贪心科技的PLATO系列:大规模预训练对话生成模型
需积分: 35 132 浏览量
更新于2024-07-07
收藏 1.76MB PDF 举报
"baidu闲聊对话机器人plato 1 - xl"
本文将深入探讨百度的闲聊对话机器人Plato系列,包括PLATO、PLATO-2以及PLATO-XL,这些是百度在构建开放域聊天机器人领域的重要研究进展。这些模型致力于通过大规模预训练和课程学习来提升对话生成的质量和个性化。
1. PLATO: 预训练的离散潜变量对话生成模型
PLATO是百度开发的第一个对话生成模型,它拥有132M参数,并基于8M样本进行训练。然而,由于模型规模较小,存在训练不稳定性和效率问题。该模型利用Transformer架构,引入了预规范化和统一的前缀语言模型,以及离散潜变量,以实现开放域对话的一对多映射。
2. PLATO-2:通过课程学习构建开放域聊天机器人
为了解决PLATO的问题,PLATO-2进一步扩大了模型规模,拥有1.6B、314M和93M的不同参数量版本,以及684M的训练样本。课程学习的概念被引入,这是一种模仿人类学习过程的方法,先从简单任务开始,逐步过渡到更复杂的对话生成任务。这种方法有助于提高模型的对话质量和适应性。
3. PLATO-XL:探索大规模预训练对话生成
PLATO-XL是这一系列的最新成果,其参数量达到了110亿,用于英文的训练样本为811M,中文样本为1.2B。如此庞大的规模旨在探索大模型在对话生成上的潜力,进一步提升模型的泛化能力和上下文理解能力。
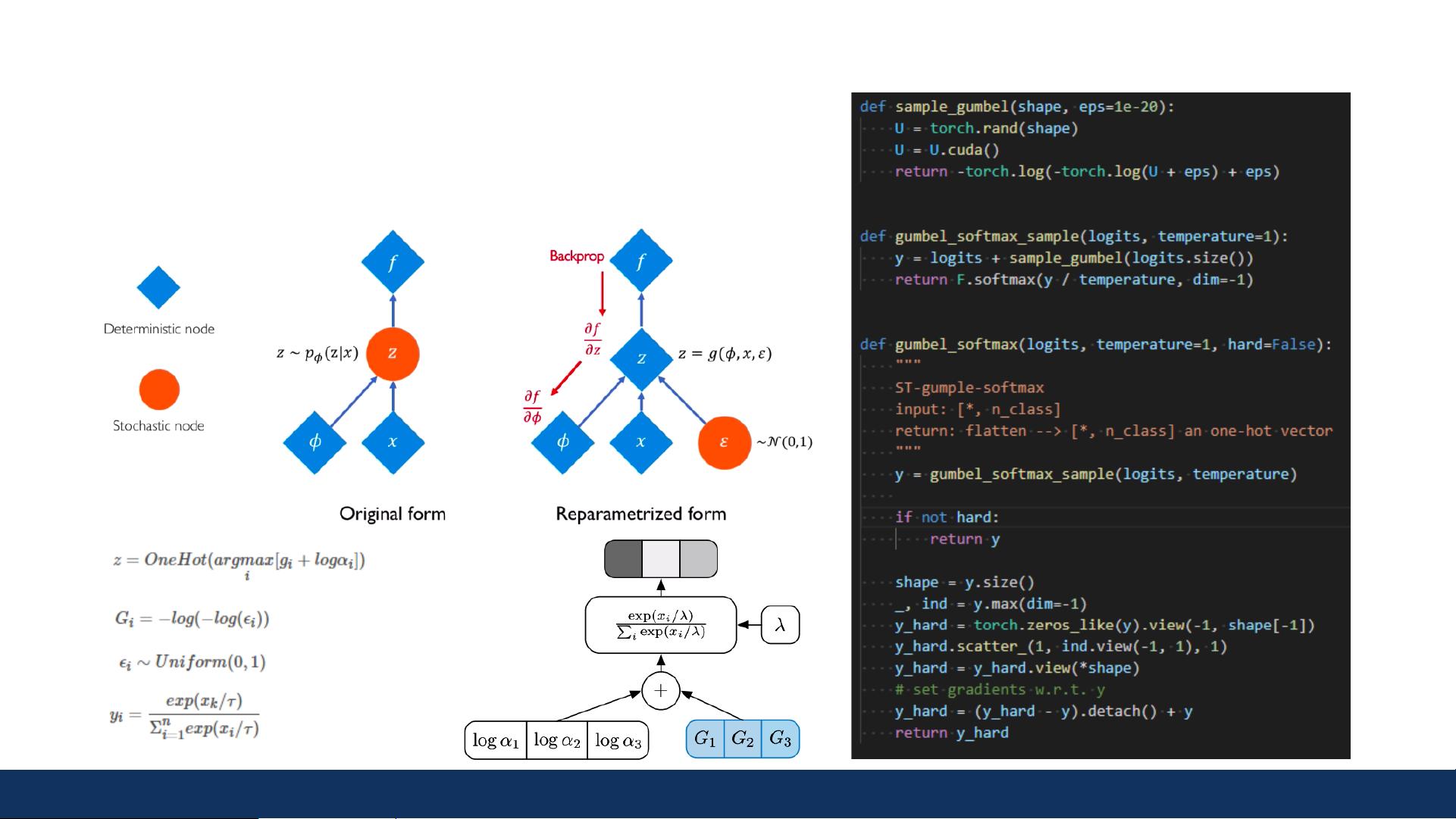
4. Gumbel-Softmax技巧
Gumbel-Softmax是一种在离散选择问题中模拟连续分布的技术,它在PLATO系列中被用来处理离散潜变量的采样问题。这个技巧使得模型能够在训练过程中进行端到端的优化,提高了模型的训练效率。
5. 课程学习
课程学习是PLATO-2和PLATO-XL中的关键策略,它将学习过程划分为一系列逐步增加难度的任务,从简单的对话场景开始,逐渐引导模型掌握更复杂、更自然的对话模式。这种策略有助于模型逐步适应不同层次的对话生成挑战。
6. 对话生成预训练
在PLATO系列中,模型不仅需要理解对话上下文,还需要生成合适的响应,同时识别潜在的行为。预训练任务包括响应生成和潜在行为识别,通过这些任务,模型可以学习如何在无监督的环境中生成连贯、有趣且具有个性化的对话。
总而言之,百度的PLATO系列模型展示了在构建智能闲聊对话机器人方面的创新和进步。从PLATO的小规模尝试,到PLATO-2的课程学习,再到PLATO-XL的大规模预训练,这一系列工作体现了对对话生成模型的深度理解和不断优化,为实现更加自然、个性化的开放域聊天体验奠定了坚实的基础。

贪心科技 | 让每个人享受个性化教育服务
Language Model
剩余25页未读,继续阅读
2021-05-01 上传
2021-04-05 上传
2021-06-27 上传
2021-02-03 上传
2021-05-21 上传
2023-03-09 上传

K5niper
- 粉丝: 93
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- MCP C#试用试题
- nutch初学入门 非常好的入门教程
- c#面试题 网络转载 不错 经典
- C#设计模式大全 好书
- Struts+Spring+Hibernate整合教程.pdf
- BP神经网络原理及仿真实例
- 使用简介POWERPLAY
- Oracle 9i10g编程艺术
- scm手把手开发文档
- Cognos Impromptu
- LoadRunner安装手册.pdf
- cognos 部署 文档
- 用C语言进行单片机程序设计与应用
- Direct3D.ShaderX.-.Vertex.and.Pixel.Shader.Tips.and.Tricks.pdf
- 《uVision2入门教程》.pdf
- spring1.2申明式事务.txt
