挖掘关联知识:从海量数据中发现商业价值
版权申诉
162 浏览量
更新于2024-07-03
收藏 425KB PDF 举报
"第五章 关联挖掘.pdf"
关联挖掘是数据挖掘领域的重要技术,它主要目的是从海量数据中发现项集之间的有趣关系,这些关系通常表现为“如果…则…”的形式,称为关联规则。随着信息技术的发展,数据库中存储的数据量日益增大,关联挖掘成为了一种有效的工具,用于提取潜在的市场趋势和消费者行为模式。
关联规则挖掘的核心任务是寻找频繁项集和生成关联规则。频繁项集是指在数据集中出现次数超过预设阈值的项集。关联规则则是基于频繁项集生成的,描述了项集间的概率关系。例如,“如果顾客购买了牛奶,那么他们也可能会购买面包”。这种规则可以帮助商家优化产品布局,实施精准营销,或者预测消费者的购买行为。
市场购物分析是关联挖掘的典型应用场景。通过对购物篮数据的分析,商家可以识别出哪些商品经常一起被购买,进而调整商品陈列,实施捆绑销售策略,或者设计促销活动。例如,如果发现顾客购买牛奶的同时,购买面包的概率很高,商家可能会选择将牛奶和面包放在相近的位置,以增加两种商品的销售。
关联挖掘的过程包括数据预处理、频繁项集挖掘和规则生成三个步骤。数据预处理涉及数据清洗、数据转换等,确保数据的质量和可用性。频繁项集挖掘阶段,通常采用Apriori、FP-Growth等算法,这些算法能够在满足最小支持度条件下找出所有频繁项集。最后,规则生成阶段根据频繁项集生成满足最小置信度的关联规则。
Apriori算法是一种经典的关联挖掘算法,它利用下述原理:如果一个项集是频繁的,那么它的任何子集也必须是频繁的。这个特性允许算法在早期阶段排除不可能成为频繁项集的候选集,从而减少计算量。FP-Growth算法则是通过构建FP树(频繁项集树)来高效地找到频繁项集,避免了重复扫描数据集。
关联规则的评价通常依赖于两个关键指标:支持度和支持度。支持度衡量项集在所有交易中出现的比例,而置信度表示在已知项集A出现的情况下,项集B出现的概率。高支持度和高置信度的规则被认为是有意义的。
本章将深入探讨关联挖掘的理论基础,包括市场购物分析的经典案例,关联挖掘的基本概念,以及不同的挖掘方法,如Apriori和FP-Growth算法的实现细节。通过学习这些内容,读者将能理解如何从大量数据中发现有价值的关联规则,以及如何应用这些规则进行商业决策和优化。
数据挖掘第五章 关联挖掘
项集
。它是由候选
-
项集
!
中的元素组成。
(
) 为发现频繁
0
项集
,算法利用
⊕
,来产生一个候选
-
项集
!
;
!
中包含
个
-
项集(元素)。接下来就扫描数据库
,以获得候选
-
项集
!
中的各元素(
-
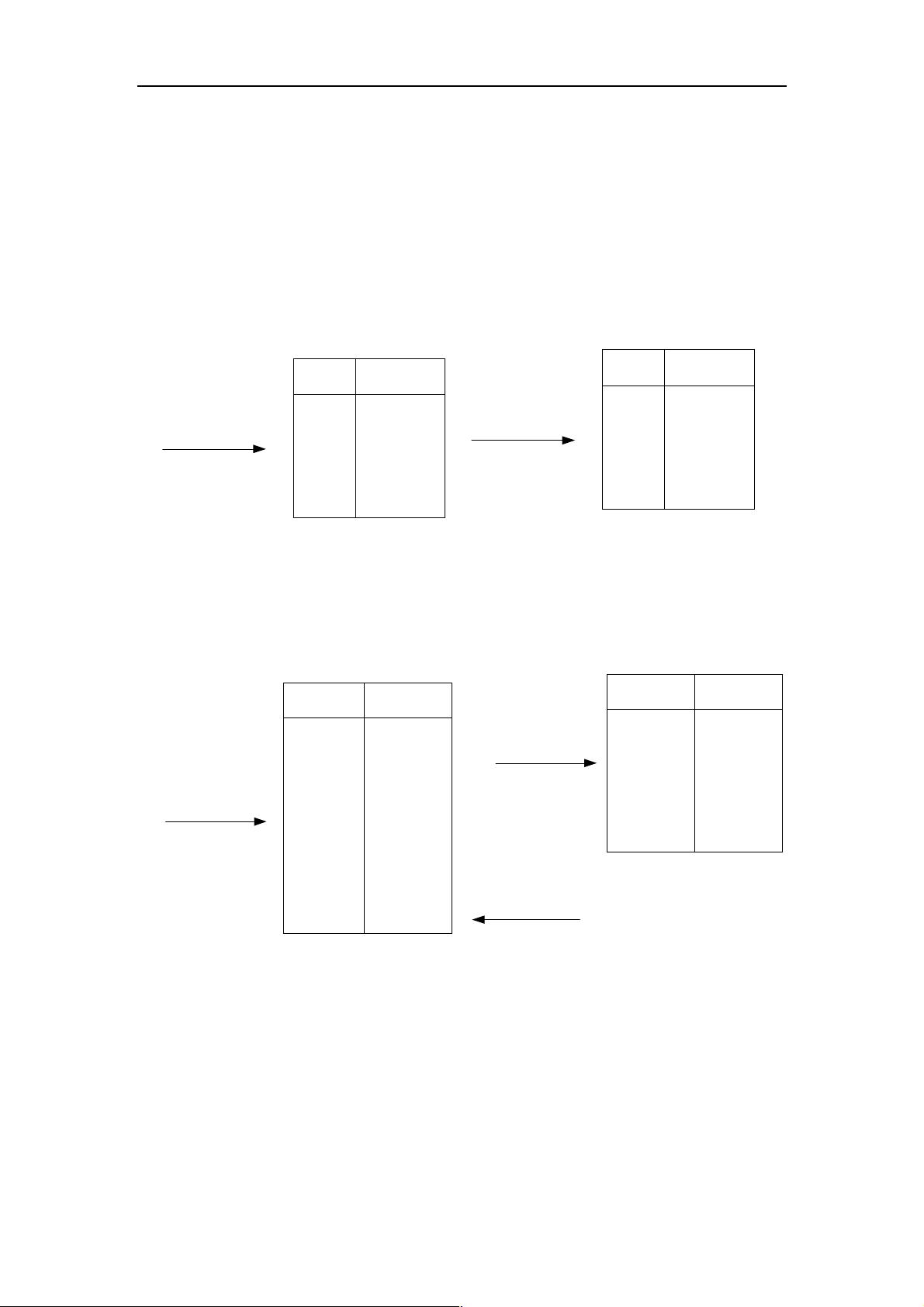
项集)支持频度。如图-
所示。
项集 支持频度
扫描数据库获得各项
集支持频度
项集 支持频度
与最小支持阈值相比
获得频繁项集
图-
搜索候选
-
项集和频繁
-
项集
(
) 由此可以确定频繁
-项集
内容。它是由候选
-项集
!
中支持频度不小
于最小支持频度的各
0
项集。
项集 支持频度
根据频繁
-项集产生
候选
-项集
项集 支持频度
与最小支持阈值相比
获得频繁项集
扫描数据库已确定候
选
2
-项集的支持频度
图-
搜索候选
-项集和频繁
-项集
(
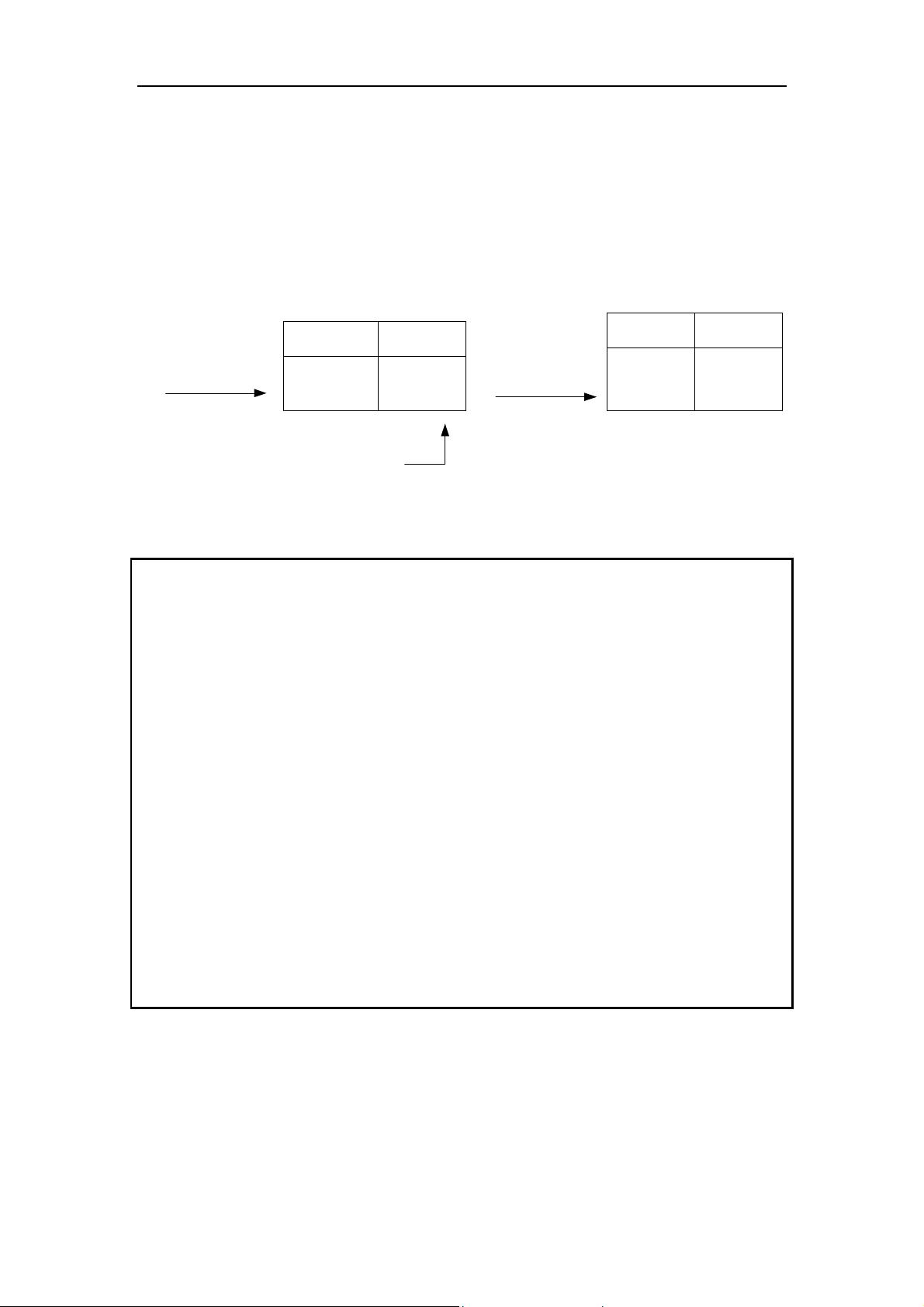
) 所获得的候选
-项集
!
,其过程如表-
所示。首先假设
! ⊕=
,
即为
+
,
+
,
+
,
+
,
+
,
+
,
+
,
+
,
+
,
+
,
+
,
+
,
+
,
+
,
剩余37页未读,继续阅读
点击了解资源详情
223 浏览量
点击了解资源详情
144 浏览量
2021-12-01 上传
2022-06-19 上传
303 浏览量
2022-04-26 上传
435 浏览量

智慧安全方案
- 粉丝: 3843
- 资源: 59万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Clean Flat Icons
- 微信小程序设计-生活圈.zip
- Clean Minimalist GUI Pack 1.1.unitypackage
- 微信小程序设计-图表.zip
- python自学教程-08-烤地瓜方法cook.ev4.rar
- 微信小程序设计-房贷计算器.zip
- python自学教程-09-烤地瓜案例魔法方法str.ev4.rar
- 微信小程序设计-二十四节气小程序.zip
- python自学教程-07-烤地瓜init方法.ev4.rar
- 微信小程序设计-体育新闻赛事数据.zip
- 附加属性,附加属性,附加属性【可联系作者购买】
- Flat Buttons Icons Pack v2.4.unitypackage
- 微信小程序设计-淘票票.zip
- 关于单片机嵌入式实验报告及资源
- HTML+JS+CSS3制作圣诞节电子贺卡
- 微信小程序设计-电梯品牌商城.zip
