斯坦福CS229机器学习笔记:从线性回归到SVM
"这是一份详细的斯坦福大学机器学习课程笔记,涵盖了从基础的线性回归到复杂的增强学习等多个主题,由个人学习整理而成,基于Andrew Ng教授的课程内容,并结合了其他论文和资料。笔记内容包括:线性回归、逻辑回归、一般回归、判别模型、生成模型、朴素贝叶斯、支持向量机(SVM)、规则化与模型选择、K-means聚类、混合高斯模型、EM算法、在线学习、主成分分析(PCA)、独立成分分析(ICA)、线性判别分析(LDA)、因子分析、增强学习、典型关联分析以及偏最小二乘法回归。笔记中可能存在的错误需要读者自行校对,作者建议遇到问题时查阅原讲义和视频,或寻求专家帮助。"
这篇笔记详细阐述了机器学习领域的多个重要概念和技术。首先,线性回归是基础的预测模型,用于建立输入特征与输出之间的线性关系,以进行连续值的预测。接着,logistic回归扩展了线性回归,适用于二分类问题,通过sigmoid函数将预测值转化为0和1之间的概率。
在回归问题的基础上,笔记讨论了判别模型与生成模型的区别。判别模型直接学习决策边界,如逻辑回归,而生成模型如朴素贝叶斯,不仅学习决策边界,还学习数据的联合分布。
支持向量机(SVM)是一种强大的分类器,分为上下两部分详细讲解。它通过构造最大边距超平面来划分数据,能处理高维数据,并具有泛化能力。
规则化和模型选择是防止过拟合的关键,通过正则化项限制模型复杂度,如L1和L2正则化。K-means聚类是一种无监督学习方法,用于发现数据的自然群组结构。
混合高斯模型和EM(期望最大化)算法在处理混合分布数据时特别有用,EM算法用于参数估计,在不知道隐藏变量的情况下最大化似然性。
在线学习是处理大规模数据流的有效方法,每次迭代只考虑一个样本,适合实时更新模型。主成分分析(PCA)用于降维,保留数据的主要变化;独立成分分析(ICA)旨在找到信号的原始独立源;线性判别分析(LDA)和因子分析分别用于特征选择和结构分析。
增强学习探讨了如何让智能体通过与环境交互来学习最优策略,而典型关联分析则关注于发现变量之间的相互依赖关系。最后,偏最小二乘法回归是多元回归的一种变体,用于处理多重共线性问题。
这份笔记是深入理解和应用机器学习技术的重要参考资料,对于希望系统学习机器学习理论和实践的学生和专业人士来说,具有很高的价值。
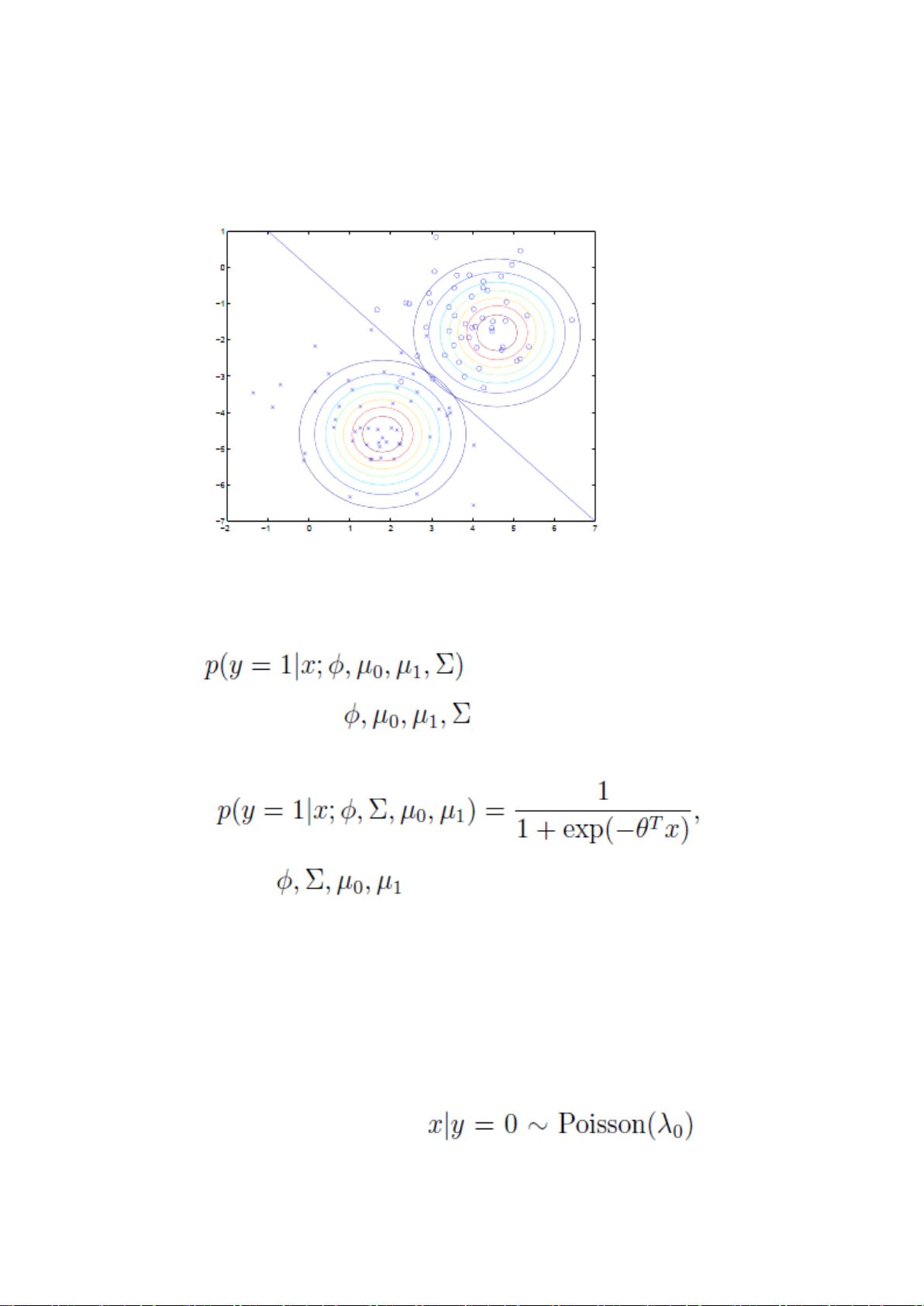
是 y=1 的样本中特征均值。
是样本特征方差均值。
如前面所述,在图上表示为:
直线两边的 y 值不同,但协方差矩阵相同,因此形状相同。不同,因此位置不同。
3) 高斯判别分析(GDA)与 logistic 回归的关系
将 GDA 用条件概率方式来表述的话,如下:
y 是 x 的函数,其中 都是参数。
进一步推导出
这里的是 的函数。
这个形式就是 logistic 回归的形式。
也就是说如果 p(x|y)符合多元高斯分布,那么 p(y|x)符合 logistic 回归模型。反之,
不成立。为什么反过来不成立呢?因为 GDA 有着更强的假设条件和约束。
如果认定训练数据满足多元高斯分布,那么 GDA 能够在训练集上是最好的模型。然
而,我们往往事先不知道训练数据满足什么样的分布,不能做很强的假设。Logistic
回归的条件假设要弱于 GDA,因此更多的时候采用 logistic 回归的方法。
例如,训练数据满足泊松分布,
13



剩余136页未读,继续阅读
相关推荐




LexAlex
- 粉丝: 3
- 资源: 21
 我的内容管理
展开
我的内容管理
展开







最新资源
- 有向图关键路径问题 三种算法求解
- 与短消息开发相关的GSM AT指令
- C#可定制的数据库备份和恢复程序
- 30分钟搞定BASH脚本编程
- ALTERA_EPM3032A DATASHEET
- ASP.NET 2.0创建母版页引来的麻烦-js无用
- AO+c#(.NET)开发
- ARM7TDMI-S(Rev 4)技术参考手册
- 利用js+div来控制打印
- 【IBM/Oracle工程实例/实践 Oracle 10gRs(10.2.0.1) 数据库在AIX5L 上的安装】
- Linux 初学者入门优秀教程
- 最好的51单片机教程,信不信由你
- 考研英语翻译关键词组
- 基于XML的Web文本挖掘模型的研究与设计
- C语言 课程设计电子通讯录
- 北京大学数字图像处理课件
