HDFS详解:原理、应用与架构探讨
需积分: 7 143 浏览量
更新于2024-07-19
收藏 1.17MB PPTX 举报
HDFS (Hadoop Distributed File System) 是一个专为大规模分布式存储而设计的开源文件系统,它源于Google的GFS (Google File System) 技术,首次发布于2003年10月。HDFS的目标是在低成本的硬件上实现高容错性和可扩展性,以支持大规模数据处理,特别适合处理GB、TB乃至PB级别的数据,以及数百万级别的文件。
HDFS的核心设计思想是将大文件划分为固定大小的块(Block),通常为128MB到64MB,然后在不同的节点上创建多个副本以实现容错。这些副本分布在不同的服务器上,当一个副本出现故障时,系统可以自动从其他副本恢复数据,从而确保数据的高可用性。这种设计使得HDFS非常适合处理大量一次性写入且长期不被修改的数据,适合批处理和数据挖掘等场景,但可能不太适合对低延迟、高吞吐率或频繁读写的小文件有严格要求的应用。
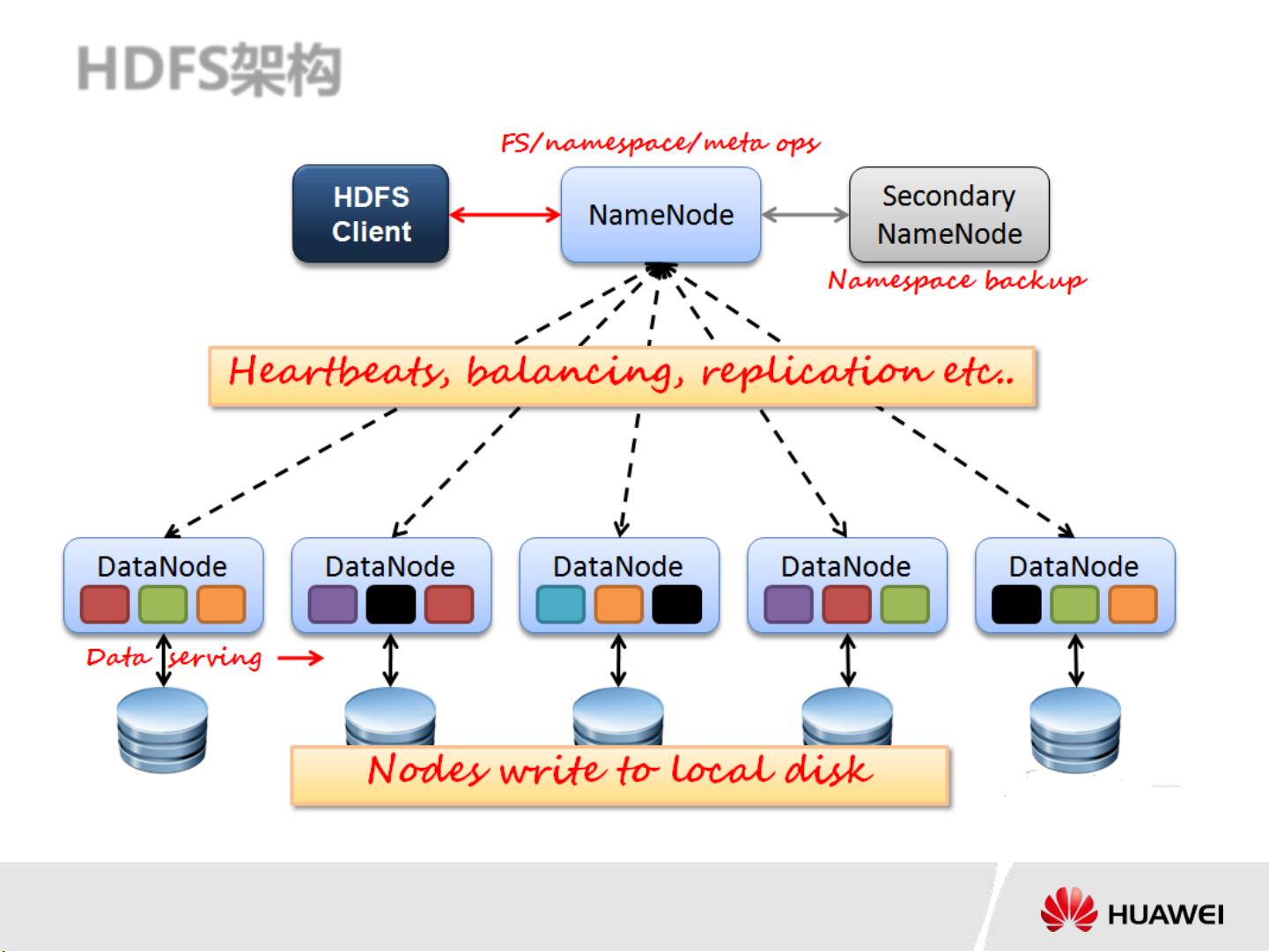
HDFS的架构主要包括两个主要组件:NameNode和DataNodes。NameNode作为整个系统的元数据管理器,负责全局文件系统的命名空间管理、块的分布和复制策略,以及客户端请求的路由。它存储了所有的元数据,如文件的目录信息和块的位置信息。另一方面,DataNodes是实际存储数据的节点,它们接收并存储来自NameNode分配的文件块,并负责处理客户端的读写请求。
HDFS的优点包括:
1. 高容错性:通过在多个节点上保存数据副本,即使单个节点故障,也能保证数据完整性。
2. 数据一致性:支持一次性写入,多次读取,保证了数据的一致性。
3. 扩展性强:易于在大量廉价硬件上部署和扩展。
4. 性能良好:适合大规模数据处理,对用户而言提供性能不错的文件存取服务。
然而,HDFS也存在一些限制:
1. 低延迟访问:由于其设计目标和分块策略,HDFS在处理小文件或实时读写请求时可能会表现出较低的性能。
2. 小文件处理:由于每个块的大小固定,对于小文件来说,可能会浪费存储空间,并可能导致寻道时间过长。
3. 同步写入限制:HDFS不支持并发写入和文件的随机修改,这意味着写操作是顺序进行的,这可能会限制某些实时应用的性能。
4. NameNode内存消耗:随着文件数量的增加,NameNode需要处理大量的元数据,可能会占用大量内存,对集群资源有一定的要求。
HDFS的典型应用场景包括云计算平台、大数据分析(如Hadoop生态系统中的MapReduce)、日志管理、数据备份和归档等。理解HDFS的工作原理和架构特性对于有效地利用和优化这类大规模分布式存储系统至关重要。

Copyright © 2016 Huawei Technologies Co., Ltd. All rights reserved. Page 7
HDFS 设计思
想
Server
(10 TB)
Server
(10 TB)
Server
(10 TB)
block1
block2
block3
block4
block1
block1
block2
block2
block3 block3
block4
block4
block1:node1,node2,node
3
block2:node2,node3,node
4
block3:node4,mode5,node6
block4:node5,node6.node7
…….
Server
(10 TB)
128MB
……
file3
50 GB
block1 block2
block3
128MB
128MB
128MB
剩余38页未读,继续阅读
2021-03-02 上传
2022-06-21 上传
2023-07-25 上传
2023-06-10 上传
2023-05-19 上传
2023-05-18 上传
2023-06-02 上传
2023-05-23 上传

witdance
- 粉丝: 3
- 资源: 20
 我的内容管理
展开
我的内容管理
展开







最新资源
- zlib-1.2.12压缩包解析与技术要点
- 微信小程序滑动选项卡源码模版发布
- Unity虚拟人物唇同步插件Oculus Lipsync介绍
- Nginx 1.18.0版本WinSW自动安装与管理指南
- Java Swing和JDBC实现的ATM系统源码解析
- 掌握Spark Streaming与Maven集成的分布式大数据处理
- 深入学习推荐系统:教程、案例与项目实践
- Web开发者必备的取色工具软件介绍
- C语言实现李春葆数据结构实验程序
- 超市管理系统开发:asp+SQL Server 2005实战
- Redis伪集群搭建教程与实践
- 掌握网络活动细节:Wireshark v3.6.3网络嗅探工具详解
- 全面掌握美赛:建模、分析与编程实现教程
- Java图书馆系统完整项目源码及SQL文件解析
- PCtoLCD2002软件:高效图片和字符取模转换
- Java开发的体育赛事在线购票系统源码分析
