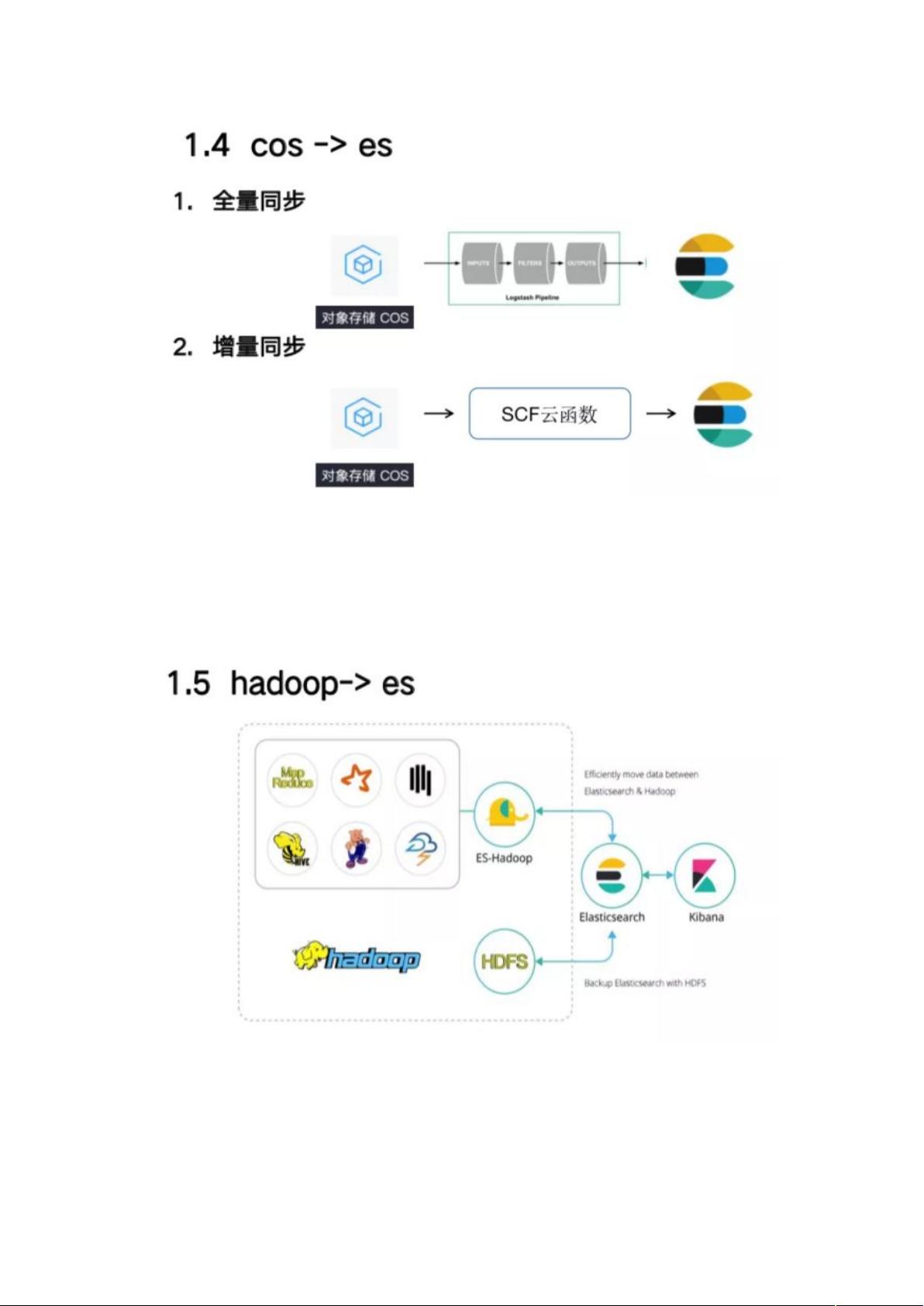
第四种是对象存储,有一些用户需要把对象存储中的数据同步到 ES 中,对象存储本
身有 bucket 存储桶,里面可以存放各种内容,包括普通文件和音视频文件等,如果
要进行全量同步的话,可以采用 Logstash。如果增量同步,目前腾讯云上也是采用
SCF 云函数,可以订阅到对象存储里某一个 bucket,如果这个 bucket 上传文件的话,
就可以触发到云函数的执行,云函数内部逻辑会把文件读出来做一些解析然后再写入
到 ES 中。
第五种是 Hadoop 生态系统和 ES 数据的导入导出,这种场景 ES 官方提供了 ES-
Hadoop 组件,可以实现 Hadoop 各种生态内的组件和 ES 的交互,可以在 hive 中
建一个外部表,指向的是 ES 本身的索引,就可以使用 hivesql 查询其中的数据,也
可以通过这个组件到把数据导出到 HDFS 中。还有一种场景是 ES 本身的数据磁盘上
的索引文件可以通过快照的方式 可以归档中 HDFS 中,因为一些老的数据做归档存储
剩余11页未读,继续阅读
2021-10-11 上传
147 浏览量
449 浏览量
260 浏览量
2024-07-08 上传
197 浏览量
102 浏览量
2021-10-14 上传
2021-10-14 上传









