大数据技术实验:Hadoop与Spark实践
需积分: 24 149 浏览量
更新于2024-06-30
1
收藏 38.05MB PDF 举报
"该实验文档主要探讨大数据技术在Hadoop和Spark平台上的应用,涵盖了分布式平台的搭建、Hadoop和Spark的安装、MapReduce实验以及Spark的基本操作。实验内容包括HDFS的使用、HBase数据库的安装配置及操作、MapReduce编程以及Spark的环境配置和RDD操作。"
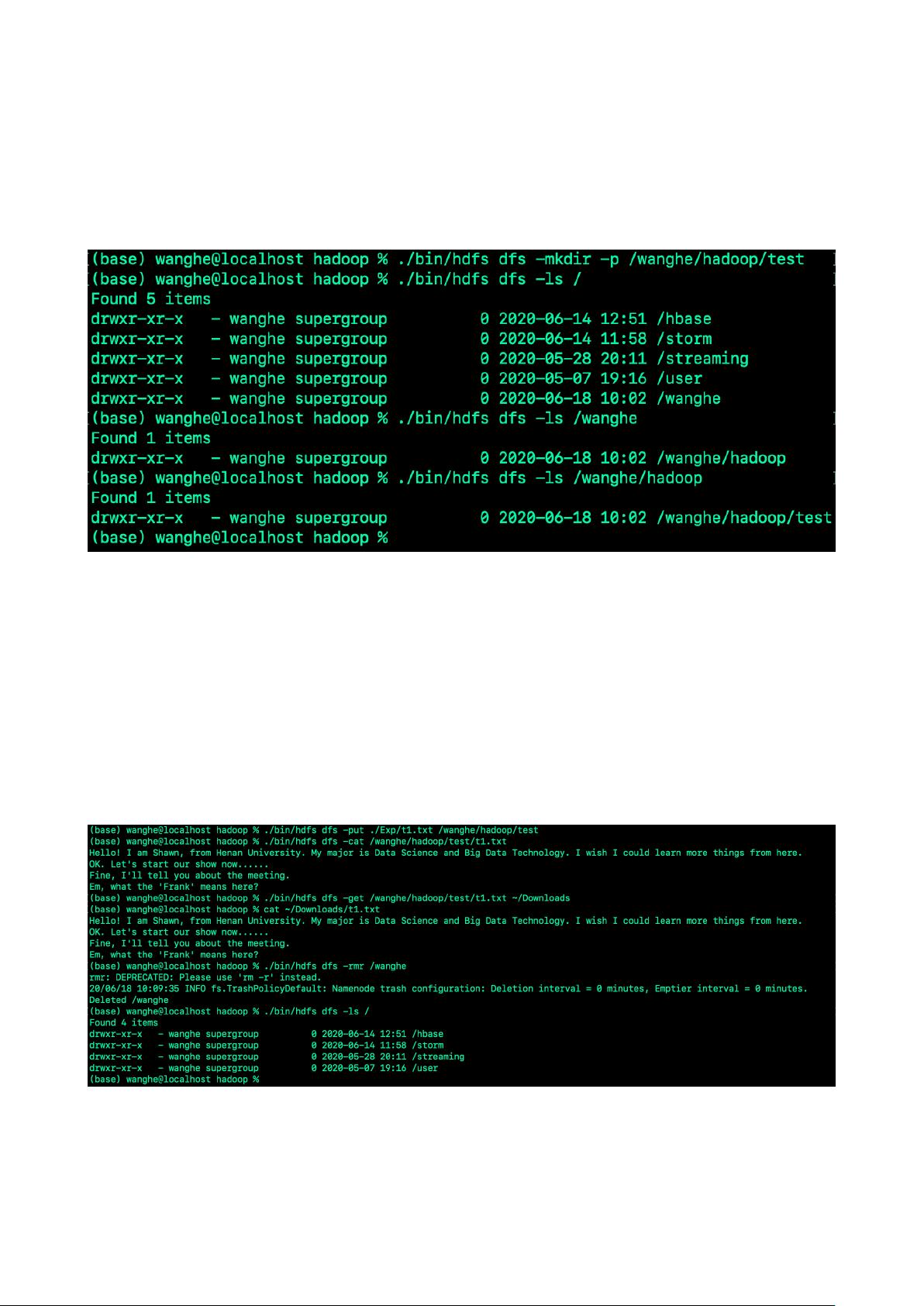
在大数据技术领域,Hadoop和Spark是两个核心的计算框架。Hadoop是Apache基金会开发的开源项目,主要由HDFS(Hadoop Distributed File System)和MapReduce两部分组成,用于处理和存储海量数据。在实验中,首先介绍了Hadoop的项目,包括HDFS的环境配置,如Java环境的设置和SSH远程登录的配置,以及Hadoop的单机安装和伪分布式搭建。HDFS的基本操作包括创建目录、查看目录信息、上传和下载文件、删除目录等。此外,还涉及了HDFS的编程操作,如判断文件是否存在、实现ls和cat命令等。
HBase是一个分布式、列式存储的NoSQL数据库,它构建在HDFS之上,适合实时读取大数据。实验中详细讲述了HBase的安装、配置、数据库Shell操作以及可能出现的问题。同时,还介绍了Phoenix组件的安装、配置和操作,Phoenix是一个基于HBase的SQL查询层,提供高性能的SQL查询功能。
MapReduce是Hadoop的核心计算模型,实验中通过WordCount和数据排序等例子展示了MapReduce的编程实践。MapReduce将大任务分解为小任务并行处理,然后合并结果,适合批处理任务。
Spark是另一种大数据处理框架,以其快速、通用和可扩展性而闻名。实验内容涉及Spark的环境配置,包括安装、环境变量配置和伪分布式设置。Spark的核心概念是Resilient Distributed Datasets (RDD),它是数据的分布式集合,提供了各种操作,如转换和行动。实验中演示了如何通过Spark命令行进行RDD的基本操作,如加载文本文件。
这个实验文档全面地介绍了大数据技术的基础知识和实际操作,对于学习和理解大数据处理流程及其工具非常有帮助。通过这些实验,学生可以深入理解Hadoop和Spark的工作原理,并具备实际操作分布式系统的技能。
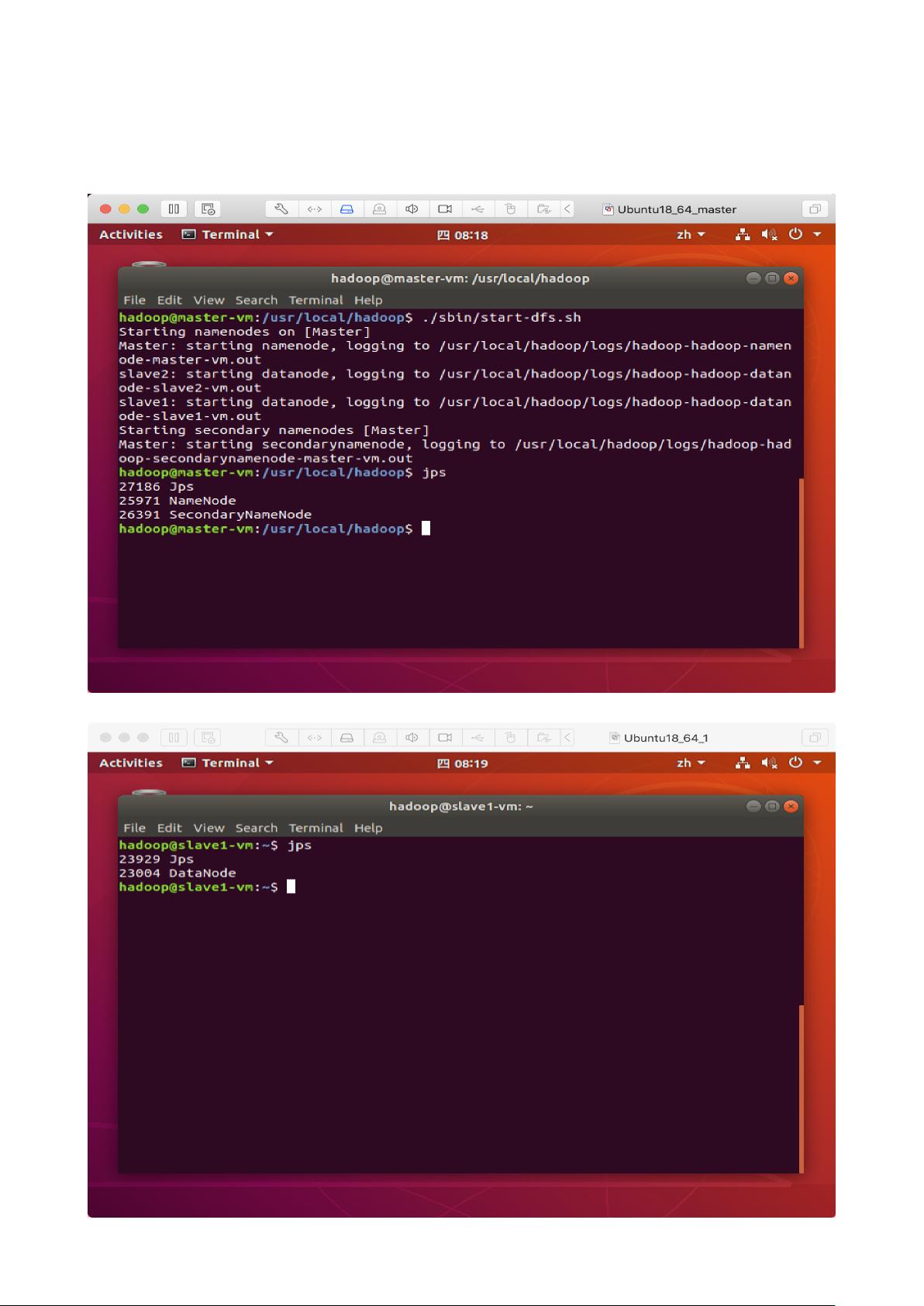
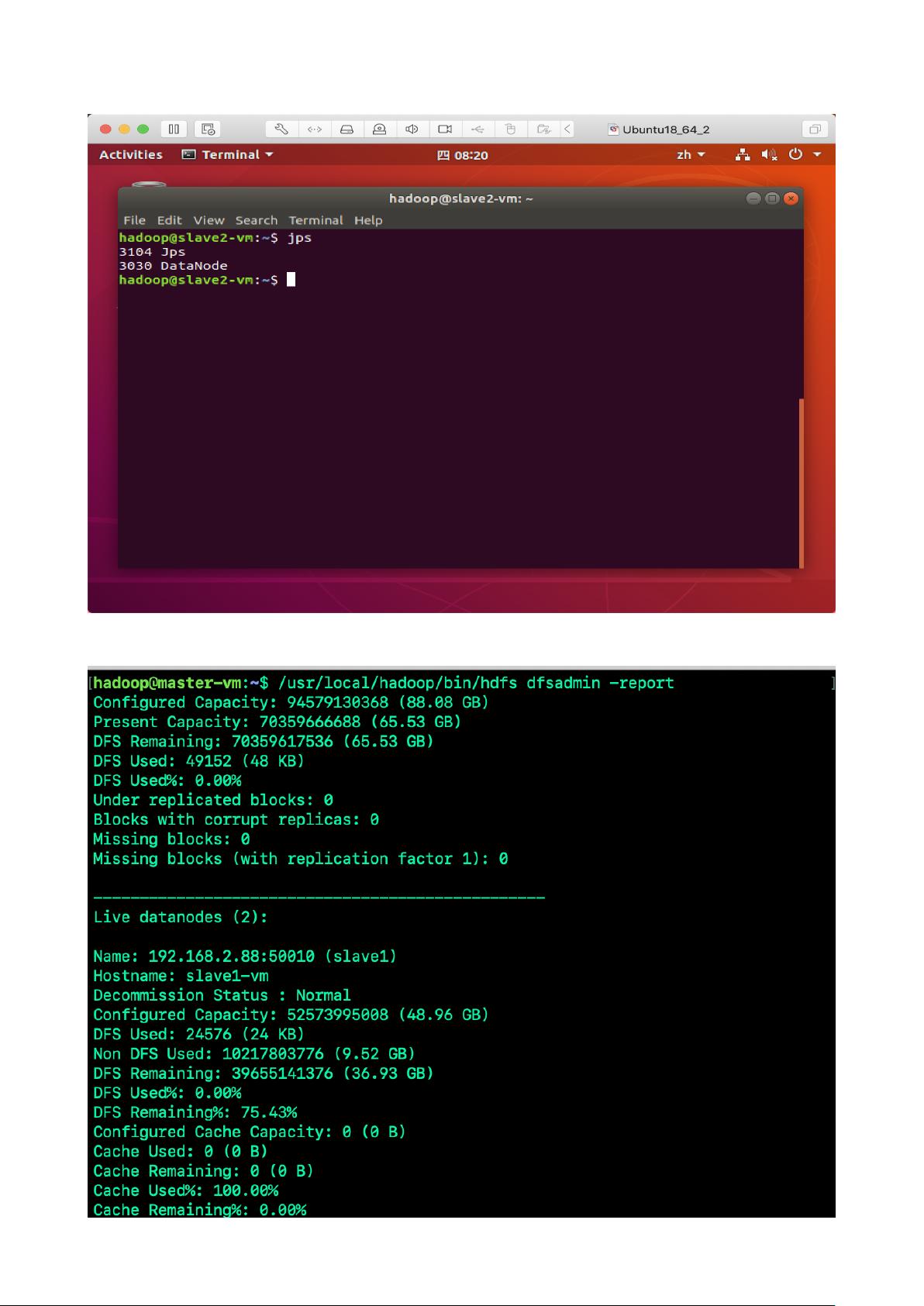
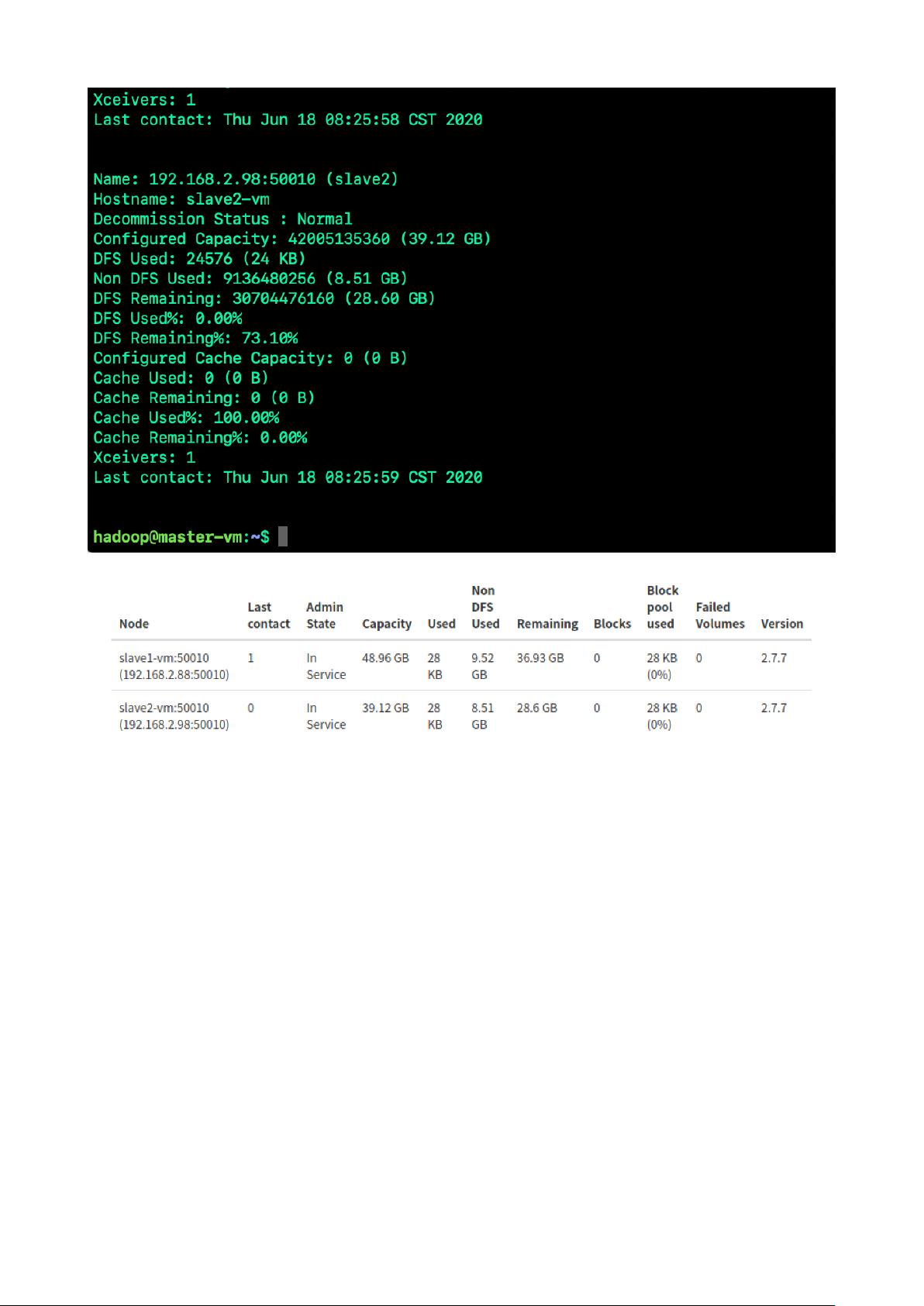
3. 启动分布式集群
启动分布式集群只需要在宿主机上完成即可。启动命令与伪分布式启动命令⼀致。启动后,
集群个结点查看运⾏进程如图所示:
宿主机进程信息:
结点slave1进程信息:
13
剩余78页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-12-07 上传
2024-04-14 上传
2024-04-09 上传
2021-09-21 上传
2024-01-16 上传
2022-06-18 上传

Shawn·D·W
- 粉丝: 11
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- The Next 700 Programming Languages
- 2009年上半年信息系统监理师上午题。
- 2009年上半年信息处理技术员上午题
- AT&T asm guide for newbie
- DSP开发板电路原理图之主图
- 管理软件的实施与销售
- The estimation of synergy or antagonism
- Measuring additive interaction using odds ratios
- 数据库课程设计126个经典题
- 【启动项目就是开机的时候系统会在前台或者后台运行的程序】
- 云母填充改性聚乙烯的初步研究
- 某高校学生学籍管理信息系统设计与开发
- 编程相关日语词汇(PDF格式)
- Ubuntu中文参考手册
- 计算机网络 第四版 习题答案 谢希仁
- J2ME手机游戏开发技术详解
