NVIDIA CUDA编程指南详解
"NVIDIA CUDA 编程指南 1.1 中文版"
CUDA(Compute Unified Device Architecture)是由 NVIDIA 提出的一种并行计算平台和编程模型,它允许开发人员利用 GPU(图形处理器单元)进行高性能计算。该编程指南是针对 CUDA 1.1 版本的,详细介绍了如何利用 CUDA 技术进行程序设计。
1. **CUDA 概述**
- **GPU 作为并行数据计算设备**:传统的 GPU 主要用于图形渲染,但 CUDA 把 GPU 视为一个能进行大规模并行计算的设备,适合于处理复杂的科学计算和数据分析任务。
- **CUDA 架构**:CUDA 提供了一种新的架构,使得程序员可以编写运行在 GPU 上的代码,从而充分利用 GPU 的并行处理能力。
2. **编程模型**
- **超多线程协处理器**:CUDA GPU 是一个多线程设备,每个 GPU 多处理器可同时执行数千个线程,以实现并行计算。
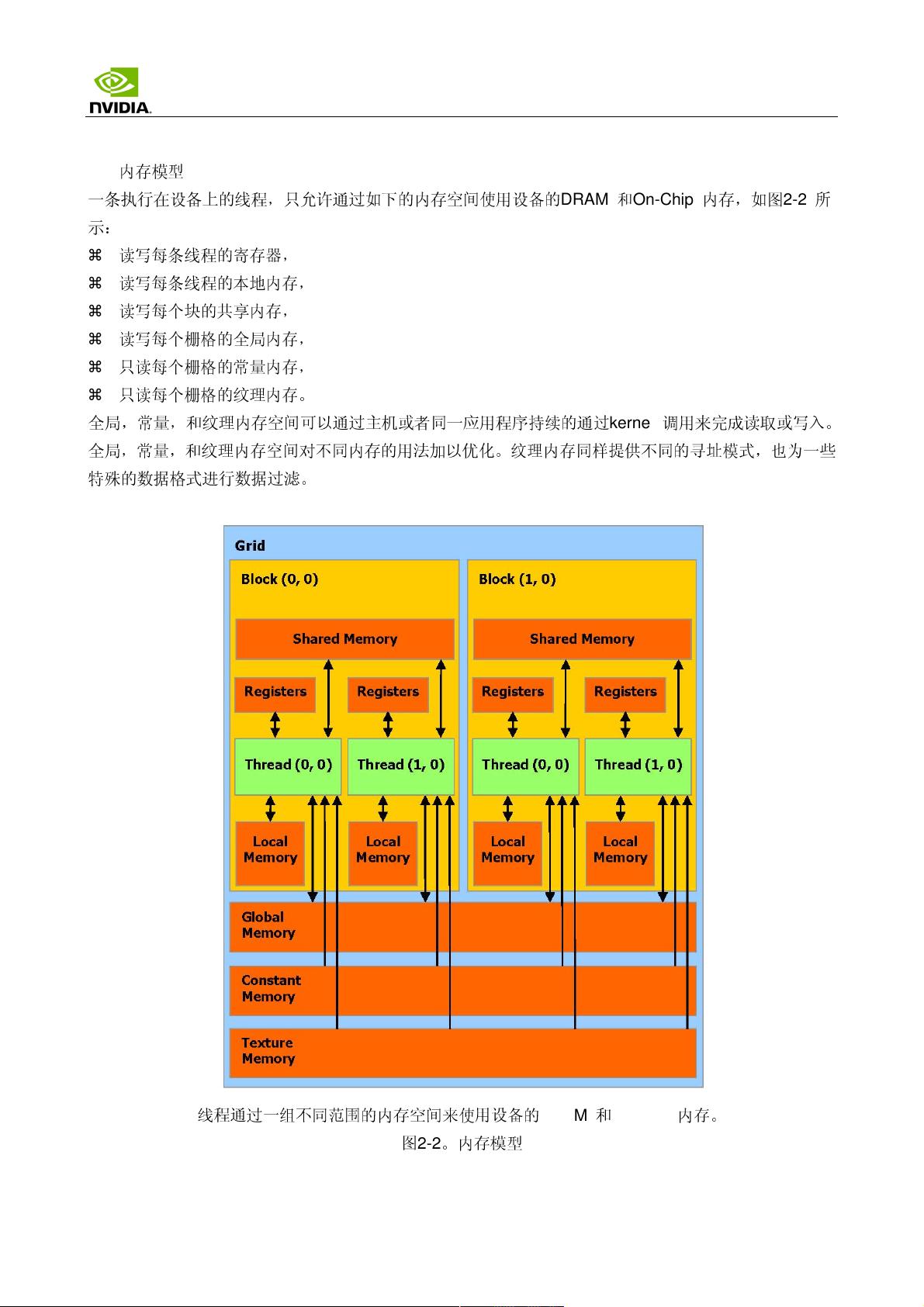
- **线程批处理**:线程被组织成线程块(Thread Blocks)和线程块栅格(Grids),线程块内的线程可以高效地共享数据,而线程块栅格则构成了整个计算任务的逻辑结构。
- **内存模型**:CUDA 提供了不同层次的内存,包括全局内存、共享内存、常量内存和纹理内存,以满足不同类型的访问需求和性能优化。
3. **硬件实现**
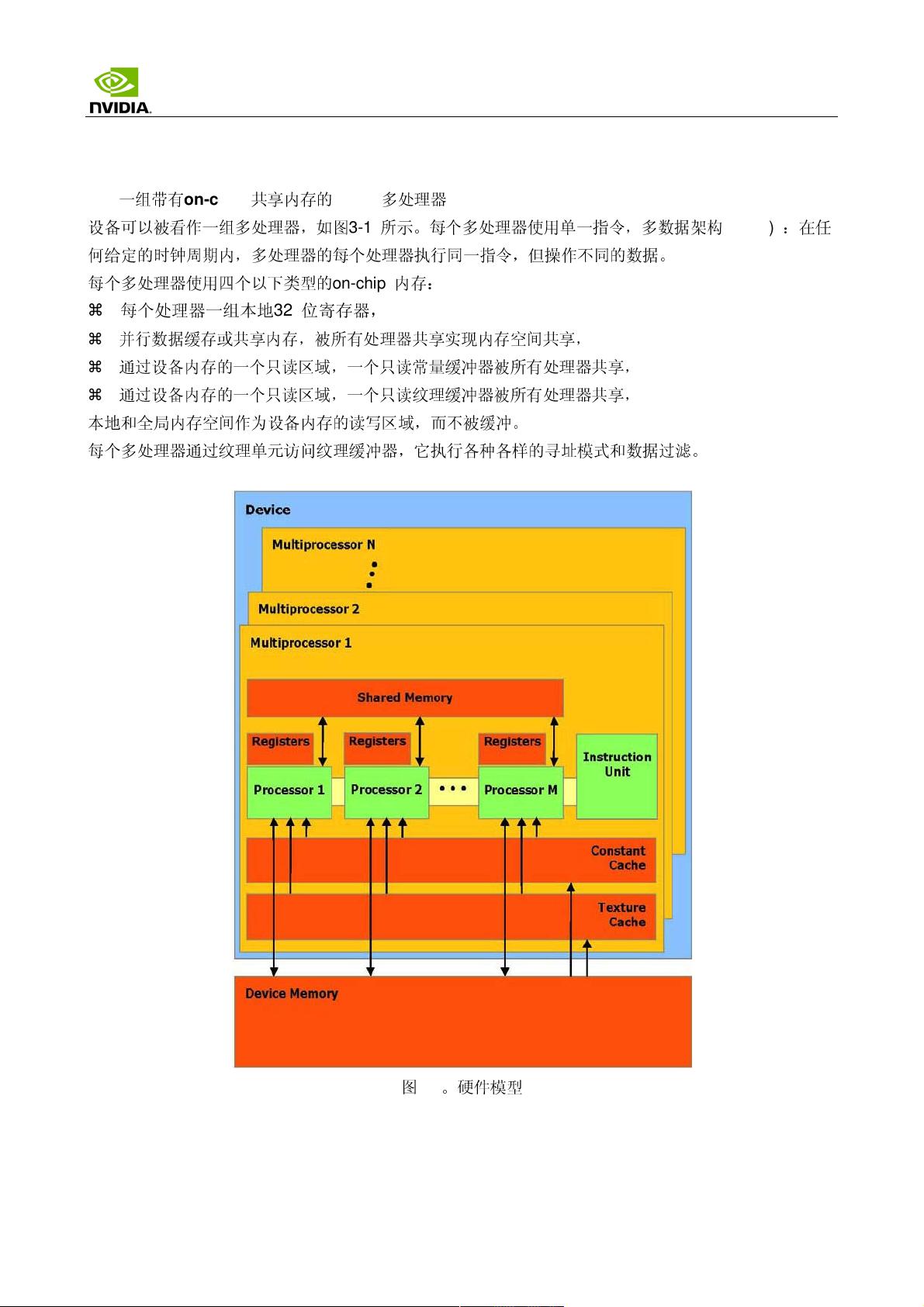
- **SIMD 多处理器**:GPU 内部包含多个流式多处理器(Streaming Multiprocessors),每个具有自己的缓存和执行单元,执行单指令多数据(SIMD)风格的并行运算。
- **执行模式**:CUDA GPU 可以根据任务的特性调整执行模式,如同步或异步执行,以优化效率。
- **计算兼容性**:不同的 GPU 有不同的计算兼容性等级,决定了它们能支持的 CUDA 版本和功能。
- **多设备**:CUDA 支持多 GPU 环境,可以在多个 GPU 之间分配计算任务。
- **模式切换**:可以切换 GPU 的工作模式,例如在图形渲染和计算之间切换。
4. **应用程序编程接口(API)**
- **C 语言扩展**:CUDA 提供了 C 语言的扩展,包括特殊的函数和变量类型限定符,以便于定义在 GPU 上执行的代码。
- **类型限定词**:如 `__device__` 定义设备端函数,`__global__` 定义可在 GPU 上全局执行的函数,`__host__` 表示主机端函数,以及 `__constant__` 和 `__shared__` 分别用于定义常量内存和共享内存变量。
- **执行配置**:通过 `<<<>>>` 运算符指定线程块和线程块栅格的大小,以及执行配置。
- **内置变量**:如 `gridDim`、`blockIdx`、`blockDim` 和 `threadIdx` 提供了对当前执行上下文的元数据访问,便于线程同步和通信。
- **NVCC 编译器**:CUDA 的编译器 NVCC 提供了如 `__noinline__` 和 `#pragma unroll` 等控制优化的指令。
- **公共 Runtime 组件**:CUDA 运行时库提供了内置的向量类型和函数,便于高效处理数组和其他数据结构。
通过 CUDA 编程,开发者可以利用 GPU 的并行计算能力,加速计算密集型应用,如物理模拟、图像处理、机器学习和深度学习等。不过,理解和掌握 CUDA 编程需要对并行计算原理和 GPU 架构有深入理解,同时也需要熟练使用 CUDA API 和相应的编程工具。

- 16 -
2.2.1
线程块
一个线程块是一个线程的批处理,它通过一
些快速
的共享内存有
效
地
分
享数据并
且
在制定的内存
访问中
同
步它
们
的执行。更准确地说,它可以在
Kernel
中
指定同步点,一个块
里
的线程被
挂起直
到它
们
所有都到
达
同步点。
每
条
线程是由它的线程
ID
所确定,
ID
是在块
之
内的线程编号。
根
据线程的
ID
可以
帮助
进行
复杂寻址
,
一个应用程序可以指定一个块作为一个
二维
或
三维
数组的任
意大小
,并
且
通过一个
2 -
或
3-
组件
索引
代
替来
指定每
条
线程。对于一个
大小
为
(
D
x
,
D
y
)
二维
块,线程的
索引
是
(
x
,
y
)
,这个线程
ID
是
(
x
+
y D
x
)
。而对于
一个
三维
的
大小
为
(
D
x
,
D
y
,
D
z
)
的块,这个线程的
索引
是
(
x
,
y
,
z
)
, 线程的
ID
是
(
x
+
y D
x
+
z D
x
D
y
)
。
2.2.2
线程块栅格
一个块可以
包含
的线程
最大
数量是有限的。
然
而,执行同一个
kernel
的块可以
合
成一批线程块的栅格,因
此通过单一
kernel
发
送
的
请求
的线程总数可以是非常
巨大
的。线程协作的
减少会造
成性能的
损失
,因为
来
自
同一个栅格的不同线程块
中
的线程
彼
此
之
不间能通
讯
和同步。这个模式
允许
kernel
用不同的并行能
力
有
效
地运行在
各种
设备上而不用
再
编译:一个设备可以序列地运行栅格的所有块,如
果
它有非常
少
的并行
特
性,或
者
并行地运行,如
果
它有
很
多的并行的
特
性,或
者
通常是
二者
的组
合
。
ٛ
.
每个块是由它的块ID 确定的,块的ID 是在栅格之内的块编号。根据块ID 可以帮助进行
复杂寻址,一个应用程序可也以指定一个栅格作为任意大小的一个二维数组,并且通过一个
2-组件索引替换来制定每个块。对于一个大小为 (
D
x
,
D
y
)
二维
块,这个块的索引是(
x
,
y
),
块的
ID 是(
x
+
y D
x
)
。


剩余135页未读,继续阅读
2019-03-29 上传
2010-02-02 上传
2023-05-30 上传
2023-06-10 上传
2023-11-14 上传
2023-09-08 上传
2023-05-20 上传
2024-05-29 上传

royweiluo
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建Cadence PSpice仿真模型库教程
- VMware 10.0安装指南:步骤详解与网络、文件共享解决方案
- 中国互联网20周年必读:影响行业的100本经典书籍
- SQL Server 2000 Analysis Services的经典MDX查询示例
- VC6.0 MFC操作Excel教程:亲测Win7下的应用与保存技巧
- 使用Python NetworkX处理网络图
- 科技驱动:计算机控制技术的革新与应用
- MF-1型机器人硬件与robobasic编程详解
- ADC性能指标解析:超越位数、SNR和谐波
- 通用示波器改造为逻辑分析仪:0-1字符显示与电路设计
- C++实现TCP控制台客户端
- SOA架构下ESB在卷烟厂的信息整合与决策支持
- 三维人脸识别:技术进展与应用解析
- 单张人脸图像的眼镜边框自动去除方法
- C语言绘制图形:余弦曲线与正弦函数示例
- Matlab 文件操作入门:fopen、fclose、fprintf、fscanf 等函数使用详解
