大数据性能优化与Hive SQL调优实战
需积分: 9 28 浏览量
更新于2024-07-15
收藏 3.45MB PPTX 举报
"大数据性能优化.pptx 是一份关于大数据处理和优化的演讲稿,涵盖了分布式集群的概念,Hive的产生背景,优化目标,任务执行流程,Hive MapReduce调优以及SQL优化等内容。这份资料适合初学者理解,通过实例帮助读者掌握优化技术。"
在大数据领域,性能优化是确保高效数据处理的关键。以下将详细阐述文件中的主要知识点:
1. **分布式集群**:分布式集群是指将同一业务的不同部分部署在多台机器上,它们之间需要协同工作。与集群相比,分布式系统更强调任务的拆分和协作,例如在饭店的例子中,厨师(计算节点)和配菜师(数据处理节点)分别负责不同的工作。
2. **Hadoop框架**:Hadoop是一个开源的分布式计算框架,包括HDFS(Hadoop Distributed File System),用于可靠存储大数据;HBase,作为实时的分布式数据库;MapReduce,用于分布式计算;以及像Sqoop和Flume这样的数据迁移和日志收集工具。
3. **Hive的产生背景**:随着大数据时代的到来,传统的关系型数据库难以应对大规模数据的存储和分析。Hadoop提供了分布式存储(HDFS)和计算(MapReduce)解决方案,但MapReduce编程模型复杂。因此,Hive应运而生,它提供了一种基于SQL的接口,简化了对HDFS上数据的分析操作。
4. **Hive优化目标**:Hive优化主要关注提升查询速度和降低资源消耗,包括Hive MapReduce调优和SQL优化。
5. **Hive MapReduce调优**:优化MapReduce涉及到减少数据shuffle,优化分区策略,选择合适的输入格式,合理设置MapReduce的参数(如mapred.min.split.size, mapred.reduce.tasks等),以及重写查询逻辑以减少不必要的JOIN和GROUP BY操作。
6. **SQL优化**:SQL优化通常涉及查询重构,避免全表扫描,使用索引,减少子查询,以及正确使用JOIN类型。理解查询执行计划,识别性能瓶颈,也是优化的重要步骤。
7. **HDFS的关键特性**:HDFS设计为高容错性和高吞吐量,但在HDFS上进行数据统计分析操作并不直接,需要通过Hive这样的工具,或者直接编写MapReduce程序。
这份资料旨在帮助读者理解大数据环境下的性能优化策略,特别是对于使用Hive进行数据分析的场景。通过学习这些内容,开发者和数据工程师可以更有效地管理和利用大数据资源,提高系统的整体性能。
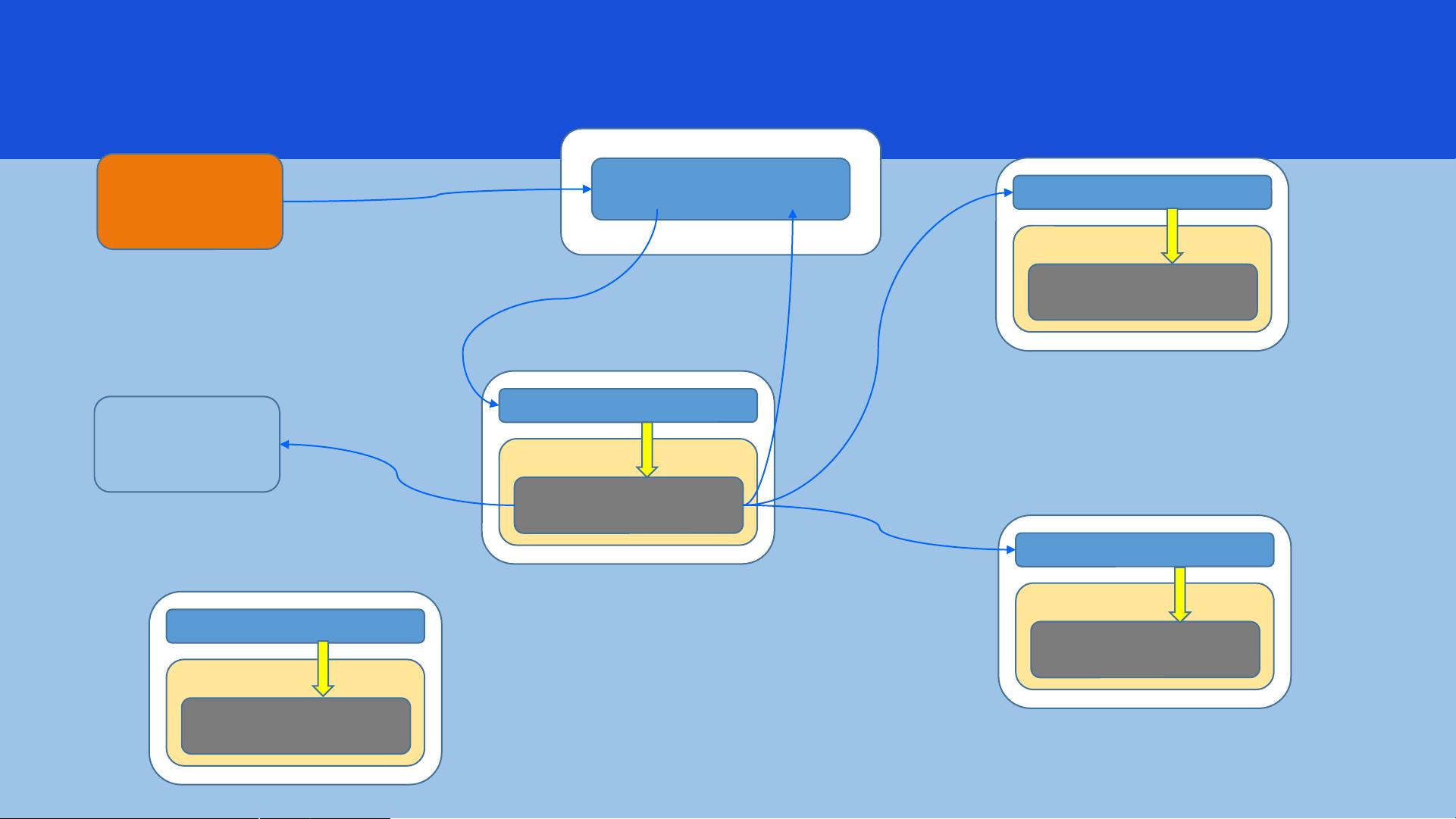
任务执行流程
.'/(
#
/0
#(
'(1
1/0
./(/
'(/#(
'(1
1/0
./(/
,#
'2(12
1/0
./(/
,#
'1(11
1/0
./(/
3($,#
4
1 个节点
提交作业
找到一个 1
来启动
启动 AM
2 得到分片信息
5 申请资源
6 得到资源后,
通过各节点 1
来启动任务
剩余55页未读,继续阅读
2024-05-21 上传
2021-10-14 上传
2021-10-14 上传
2022-06-21 上传
2022-06-21 上传
2021-09-21 上传

chimchim66
- 粉丝: 9837
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- MCP C#试用试题
- nutch初学入门 非常好的入门教程
- c#面试题 网络转载 不错 经典
- C#设计模式大全 好书
- Struts+Spring+Hibernate整合教程.pdf
- BP神经网络原理及仿真实例
- 使用简介POWERPLAY
- Oracle 9i10g编程艺术
- scm手把手开发文档
- Cognos Impromptu
- LoadRunner安装手册.pdf
- cognos 部署 文档
- 用C语言进行单片机程序设计与应用
- Direct3D.ShaderX.-.Vertex.and.Pixel.Shader.Tips.and.Tricks.pdf
- 《uVision2入门教程》.pdf
- spring1.2申明式事务.txt
