实战揭秘:Spark运行机制与RDD深度解析
需积分: 6 85 浏览量
更新于2024-08-04
收藏 435KB PDF 举报
Spark实战解析深入探讨了Spark运行原理和RDD(Resilient Distributed Dataset)的机制。Spark是一个分布式计算框架,它利用内存作为其核心优势,设计用于迭代式计算,能够在处理大数据时提供显著的速度提升。相比于Hadoop,基于内存的Spark可以达到100倍的速度优化,而基于磁盘的则有10倍的优势。
首先,Spark的运行原理涉及以下几个关键点:
1. **分布式架构**:Spark在多台机器上并行执行任务,每个机器处理一部分数据,这使得它可以同时处理大量数据。
2. **内存优化**:数据优先加载到内存中,以实现更快的访问速度。如果内存不足,才会将数据转移到磁盘,但仍保留数据本地性,以提高效率。
3. **Driver与Worker**:Driver是用户编写的本地程序,负责提交任务到Spark集群。Scala被推荐用于编写Spark程序,尽管Java也可用,但由于人才库和易用性的考虑,Scala更为常用。
4. **Spark组件**:Spark能处理多种数据源如HDFS、HBase、Hive等,并支持多样化的数据输出目的地,如HDFS、S3等,以及直接输出到Driver端。
接着,我们深入了解RDD的核心概念:
1. **RDD的本质**:Spark的所有操作都是基于RDD,它是一种弹性分布式数据集,能够分布在多台机器的多个分区中。一个大文件会被切分成小块(分区),每个分区独立存储在集群的不同节点上。
2. **弹性特性**:
- **内存和磁盘切换**:RDD自动在内存和磁盘之间进行数据移动,以适应内存需求的变化。
- **容错性**:通过Lineage(血统关系)机制,当某个任务失败时,仅需重新计算依赖于失败任务的后续步骤,而非整个任务链,大大加快了错误恢复速度。
- **任务重试**:对于失败的任务,Spark有默认的重试策略,通常为4次,确保任务的可靠性。
理解Spark的运行原理和RDD的内在结构是掌握这个强大工具的关键。通过利用内存、处理大文件的分布式方式以及高效的容错机制,Spark在大数据处理场景中表现出色。无论是使用Java还是Scala,开发者都能在Spark平台上实现高效的迭代式计算。
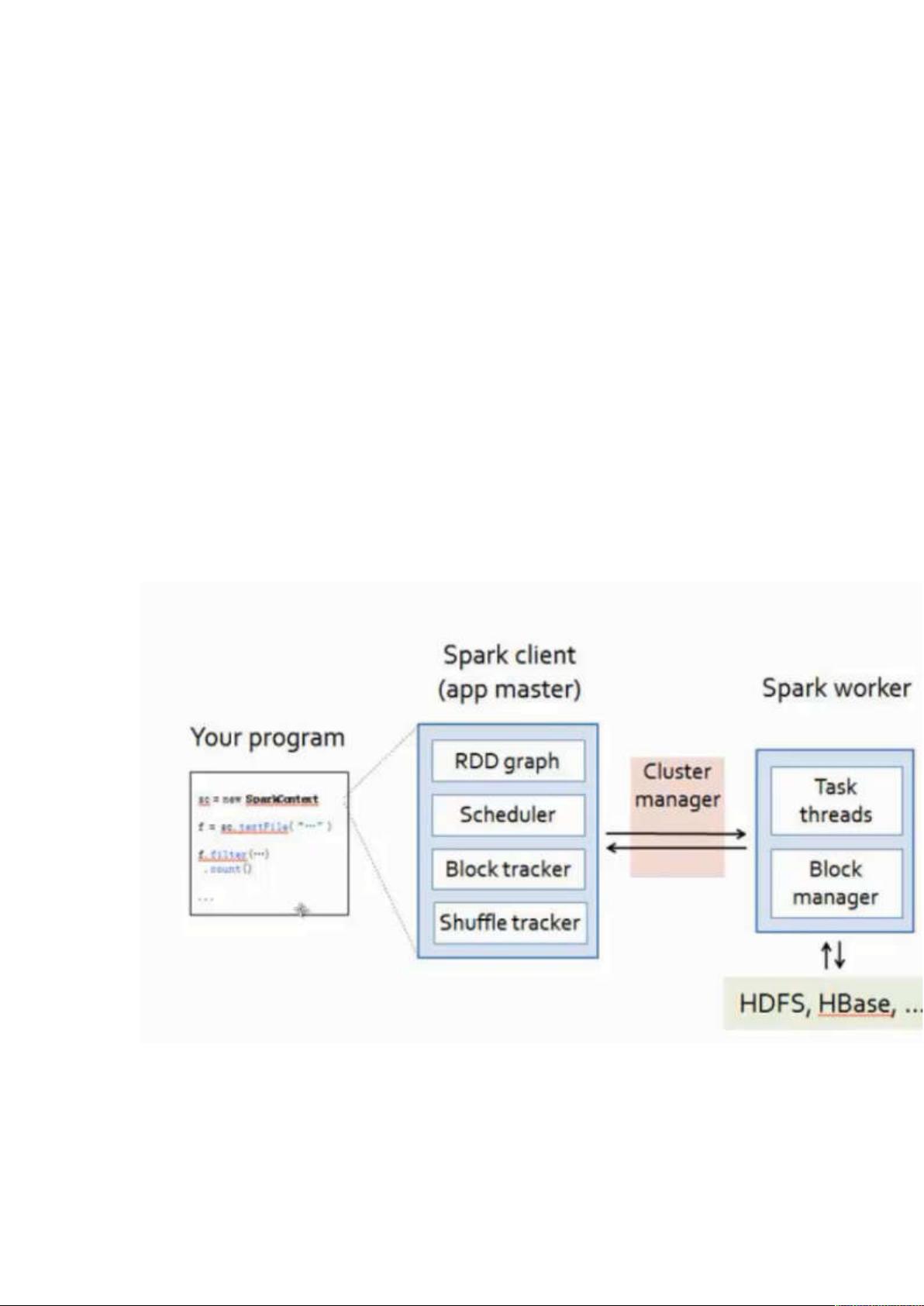
一:spark 运行原理
Spark 是一个分布式(很多机器,每个机器负责一部部分数据),基于内存(内存不够可
以放在磁盘中),特别适合于迭代计算的计算框架。
基于内存(在一些情况下也会基于磁盘),优先考虑放入内存中,有更好的数据本地性。
如果内存中放不完的话,会考虑将数据 或者部分数据放入磁盘中。
擅长迭代式计算是 spark 的真正精髓。基于磁盘的迭代计算比 hadoop 快 10x 倍,基于
内存的迭代计算比 hadoop 快 100x 倍。
Driver 端, 就是写好的本地程序提交到特定的机器上。
Spark 开发语言说明
国内开发程序 spark 程序 有些使用 java 开发,
1. 人才问题 java 开发人员很多(scala 开发人员较少)
2. 整合更加容易
3. 维护更加容易
4. 但是要更好的掌握 spark 还是需要用 scala 写 spark,因为 java 写起来太繁琐了而且有些
功能实现起来很困难。
Spark 组件
处理数据来源: hdfs 、hbase、hive 、db。
Hivee 包括数据仓库和计算引擎,sparksql 只能取代 hive 的计算引擎。
处理数据输出: hdfs 、hbase、hive 、db、s3(云)。还可以直接输出给客户端(dirver 端)。
下载后可阅读完整内容,剩余7页未读,立即下载
225 浏览量
286 浏览量
216 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_47256930
- 粉丝: 13
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- donate
- ASP.NET交通信息网上查询系统的设计与实现(源代码+论文+开题报告).zip
- cs61a_20fall:我的CS 61A 2020年秋季代码
- 高斯白噪声matlab代码-MatlabMusic:Matlab音乐
- java同城搬家平台的设计毕业设计程序
- Extensions-2.5:WaveEngine中集成了外部SDK
- Thiamine
- 智能轮播:轮播自定义元素
- 捕获:图像下载应用程序
- java高校家教管理系统毕业设计程序
- bot1
- wtbtkyek.zip_信号 毕业_毕业设计信号
- nexus-3.30.1.01.7z
- djmax-dongletools:DJMax Trilogy保存数据管理器
- Umberto
- nkjxbaim.zip_single
