Yahoo的Hadoop与Spark集成策略:统一协作的力量
需积分: 16 196 浏览量
更新于2024-07-23
1
收藏 2.09MB PDF 举报
"Andy Feng在Spark Summit 2013上分享了雅虎如何通过Hadoop和Spark的统一协作来应对大数据处理的挑战。他强调这种协作是雅虎解决复杂业务问题的关键。"
在2013年的Spark Summit上,雅虎的高级架构师Andy Feng提出了一个重要的观点——Hadoop和Spark的集成是雅虎应对大数据挑战的重要策略。当时,雅虎正面临着如何为用户提供个性化体验,特别是在其主页、财经频道和移动应用上。这些服务需要处理大量的实时和历史数据,以实现个性化推荐和改进的网络搜索功能。
Hadoop作为大数据处理的基石,擅长于批处理和离线分析大规模数据,而Spark则以其高速的内存计算能力,支持实时数据处理和迭代算法。在雅虎的场景中,Hadoop用于处理和存储海量的历史数据,而Spark则在需要快速响应和实时分析的场景下发挥作用,如点击率预测(CTR)和个性化推荐。
Andy Feng提出的一个主要挑战是构建一个适用于主页流中所有项目的一体化模型。这涉及到了数百万个项目,每个项目有上千个特征,涵盖了用户行为、内容分类、实体名称等多元数据。目标函数需要平衡相关性、用户参与度、新鲜度和流行度,同时进行算法探索,包括逻辑回归、协同过滤、决策树和混合模型等。
另一个挑战在于速度。例如,雅虎主页的今日模块需要对短期事件和突发新闻做出快速反应。传统的Hadoop可能无法满足这种实时性的需求,而Spark的快速计算能力恰好可以解决这个问题,通过快速训练和更新模型以适应短暂生命周期和时间效应的数据。
Hadoop和Spark的结合在雅虎的大数据战略中扮演了关键角色。它们互补各自的优点,Hadoop提供大数据存储和批量处理能力,Spark则提供了快速的实时分析和机器学习能力,共同推动了雅虎在大数据时代的创新和服务优化。这一策略对于其他也在大数据领域探索的企业来说,具有重要的参考价值。
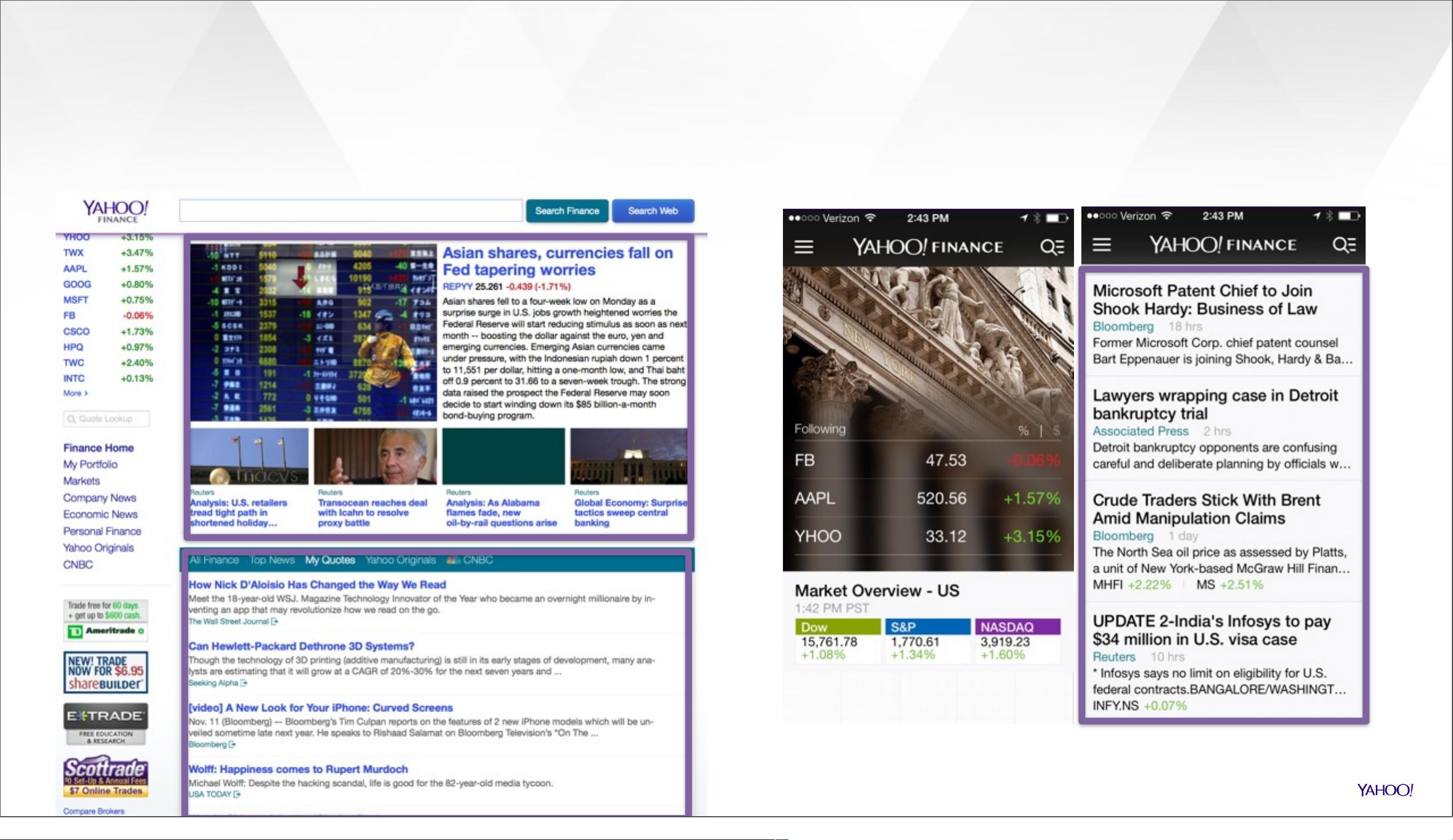
YAHOO 2013: PERSONALIZED PROPERTIES
http://finance.yahoo.com
Mobile
4
Monday, December 2, 13
剩余18页未读,继续阅读
2015-05-07 上传
2021-03-06 上传
2021-04-07 上传
2017-12-06 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

villa123
- 粉丝: 418
- 资源: 236
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握压缩文件管理:2工作.zip文件使用指南
- 易语言动态版置入代码技术解析
- C语言编程实现电脑系统测试工具开发
- Wireshark 64位:全面网络协议分析器,支持Unix和Windows
- QtSingleApplication: 确保单一实例运行的高效库
- 深入了解Go语言的解析器组合器PARC
- Apycula包安装与使用指南
- AkerAutoSetup安装包使用指南
- Arduino Due实现VR耳机的设计与编程
- DependencySwizzler: Xamarin iOS 库实现故事板 UIViewControllers 依赖注入
- Apycula包发布说明与下载指南
- 创建可拖动交互式图表界面的ampersand-touch-charts
- CMake项目入门:创建简单的C++项目
- AksharaJaana-*.*.*.*安装包说明与下载
- Arduino天气时钟项目:源代码及DHT22库文件解析
- MediaPlayer_server:控制媒体播放器的高级服务器
